 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManual-PA: Learning 3D Part Assembly from Instruction Diagrams
Nov 27, 2024



Assembling furniture amounts to solving the discrete-continuous optimization task of selecting the furniture parts to assemble and estimating their connecting poses in a physically realistic manner. The problem is hampered by its combinatorially large yet sparse solution space thus making learning to assemble a challenging task for current machine learning models. In this paper, we attempt to solve this task by leveraging the assembly instructions provided in diagrammatic manuals that typically accompany the furniture parts. Our key insight is to use the cues in these diagrams to split the problem into discrete and continuous phases. Specifically, we present Manual-PA, a transformer-based instruction Manual-guided 3D Part Assembly framework that learns to semantically align 3D parts with their illustrations in the manuals using a contrastive learning backbone towards predicting the assembly order and infers the 6D pose of each part via relating it to the final furniture depicted in the manual. To validate the efficacy of our method, we conduct experiments on the benchmark PartNet dataset. Our results show that using the diagrams and the order of the parts lead to significant improvements in assembly performance against the state of the art. Further, Manual-PA demonstrates strong generalization to real-world IKEA furniture assembly on the IKEA-Manual dataset.
Temporally Grounding Instructional Diagrams in Unconstrained Videos
Jul 16, 2024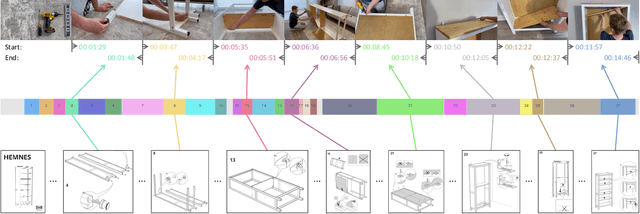
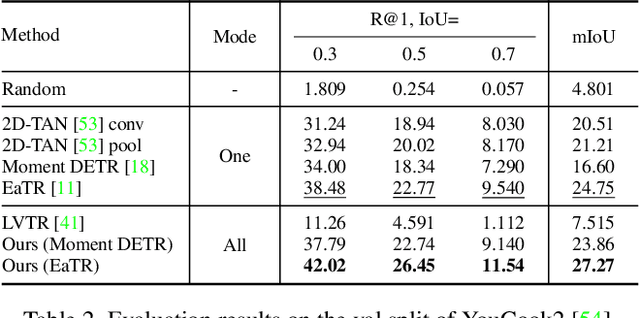
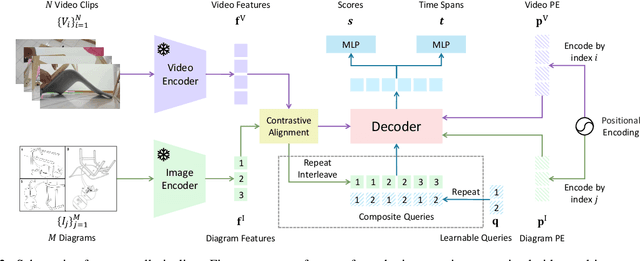
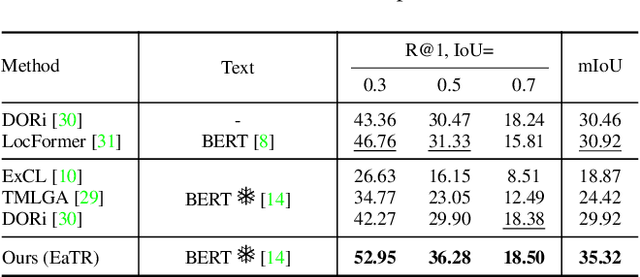
We study the challenging problem of simultaneously localizing a sequence of queries in the form of instructional diagrams in a video. This requires understanding not only the individual queries but also their interrelationships. However, most existing methods focus on grounding one query at a time, ignoring the inherent structures among queries such as the general mutual exclusiveness and the temporal order. Consequently, the predicted timespans of different step diagrams may overlap considerably or violate the temporal order, thus harming the accuracy. In this paper, we tackle this issue by simultaneously grounding a sequence of step diagrams. Specifically, we propose composite queries, constructed by exhaustively pairing up the visual content features of the step diagrams and a fixed number of learnable positional embeddings. Our insight is that self-attention among composite queries carrying different content features suppress each other to reduce timespan overlaps in predictions, while the cross-attention corrects the temporal misalignment via content and position joint guidance. We demonstrate the effectiveness of our approach on the IAW dataset for grounding step diagrams and the YouCook2 benchmark for grounding natural language queries, significantly outperforming existing methods while simultaneously grounding multiple queries.
MAVIS: Multi-Camera Augmented Visual-Inertial SLAM using SE2(3) Based Exact IMU Pre-integration
Sep 18, 2023



We present a novel optimization-based Visual-Inertial SLAM system designed for multiple partially overlapped camera systems, named MAVIS. Our framework fully exploits the benefits of wide field-of-view from multi-camera systems, and the metric scale measurements provided by an inertial measurement unit (IMU). We introduce an improved IMU pre-integration formulation based on the exponential function of an automorphism of SE_2(3), which can effectively enhance tracking performance under fast rotational motion and extended integration time. Furthermore, we extend conventional front-end tracking and back-end optimization module designed for monocular or stereo setup towards multi-camera systems, and introduce implementation details that contribute to the performance of our system in challenging scenarios. The practical validity of our approach is supported by our experiments on public datasets. Our MAVIS won the first place in all the vision-IMU tracks (single and multi-session SLAM) on Hilti SLAM Challenge 2023 with 1.7 times the score compared to the second place.
Aligning Step-by-Step Instructional Diagrams to Video Demonstrations
Mar 27, 2023Multimodal alignment facilitates the retrieval of instances from one modality when queried using another. In this paper, we consider a novel setting where such an alignment is between (i) instruction steps that are depicted as assembly diagrams (commonly seen in Ikea assembly manuals) and (ii) video segments from in-the-wild videos; these videos comprising an enactment of the assembly actions in the real world. To learn this alignment, we introduce a novel supervised contrastive learning method that learns to align videos with the subtle details in the assembly diagrams, guided by a set of novel losses. To study this problem and demonstrate the effectiveness of our method, we introduce a novel dataset: IAW for Ikea assembly in the wild consisting of 183 hours of videos from diverse furniture assembly collections and nearly 8,300 illustrations from their associated instruction manuals and annotated for their ground truth alignments. We define two tasks on this dataset: First, nearest neighbor retrieval between video segments and illustrations, and, second, alignment of instruction steps and the segments for each video. Extensive experiments on IAW demonstrate superior performances of our approach against alternatives.
Action Anticipation By Predicting Future Dynamic Images
Aug 01, 2018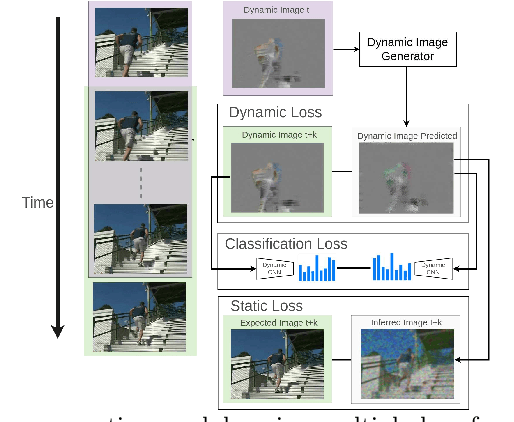

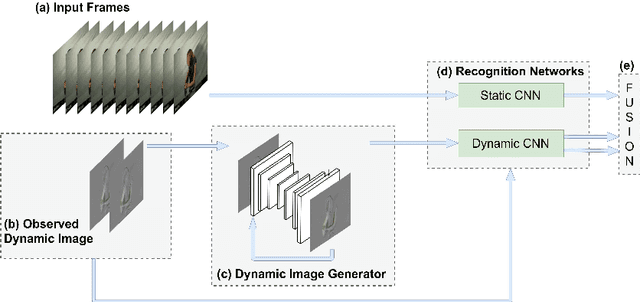
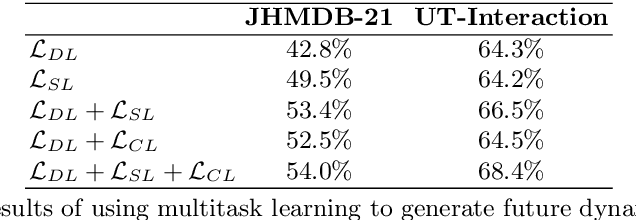
Human action-anticipation methods predict what is the future action by observing only a few portion of an action in progress. This is critical for applications where computers have to react to human actions as early as possible such as autonomous driving, human-robotic interaction, assistive robotics among others. In this paper, we present a method for human action anticipation by predicting the most plausible future human motion. We represent human motion using Dynamic Images and make use of tailored loss functions to encourage a generative model to produce accurate future motion prediction. Our method outperforms the currently best performing action-anticipation methods by 4% on JHMDB-21, 5.2% on UT-Interaction and 5.1% on UCF 101-24 benchmarks.