 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVI3NR: Variance Informed Initialization for Implicit Neural Representations
Apr 27, 2025



Implicit Neural Representations (INRs) are a versatile and powerful tool for encoding various forms of data, including images, videos, sound, and 3D shapes. A critical factor in the success of INRs is the initialization of the network, which can significantly impact the convergence and accuracy of the learned model. Unfortunately, commonly used neural network initializations are not widely applicable for many activation functions, especially those used by INRs. In this paper, we improve upon previous initialization methods by deriving an initialization that has stable variance across layers, and applies to any activation function. We show that this generalizes many previous initialization methods, and has even better stability for well studied activations. We also show that our initialization leads to improved results with INR activation functions in multiple signal modalities. Our approach is particularly effective for Gaussian INRs, where we demonstrate that the theory of our initialization matches with task performance in multiple experiments, allowing us to achieve improvements in image, audio, and 3D surface reconstruction.
StyleMotif: Multi-Modal Motion Stylization using Style-Content Cross Fusion
Mar 27, 2025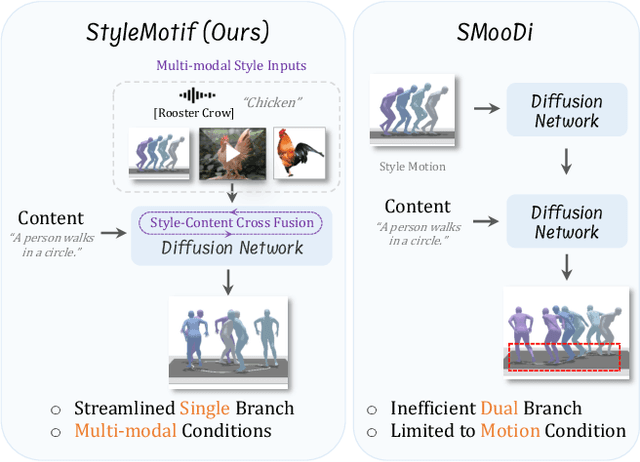
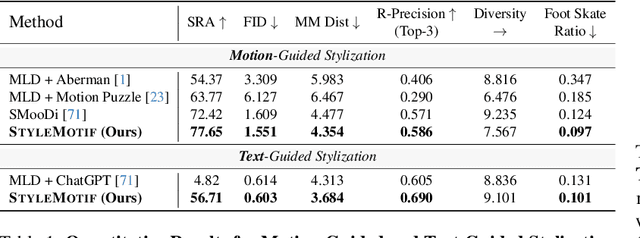
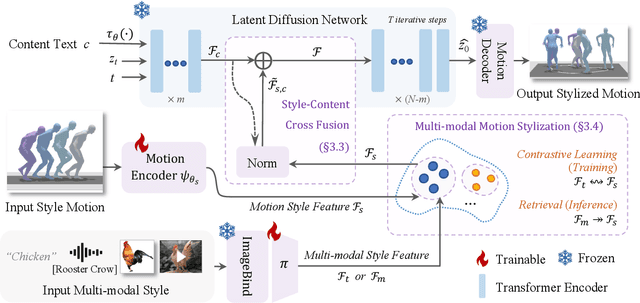
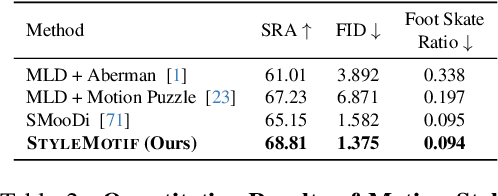
We present StyleMotif, a novel Stylized Motion Latent Diffusion model, generating motion conditioned on both content and style from multiple modalities. Unlike existing approaches that either focus on generating diverse motion content or transferring style from sequences, StyleMotif seamlessly synthesizes motion across a wide range of content while incorporating stylistic cues from multi-modal inputs, including motion, text, image, video, and audio. To achieve this, we introduce a style-content cross fusion mechanism and align a style encoder with a pre-trained multi-modal model, ensuring that the generated motion accurately captures the reference style while preserving realism. Extensive experiments demonstrate that our framework surpasses existing methods in stylized motion generation and exhibits emergent capabilities for multi-modal motion stylization, enabling more nuanced motion synthesis. Source code and pre-trained models will be released upon acceptance. Project Page: https://stylemotif.github.io
Less is More: Improving Motion Diffusion Models with Sparse Keyframes
Mar 18, 2025Recent advances in motion diffusion models have led to remarkable progress in diverse motion generation tasks, including text-to-motion synthesis. However, existing approaches represent motions as dense frame sequences, requiring the model to process redundant or less informative frames. The processing of dense animation frames imposes significant training complexity, especially when learning intricate distributions of large motion datasets even with modern neural architectures. This severely limits the performance of generative motion models for downstream tasks. Inspired by professional animators who mainly focus on sparse keyframes, we propose a novel diffusion framework explicitly designed around sparse and geometrically meaningful keyframes. Our method reduces computation by masking non-keyframes and efficiently interpolating missing frames. We dynamically refine the keyframe mask during inference to prioritize informative frames in later diffusion steps. Extensive experiments show that our approach consistently outperforms state-of-the-art methods in text alignment and motion realism, while also effectively maintaining high performance at significantly fewer diffusion steps. We further validate the robustness of our framework by using it as a generative prior and adapting it to different downstream tasks. Source code and pre-trained models will be released upon acceptance.
Neural Experts: Mixture of Experts for Implicit Neural Representations
Oct 29, 2024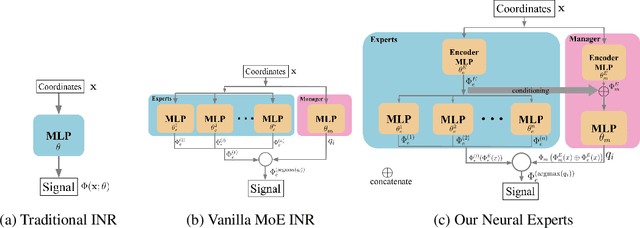
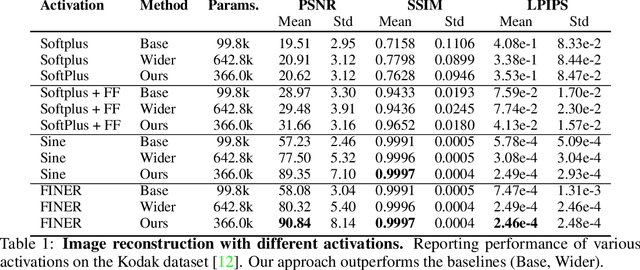
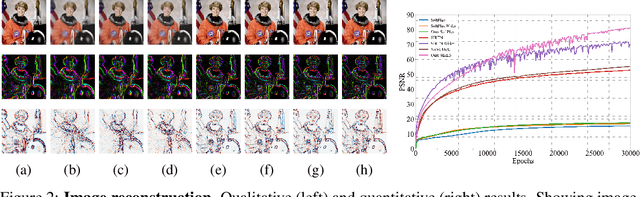
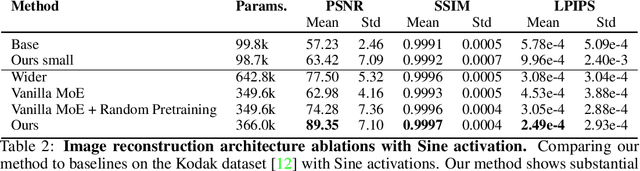
Implicit neural representations (INRs) have proven effective in various tasks including image, shape, audio, and video reconstruction. These INRs typically learn the implicit field from sampled input points. This is often done using a single network for the entire domain, imposing many global constraints on a single function. In this paper, we propose a mixture of experts (MoE) implicit neural representation approach that enables learning local piece-wise continuous functions that simultaneously learns to subdivide the domain and fit locally. We show that incorporating a mixture of experts architecture into existing INR formulations provides a boost in speed, accuracy, and memory requirements. Additionally, we introduce novel conditioning and pretraining methods for the gating network that improves convergence to the desired solution. We evaluate the effectiveness of our approach on multiple reconstruction tasks, including surface reconstruction, image reconstruction, and audio signal reconstruction and show improved performance compared to non-MoE methods.
Temporally Grounding Instructional Diagrams in Unconstrained Videos
Jul 16, 2024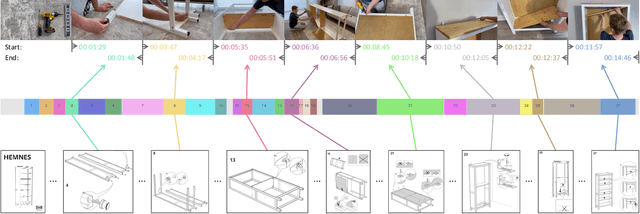
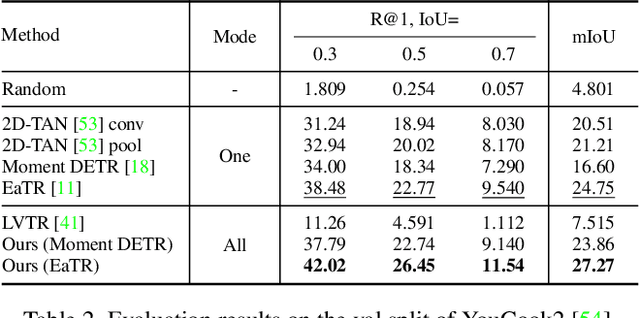
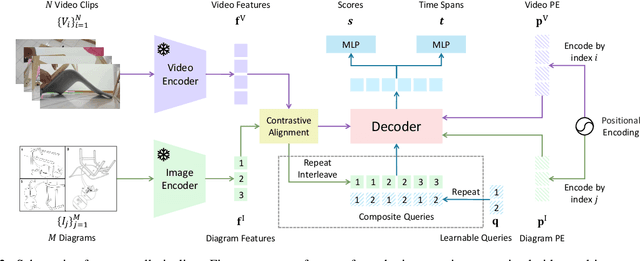
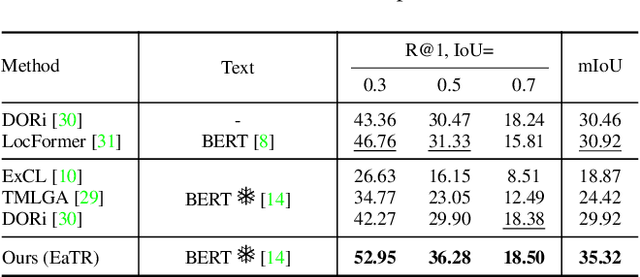
We study the challenging problem of simultaneously localizing a sequence of queries in the form of instructional diagrams in a video. This requires understanding not only the individual queries but also their interrelationships. However, most existing methods focus on grounding one query at a time, ignoring the inherent structures among queries such as the general mutual exclusiveness and the temporal order. Consequently, the predicted timespans of different step diagrams may overlap considerably or violate the temporal order, thus harming the accuracy. In this paper, we tackle this issue by simultaneously grounding a sequence of step diagrams. Specifically, we propose composite queries, constructed by exhaustively pairing up the visual content features of the step diagrams and a fixed number of learnable positional embeddings. Our insight is that self-attention among composite queries carrying different content features suppress each other to reduce timespan overlaps in predictions, while the cross-attention corrects the temporal misalignment via content and position joint guidance. We demonstrate the effectiveness of our approach on the IAW dataset for grounding step diagrams and the YouCook2 benchmark for grounding natural language queries, significantly outperforming existing methods while simultaneously grounding multiple queries.
PatchContrast: Self-Supervised Pre-training for 3D Object Detection
Aug 14, 2023



Accurately detecting objects in the environment is a key challenge for autonomous vehicles. However, obtaining annotated data for detection is expensive and time-consuming. We introduce PatchContrast, a novel self-supervised point cloud pre-training framework for 3D object detection. We propose to utilize two levels of abstraction to learn discriminative representation from unlabeled data: proposal-level and patch-level. The proposal-level aims at localizing objects in relation to their surroundings, whereas the patch-level adds information about the internal connections between the object's components, hence distinguishing between different objects based on their individual components. We demonstrate how these levels can be integrated into self-supervised pre-training for various backbones to enhance the downstream 3D detection task. We show that our method outperforms existing state-of-the-art models on three commonly-used 3D detection datasets.
GoferBot: A Visual Guided Human-Robot Collaborative Assembly System
Apr 18, 2023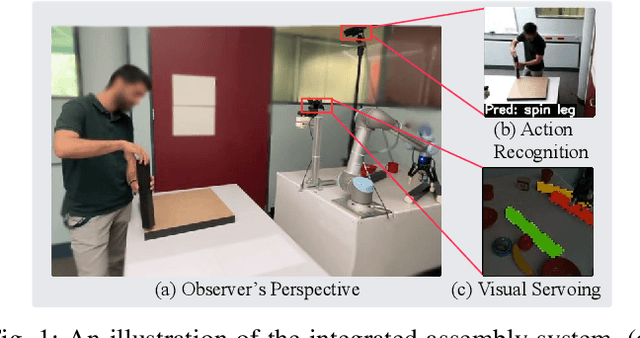
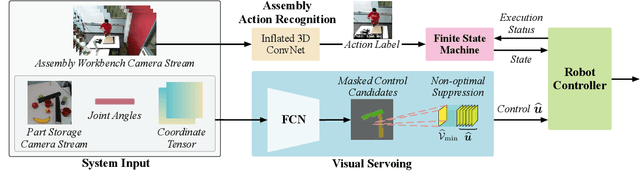
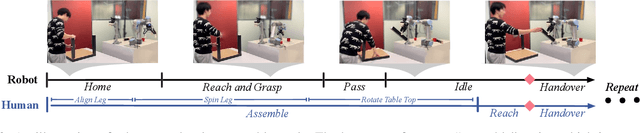
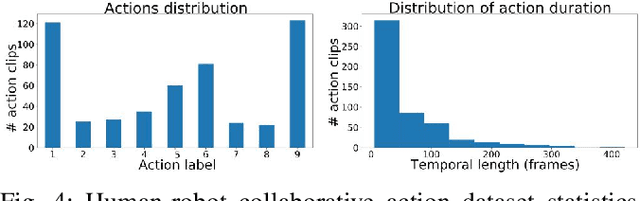
The current transformation towards smart manufacturing has led to a growing demand for human-robot collaboration (HRC) in the manufacturing process. Perceiving and understanding the human co-worker's behaviour introduces challenges for collaborative robots to efficiently and effectively perform tasks in unstructured and dynamic environments. Integrating recent data-driven machine vision capabilities into HRC systems is a logical next step in addressing these challenges. However, in these cases, off-the-shelf components struggle due to generalisation limitations. Real-world evaluation is required in order to fully appreciate the maturity and robustness of these approaches. Furthermore, understanding the pure-vision aspects is a crucial first step before combining multiple modalities in order to understand the limitations. In this paper, we propose GoferBot, a novel vision-based semantic HRC system for a real-world assembly task. It is composed of a visual servoing module that reaches and grasps assembly parts in an unstructured multi-instance and dynamic environment, an action recognition module that performs human action prediction for implicit communication, and a visual handover module that uses the perceptual understanding of human behaviour to produce an intuitive and efficient collaborative assembly experience. GoferBot is a novel assembly system that seamlessly integrates all sub-modules by utilising implicit semantic information purely from visual perception.
Aligning Step-by-Step Instructional Diagrams to Video Demonstrations
Mar 27, 2023Multimodal alignment facilitates the retrieval of instances from one modality when queried using another. In this paper, we consider a novel setting where such an alignment is between (i) instruction steps that are depicted as assembly diagrams (commonly seen in Ikea assembly manuals) and (ii) video segments from in-the-wild videos; these videos comprising an enactment of the assembly actions in the real world. To learn this alignment, we introduce a novel supervised contrastive learning method that learns to align videos with the subtle details in the assembly diagrams, guided by a set of novel losses. To study this problem and demonstrate the effectiveness of our method, we introduce a novel dataset: IAW for Ikea assembly in the wild consisting of 183 hours of videos from diverse furniture assembly collections and nearly 8,300 illustrations from their associated instruction manuals and annotated for their ground truth alignments. We define two tasks on this dataset: First, nearest neighbor retrieval between video segments and illustrations, and, second, alignment of instruction steps and the segments for each video. Extensive experiments on IAW demonstrate superior performances of our approach against alternatives.
3DInAction: Understanding Human Actions in 3D Point Clouds
Mar 11, 2023



We propose a novel method for 3D point cloud action recognition. Understanding human actions in RGB videos has been widely studied in recent years, however, its 3D point cloud counterpart remains under-explored. This is mostly due to the inherent limitation of the point cloud data modality -- lack of structure, permutation invariance, and varying number of points -- which makes it difficult to learn a spatio-temporal representation. To address this limitation, we propose the 3DinAction pipeline that first estimates patches moving in time (t-patches) as a key building block, alongside a hierarchical architecture that learns an informative spatio-temporal representation. We show that our method achieves improved performance on existing datasets, including DFAUST and IKEA ASM.
GraVoS: Gradient based Voxel Selection for 3D Detection
Aug 18, 2022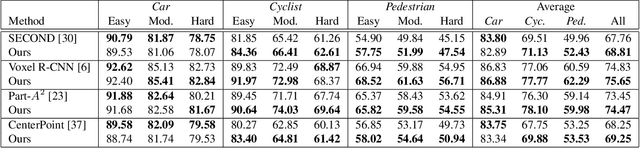

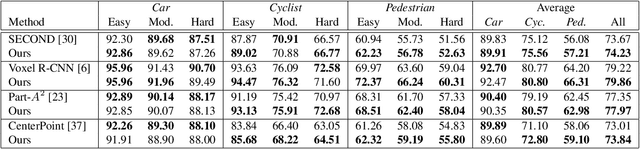
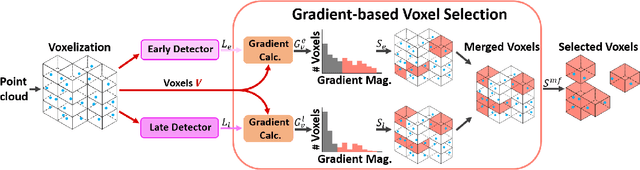
3D object detection within large 3D scenes is challenging not only due to the sparse and irregular 3D point clouds, but also due to the extreme foreground-background imbalance in the scene and class imbalance. A common approach is to add ground-truth objects from other scenes. Differently, we propose to modify the scenes by removing elements (voxels), rather than adding ones. Our approach selects the "meaningful" voxels, in a manner that addresses both types dataset imbalance. The approach is general and can be applied to any voxel-based detector, yet the meaningfulness of a voxel is network-dependent. Our voxel selection is shown to improve the performance of several prominent 3D detection methods.