 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMME: Mixture of Mesh Experts with Random Walk Transformer Gating
Feb 28, 2026In recent years, various methods have been proposed for mesh analysis, each offering distinct advantages and often excelling on different object classes. We present a novel Mixture of Experts (MoE) framework designed to harness the complementary strengths of these diverse approaches. We propose a new gate architecture that encourages each expert to specialise in the classes it excels in. Our design is guided by two key ideas: (1) random walks over the mesh surface effectively capture the regions that individual experts attend to, and (2) an attention mechanism that enables the gate to focus on the areas most informative for each expert's decision-making. To further enhance performance, we introduce a dynamic loss balancing scheme that adjusts a trade-off between diversity and similarity losses throughout the training, where diversity prompts expert specialization, and similarity enables knowledge sharing among the experts. Our framework achieves state-of-the-art results in mesh classification, retrieval, and semantic segmentation tasks. Our code is available at: https://github.com/amirbelder/MME-Mixture-of-Mesh-Experts.
VALD: Multi-Stage Vision Attack Detection for Efficient LVLM Defense
Feb 23, 2026Large Vision-Language Models (LVLMs) can be vulnerable to adversarial images that subtly bias their outputs toward plausible yet incorrect responses. We introduce a general, efficient, and training-free defense that combines image transformations with agentic data consolidation to recover correct model behavior. A key component of our approach is a two-stage detection mechanism that quickly filters out the majority of clean inputs. We first assess image consistency under content-preserving transformations at negligible computational cost. For more challenging cases, we examine discrepancies in a text-embedding space. Only when necessary do we invoke a powerful LLM to resolve attack-induced divergences. A key idea is to consolidate multiple responses, leveraging both their similarities and their differences. We show that our method achieves state-of-the-art accuracy while maintaining notable efficiency: most clean images skip costly processing, and even in the presence of numerous adversarial examples, the overhead remains minimal.
Concept Retrieval -- What and How?
Oct 08, 2025A concept may reflect either a concrete or abstract idea. Given an input image, this paper seeks to retrieve other images that share its central concepts, capturing aspects of the underlying narrative. This goes beyond conventional retrieval or clustering methods, which emphasize visual or semantic similarity. We formally define the problem, outline key requirements, and introduce appropriate evaluation metrics. We propose a novel approach grounded in two key observations: (1) While each neighbor in the embedding space typically shares at least one concept with the query, not all neighbors necessarily share the same concept with one another. (2) Modeling this neighborhood with a bimodal Gaussian distribution uncovers meaningful structure that facilitates concept identification. Qualitative, quantitative, and human evaluations confirm the effectiveness of our approach. See the package on PyPI: https://pypi.org/project/coret/
SFMNet: Sparse Focal Modulation for 3D Object Detection
Mar 15, 2025



We propose SFMNet, a novel 3D sparse detector that combines the efficiency of sparse convolutions with the ability to model long-range dependencies. While traditional sparse convolution techniques efficiently capture local structures, they struggle with modeling long-range relationships. However, capturing long-range dependencies is fundamental for 3D object detection. In contrast, transformers are designed to capture these long-range dependencies through attention mechanisms. But, they come with high computational costs, due to their quadratic query-key-value interactions. Furthermore, directly applying attention to non-empty voxels is inefficient due to the sparse nature of 3D scenes. Our SFMNet is built on a novel Sparse Focal Modulation (SFM) module, which integrates short- and long-range contexts with linear complexity by leveraging a new hierarchical sparse convolution design. This approach enables SFMNet to achieve high detection performance with improved efficiency, making it well-suited for large-scale LiDAR scenes. We show that our detector achieves state-of-the-art performance on autonomous driving datasets.
Image-aware Evaluation of Generated Medical Reports
Oct 22, 2024



The paper proposes a novel evaluation metric for automatic medical report generation from X-ray images, VLScore. It aims to overcome the limitations of existing evaluation methods, which either focus solely on textual similarities, ignoring clinical aspects, or concentrate only on a single clinical aspect, the pathology, neglecting all other factors. The key idea of our metric is to measure the similarity between radiology reports while considering the corresponding image. We demonstrate the benefit of our metric through evaluation on a dataset where radiologists marked errors in pairs of reports, showing notable alignment with radiologists' judgments. In addition, we provide a new dataset for evaluating metrics. This dataset includes well-designed perturbations that distinguish between significant modifications (e.g., removal of a diagnosis) and insignificant ones. It highlights the weaknesses in current evaluation metrics and provides a clear framework for analysis.
MedRAT: Unpaired Medical Report Generation via Auxiliary Tasks
Jul 04, 2024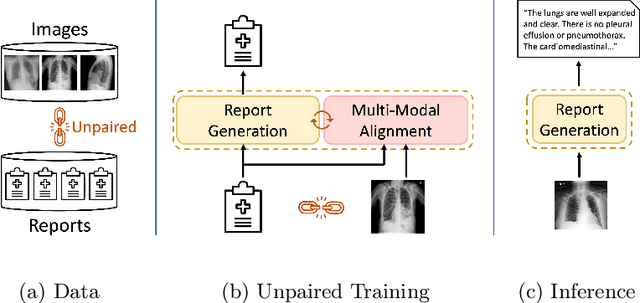

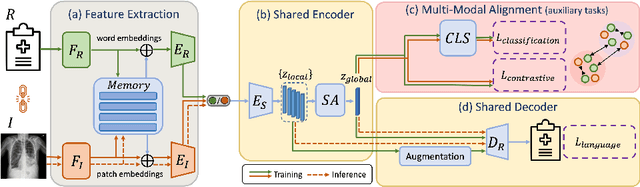

Generating medical reports for X-ray images is a challenging task, particularly in an unpaired scenario where paired image-report data is unavailable for training. To address this challenge, we propose a novel model that leverages the available information in two distinct datasets, one comprising reports and the other consisting of images. The core idea of our model revolves around the notion that combining auto-encoding report generation with multi-modal (report-image) alignment can offer a solution. However, the challenge persists regarding how to achieve this alignment when pair correspondence is absent. Our proposed solution involves the use of auxiliary tasks, particularly contrastive learning and classification, to position related images and reports in close proximity to each other. This approach differs from previous methods that rely on pre-processing steps using external information stored in a knowledge graph. Our model, named MedRAT, surpasses previous state-of-the-art methods, demonstrating the feasibility of generating comprehensive medical reports without the need for paired data or external tools.
MedCycle: Unpaired Medical Report Generation via Cycle-Consistency
Mar 21, 2024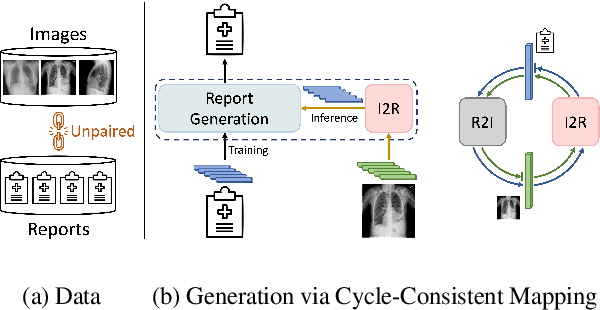

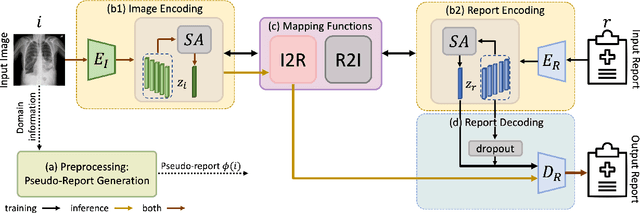

Generating medical reports for X-ray images presents a significant challenge, particularly in unpaired scenarios where access to paired image-report data for training is unavailable. Previous works have typically learned a joint embedding space for images and reports, necessitating a specific labeling schema for both. We introduce an innovative approach that eliminates the need for consistent labeling schemas, thereby enhancing data accessibility and enabling the use of incompatible datasets. This approach is based on cycle-consistent mapping functions that transform image embeddings into report embeddings, coupled with report auto-encoding for medical report generation. Our model and objectives consider intricate local details and the overarching semantic context within images and reports. This approach facilitates the learning of effective mapping functions, resulting in the generation of coherent reports. It outperforms state-of-the-art results in unpaired chest X-ray report generation, demonstrating improvements in both language and clinical metrics.
A Game of Bundle Adjustment -- Learning Efficient Convergence
Aug 25, 2023



Bundle adjustment is the common way to solve localization and mapping. It is an iterative process in which a system of non-linear equations is solved using two optimization methods, weighted by a damping factor. In the classic approach, the latter is chosen heuristically by the Levenberg-Marquardt algorithm on each iteration. This might take many iterations, making the process computationally expensive, which might be harmful to real-time applications. We propose to replace this heuristic by viewing the problem in a holistic manner, as a game, and formulating it as a reinforcement-learning task. We set an environment which solves the non-linear equations and train an agent to choose the damping factor in a learned manner. We demonstrate that our approach considerably reduces the number of iterations required to reach the bundle adjustment's convergence, on both synthetic and real-life scenarios. We show that this reduction benefits the classic approach and can be integrated with other bundle adjustment acceleration methods.
PatchContrast: Self-Supervised Pre-training for 3D Object Detection
Aug 14, 2023



Accurately detecting objects in the environment is a key challenge for autonomous vehicles. However, obtaining annotated data for detection is expensive and time-consuming. We introduce PatchContrast, a novel self-supervised point cloud pre-training framework for 3D object detection. We propose to utilize two levels of abstraction to learn discriminative representation from unlabeled data: proposal-level and patch-level. The proposal-level aims at localizing objects in relation to their surroundings, whereas the patch-level adds information about the internal connections between the object's components, hence distinguishing between different objects based on their individual components. We demonstrate how these levels can be integrated into self-supervised pre-training for various backbones to enhance the downstream 3D detection task. We show that our method outperforms existing state-of-the-art models on three commonly-used 3D detection datasets.
k-NNN: Nearest Neighbors of Neighbors for Anomaly Detection
May 28, 2023
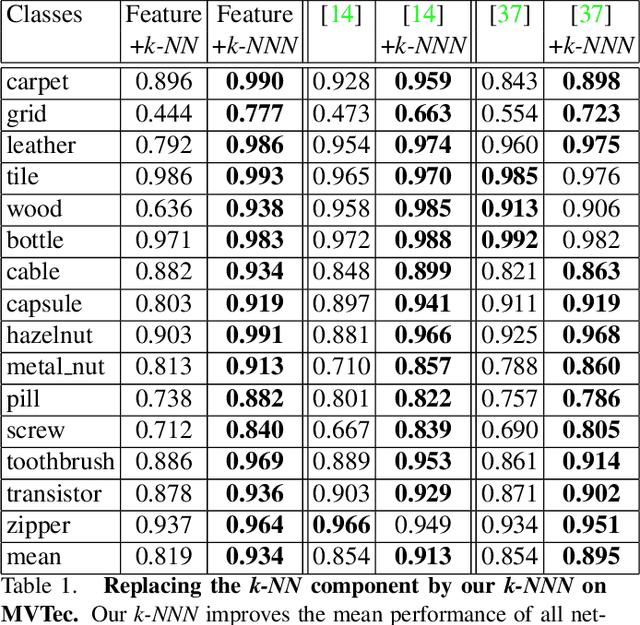
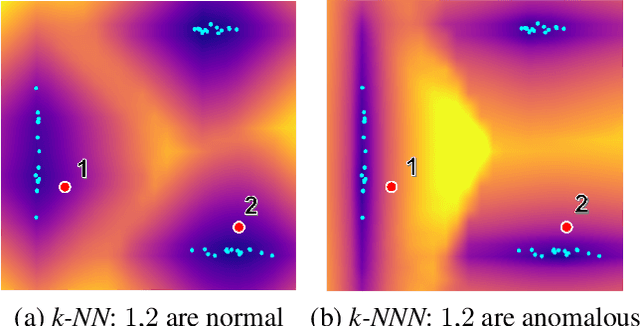
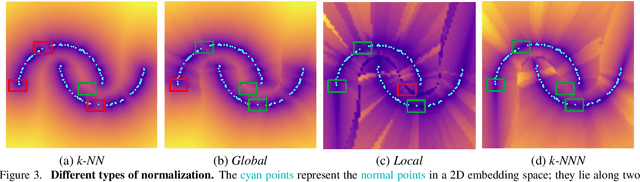
Anomaly detection aims at identifying images that deviate significantly from the norm. We focus on algorithms that embed the normal training examples in space and when given a test image, detect anomalies based on the features distance to the k-nearest training neighbors. We propose a new operator that takes into account the varying structure & importance of the features in the embedding space. Interestingly, this is done by taking into account not only the nearest neighbors, but also the neighbors of these neighbors (k-NNN). We show that by simply replacing the nearest neighbor component in existing algorithms by our k-NNN operator, while leaving the rest of the algorithms untouched, each algorithms own results are improved. This is the case both for common homogeneous datasets, such as flowers or nuts of a specific type, as well as for more diverse datasets