 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleMotif: Multi-Modal Motion Stylization using Style-Content Cross Fusion
Paper and Code
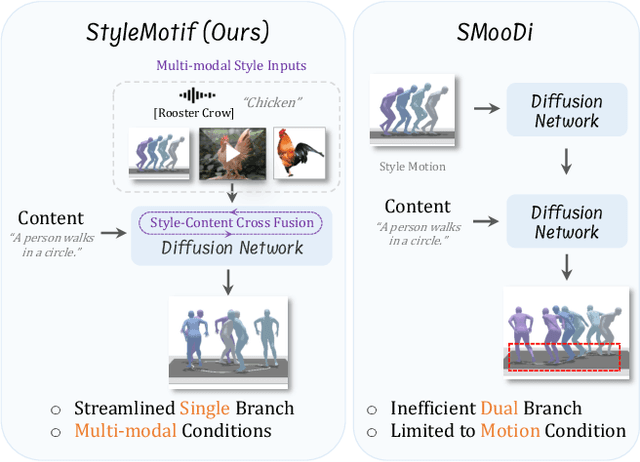
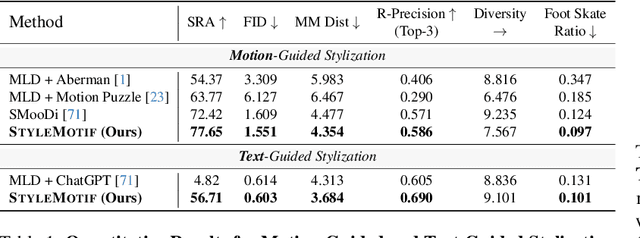
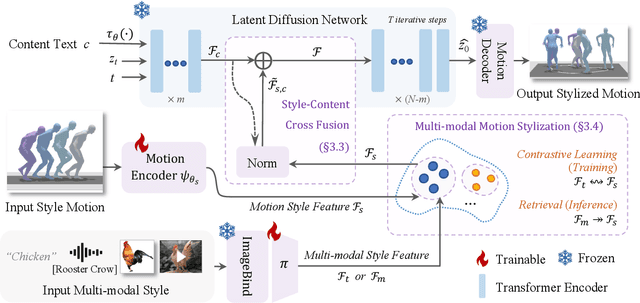
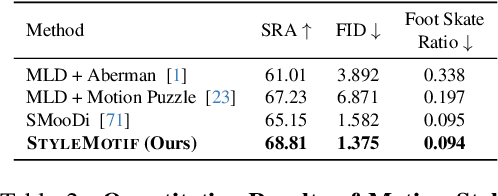
We present StyleMotif, a novel Stylized Motion Latent Diffusion model, generating motion conditioned on both content and style from multiple modalities. Unlike existing approaches that either focus on generating diverse motion content or transferring style from sequences, StyleMotif seamlessly synthesizes motion across a wide range of content while incorporating stylistic cues from multi-modal inputs, including motion, text, image, video, and audio. To achieve this, we introduce a style-content cross fusion mechanism and align a style encoder with a pre-trained multi-modal model, ensuring that the generated motion accurately captures the reference style while preserving realism. Extensive experiments demonstrate that our framework surpasses existing methods in stylized motion generation and exhibits emergent capabilities for multi-modal motion stylization, enabling more nuanced motion synthesis. Source code and pre-trained models will be released upon acceptance. Project Page: https://stylemotif.github.io