 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Evaluation Metrics for SVG Generation via Leave-One-Out Analysis
Apr 09, 2026Scalable Vector Graphics (SVG) represent visual content as structured, editable code. Each element (path, shape, or text node) can be individually inspected, transformed, or removed. This structural editability is a main motivation for SVG generation, yet prevailing evaluation protocols primarily reduce the output to a single similarity score against a reference image or input texts, measuring how faithfully the result reproduces an image or follows the instructions, but not how well it preserves the structural properties that make SVG valuable. In particular, existing metrics cannot determine which generated elements contribute positively to overall visual quality, how visual concepts map to specific parts of the code, or whether the generated output supports meaningful downstream editing. We introduce element-level leave-one-out (LOO) analysis, inspired by the classic jackknife estimator. The procedure renders the SVG with and without each element, measures the resulting visual change, and derives a suite of structural quality metrics. Despite its simplicity, the jackknife's capacity to decompose an aggregate statistic into per-sample contributions translates directly to this setting. From a single mechanism, we obtain: (1) quality scores per element through LOO scoring that enable zero-shot artifact detection; (2) concept-element attribution that maps each element to the visual concept it serves; and (3) four structural metrics, purity, coverage, compactness, and locality, that quantify SVG modularity from complementary perspectives. We validate these metrics on over 19,000 edits (5 types) across 5 generation systems and 3 complexity tiers.
Graphic-Design-Bench: A Comprehensive Benchmark for Evaluating AI on Graphic Design Tasks
Apr 07, 2026We introduce GraphicDesignBench (GDB), the first comprehensive benchmark suite designed specifically to evaluate AI models on the full breadth of professional graphic design tasks. Unlike existing benchmarks that focus on natural-image understanding or generic text-to-image synthesis, GDB targets the unique challenges of professional design work: translating communicative intent into structured layouts, rendering typographically faithful text, manipulating layered compositions, producing valid vector graphics, and reasoning about animation. The suite comprises 50 tasks organized along five axes: layout, typography, infographics, template & design semantics and animation, each evaluated under both understanding and generation settings, and grounded in real-world design templates drawn from the LICA layered-composition dataset. We evaluate a set of frontier closed-source models using a standardized metric taxonomy covering spatial accuracy, perceptual quality, text fidelity, semantic alignment, and structural validity. Our results reveal that current models fall short on the core challenges of professional design: spatial reasoning over complex layouts, faithful vector code generation, fine-grained typographic perception, and temporal decomposition of animations remain largely unsolved. While high-level semantic understanding is within reach, the gap widens sharply as tasks demand precision, structure, and compositional awareness. GDB provides a rigorous, reproducible testbed for tracking progress toward AI systems that can function as capable design collaborators. The full evaluation framework is publicly available.
LICA: Layered Image Composition Annotations for Graphic Design Research
Mar 17, 2026We introduce LICA (Layered Image Composition Annotations), a large-scale dataset of 1,550,244 multi-layer graphic design compositions designed to advance structured understanding and generation of graphic layouts1. In addition to ren- dered PNG images, LICA represents each design as a hierarchical composition of typed components including text, image, vector, and group elements, each paired with rich per-element metadata such as spatial geometry, typographic attributes, opacity, and visibility. The dataset spans 20 design categories and 971,850 unique templates, providing broad coverage of real-world design structures. We further introduce graphic design video as a new and largely unexplored challenge for current vision-language models through 27,261 animated layouts annotated with per-component keyframes and motion parameters. Beyond scale, LICA establishes a new paradigm of research tasks for graphic design, enabling structured investiga- tions into problems such as layer-aware inpainting, structured layout generation, controlled design editing, and temporally-aware generative modeling. By repre- senting design as a system of compositional layers and relationships, the dataset supports research on models that operate directly on design structure rather than pixels alone.
Image-aware Evaluation of Generated Medical Reports
Oct 22, 2024



The paper proposes a novel evaluation metric for automatic medical report generation from X-ray images, VLScore. It aims to overcome the limitations of existing evaluation methods, which either focus solely on textual similarities, ignoring clinical aspects, or concentrate only on a single clinical aspect, the pathology, neglecting all other factors. The key idea of our metric is to measure the similarity between radiology reports while considering the corresponding image. We demonstrate the benefit of our metric through evaluation on a dataset where radiologists marked errors in pairs of reports, showing notable alignment with radiologists' judgments. In addition, we provide a new dataset for evaluating metrics. This dataset includes well-designed perturbations that distinguish between significant modifications (e.g., removal of a diagnosis) and insignificant ones. It highlights the weaknesses in current evaluation metrics and provides a clear framework for analysis.
MedRAT: Unpaired Medical Report Generation via Auxiliary Tasks
Jul 04, 2024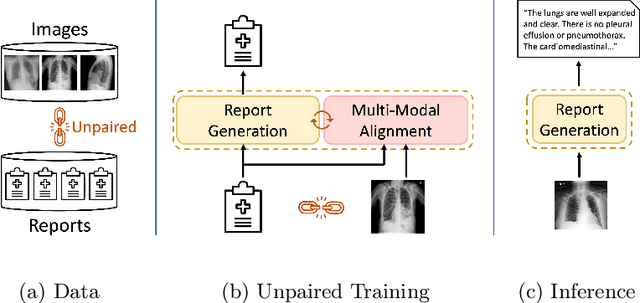

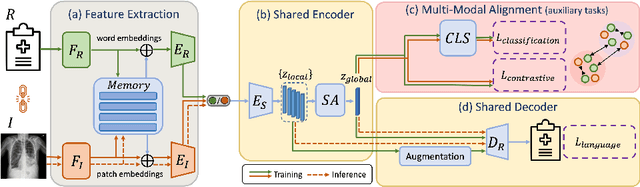

Generating medical reports for X-ray images is a challenging task, particularly in an unpaired scenario where paired image-report data is unavailable for training. To address this challenge, we propose a novel model that leverages the available information in two distinct datasets, one comprising reports and the other consisting of images. The core idea of our model revolves around the notion that combining auto-encoding report generation with multi-modal (report-image) alignment can offer a solution. However, the challenge persists regarding how to achieve this alignment when pair correspondence is absent. Our proposed solution involves the use of auxiliary tasks, particularly contrastive learning and classification, to position related images and reports in close proximity to each other. This approach differs from previous methods that rely on pre-processing steps using external information stored in a knowledge graph. Our model, named MedRAT, surpasses previous state-of-the-art methods, demonstrating the feasibility of generating comprehensive medical reports without the need for paired data or external tools.
MedCycle: Unpaired Medical Report Generation via Cycle-Consistency
Mar 21, 2024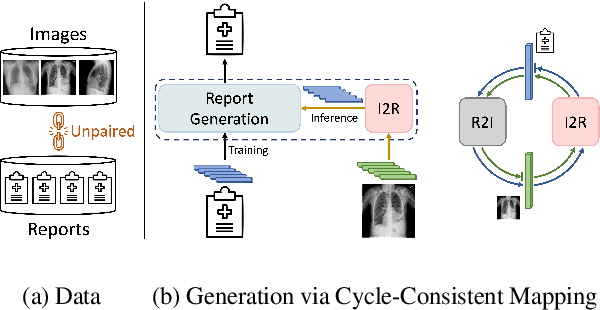

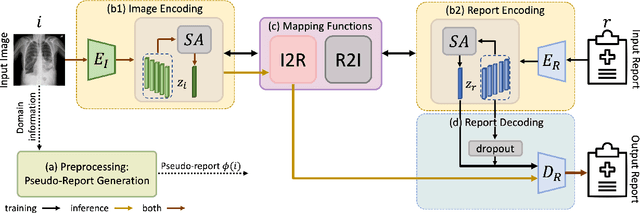

Generating medical reports for X-ray images presents a significant challenge, particularly in unpaired scenarios where access to paired image-report data for training is unavailable. Previous works have typically learned a joint embedding space for images and reports, necessitating a specific labeling schema for both. We introduce an innovative approach that eliminates the need for consistent labeling schemas, thereby enhancing data accessibility and enabling the use of incompatible datasets. This approach is based on cycle-consistent mapping functions that transform image embeddings into report embeddings, coupled with report auto-encoding for medical report generation. Our model and objectives consider intricate local details and the overarching semantic context within images and reports. This approach facilitates the learning of effective mapping functions, resulting in the generation of coherent reports. It outperforms state-of-the-art results in unpaired chest X-ray report generation, demonstrating improvements in both language and clinical metrics.
Asymmetric Face Recognition with Cross Model Compatible Ensembles
Mar 30, 2023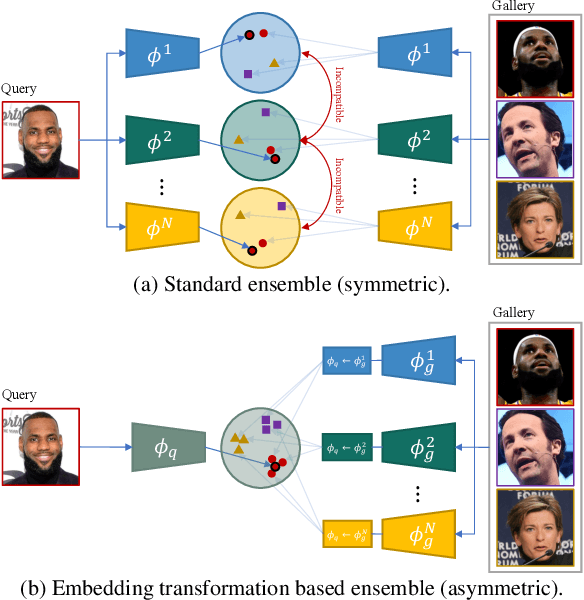
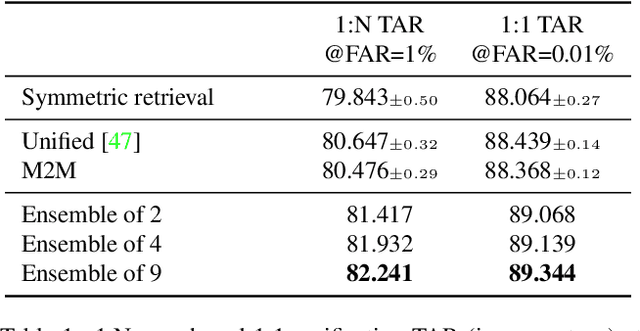
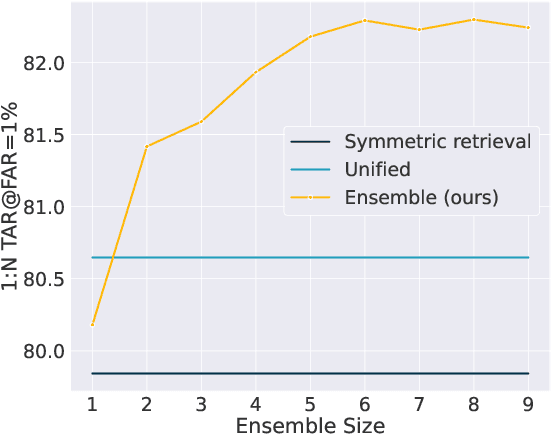

The asymmetrical retrieval setting is a well suited solution for resource constrained face recognition. In this setting a large model is used for indexing the gallery while a lightweight model is used for querying. The key principle in such systems is ensuring that both models share the same embedding space. Most methods in this domain are based on knowledge distillation. While useful, they suffer from several drawbacks: they are upper-bounded by the performance of the single best model found and cannot be extended to use an ensemble of models in a straightforward manner. In this paper we present an approach that does not rely on knowledge distillation, rather it utilizes embedding transformation models. This allows the use of N independently trained and diverse gallery models (e.g., trained on different datasets or having a different architecture) and a single query model. As a result, we improve the overall accuracy beyond that of any single model while maintaining a low computational budget for querying. Additionally, we propose a gallery image rejection method that utilizes the diversity between multiple transformed embeddings to estimate the uncertainty of gallery images.
LIMITR: Leveraging Local Information for Medical Image-Text Representation
Mar 21, 2023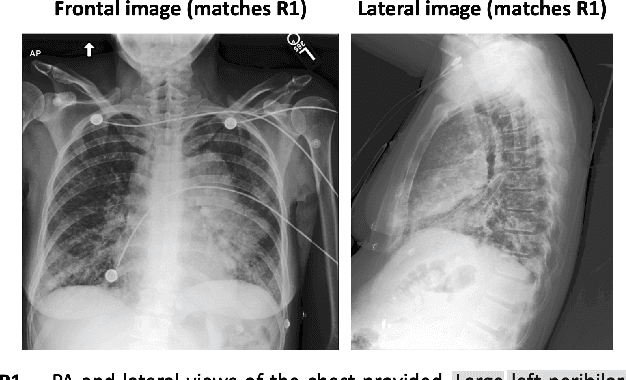



Medical imaging analysis plays a critical role in the diagnosis and treatment of various medical conditions. This paper focuses on chest X-ray images and their corresponding radiological reports. It presents a new model that learns a joint X-ray image & report representation. The model is based on a novel alignment scheme between the visual data and the text, which takes into account both local and global information. Furthermore, the model integrates domain-specific information of two types -- lateral images and the consistent visual structure of chest images. Our representation is shown to benefit three types of retrieval tasks: text-image retrieval, class-based retrieval, and phrase-grounding.
CLID: Controlled-Length Image Descriptions with Limited Data
Nov 27, 2022


Controllable image captioning models generate human-like image descriptions, enabling some kind of control over the generated captions. This paper focuses on controlling the caption length, i.e. a short and concise description or a long and detailed one. Since existing image captioning datasets contain mostly short captions, generating long captions is challenging. To address the shortage of long training examples, we propose to enrich the dataset with varying-length self-generated captions. These, however, might be of varying quality and are thus unsuitable for conventional training. We introduce a novel training strategy that selects the data points to be used at different times during the training. Our method dramatically improves the length-control abilities, while exhibiting SoTA performance in terms of caption quality. Our approach is general and is shown to be applicable also to paragraph generation.
A Statistical Story of Visual Illusions
May 18, 2020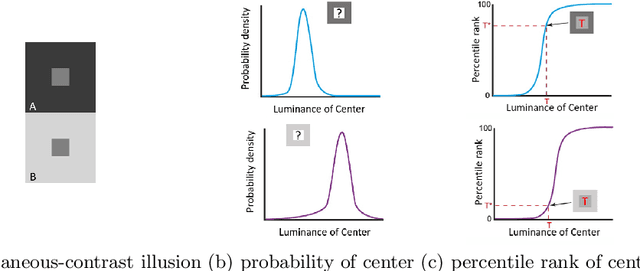
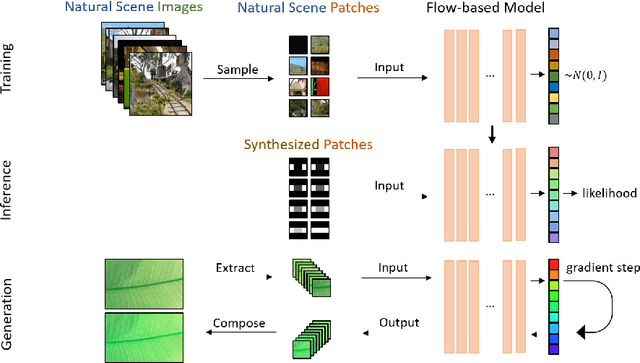
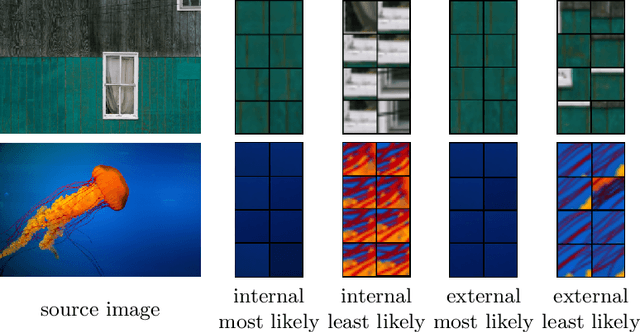
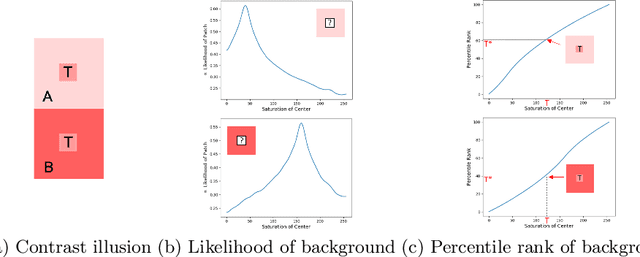
This paper explores the wholly empirical paradigm of visual illusions, which was introduced two decades ago in Neuro-Science. This data-driven approach attempts to explain visual illusions by the likelihood of patches in real-world images. Neither the data, nor the tools, existed at the time to extensively support this paradigm. In the era of big data and deep learning, at last, it becomes possible. This paper introduces a tool that computes the likelihood of patches, given a large dataset to learn from. Given this tool, we present an approach that manages to support the paradigm and explain visual illusions in a unified manner. Furthermore, we show how to generate (or enhance) visual illusions in natural images, by applying the same principles (and tool) reversely.