 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Anticipation By Predicting Future Dynamic Images
Paper and Code
Aug 01, 2018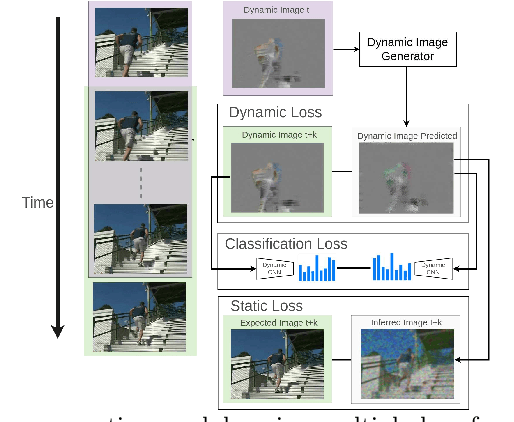

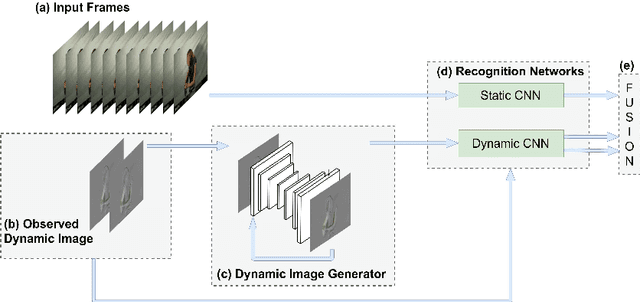
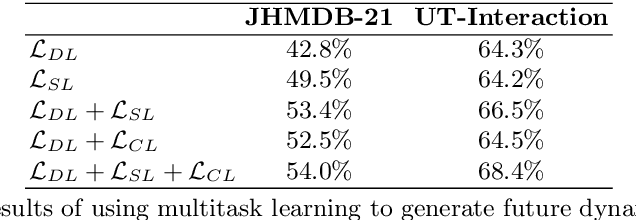
Human action-anticipation methods predict what is the future action by observing only a few portion of an action in progress. This is critical for applications where computers have to react to human actions as early as possible such as autonomous driving, human-robotic interaction, assistive robotics among others. In this paper, we present a method for human action anticipation by predicting the most plausible future human motion. We represent human motion using Dynamic Images and make use of tailored loss functions to encourage a generative model to produce accurate future motion prediction. Our method outperforms the currently best performing action-anticipation methods by 4% on JHMDB-21, 5.2% on UT-Interaction and 5.1% on UCF 101-24 benchmarks.