 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedRAT: Unpaired Medical Report Generation via Auxiliary Tasks
Paper and Code
Jul 04, 2024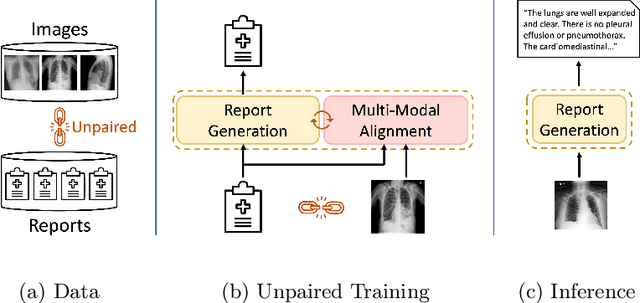

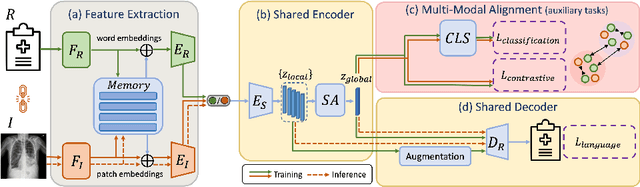

Generating medical reports for X-ray images is a challenging task, particularly in an unpaired scenario where paired image-report data is unavailable for training. To address this challenge, we propose a novel model that leverages the available information in two distinct datasets, one comprising reports and the other consisting of images. The core idea of our model revolves around the notion that combining auto-encoding report generation with multi-modal (report-image) alignment can offer a solution. However, the challenge persists regarding how to achieve this alignment when pair correspondence is absent. Our proposed solution involves the use of auxiliary tasks, particularly contrastive learning and classification, to position related images and reports in close proximity to each other. This approach differs from previous methods that rely on pre-processing steps using external information stored in a knowledge graph. Our model, named MedRAT, surpasses previous state-of-the-art methods, demonstrating the feasibility of generating comprehensive medical reports without the need for paired data or external tools.