 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoMo: A Large-Scale, Richly Organized Dataset and Semantic Taxonomy for Human Motion Generation
May 25, 2026Success in generative modeling across language, image, and video demonstrates that large, well-curated datasets are the key driver for building capable models. 3D Human motion, however, has lagged behind, constrained by an unsatisfying choice between small, high-fidelity motion capture datasets and large-scale in-the-wild collections dominated by static or low-quality sequences. We introduce RoMo, a rich, large-scale, carefully curated dataset of in-the-wild human motions that resolves these tradeoffs. To ensure quality, we introduce a taxonomy-aware filtering pipeline that aggressively removes static and artifact-prone sequences. Every sequence is annotated with detailed captions and organized by a novel three-level semantic taxonomy. This hierarchical structure enables fine-grained, per-category evaluation, that reveals model strengths and weaknesses obscured by global metrics. We demonstrate that models trained on RoMo achieve state-of-the-art fidelity and diversity while gaining a superior understanding of complex, subtle text prompts. Finally, we release the Motion Toolbox to standardize metrics, data conversion, and visualization, establishing a foundation for reproducible and interpretable motion generation research.
Regularized Entropy Information Adaptation with Temporal-Awareness Networks for Simultaneous Speech Translation
Apr 10, 2026Simultaneous Speech Translation (SimulST) requires balancing high translation quality with low latency. Recent work introduced REINA, a method that trains a Read/Write policy based on estimating the information gain of reading more audio. However, we find that information-based policies often lack temporal context, leading the policy to bias itself toward reading most of the audio before starting to write. We improve REINA using two distinct strategies: a supervised alignment network (REINA-SAN) and a timestep-augmented network (REINA-TAN). Our results demonstrate that while both methods significantly outperform the baseline and resolve stability issues, REINA-TAN provides a slightly superior Pareto frontier for streaming efficiency, whereas REINA-SAN offers more robustness against 'read loops'. Applied to Whisper, both methods improve the pareto frontier of streaming efficiency as measured by Normalized Streaming Efficiency (NoSE) scores up to 7.1% over existing competitive baselines.
REINA: Regularized Entropy Information-Based Loss for Efficient Simultaneous Speech Translation
Aug 07, 2025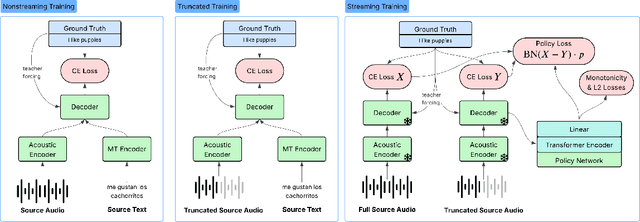
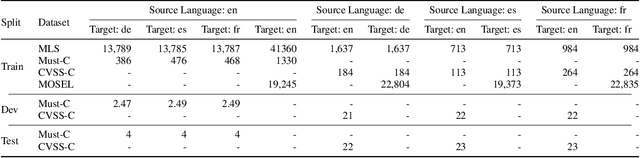
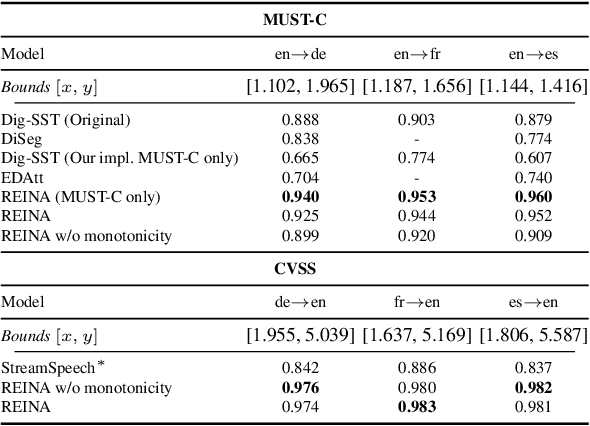
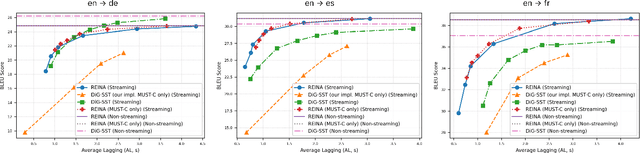
Simultaneous Speech Translation (SimulST) systems stream in audio while simultaneously emitting translated text or speech. Such systems face the significant challenge of balancing translation quality and latency. We introduce a strategy to optimize this tradeoff: wait for more input only if you gain information by doing so. Based on this strategy, we present Regularized Entropy INformation Adaptation (REINA), a novel loss to train an adaptive policy using an existing non-streaming translation model. We derive REINA from information theory principles and show that REINA helps push the reported Pareto frontier of the latency/quality tradeoff over prior works. Utilizing REINA, we train a SimulST model on French, Spanish and German, both from and into English. Training on only open source or synthetically generated data, we achieve state-of-the-art (SOTA) streaming results for models of comparable size. We also introduce a metric for streaming efficiency, quantitatively showing REINA improves the latency/quality trade-off by as much as 21% compared to prior approaches, normalized against non-streaming baseline BLEU scores.
Symbolic Representation for Any-to-Any Generative Tasks
Apr 24, 2025
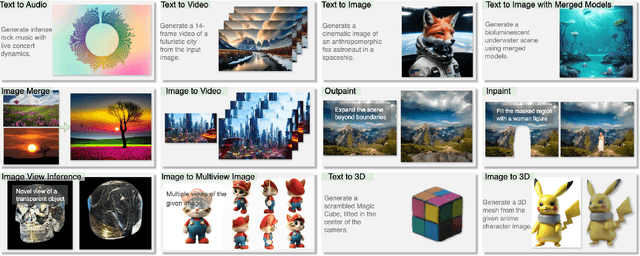
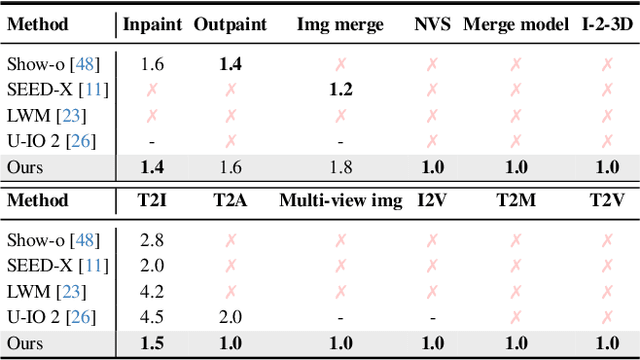

We propose a symbolic generative task description language and a corresponding inference engine capable of representing arbitrary multimodal tasks as structured symbolic flows. Unlike conventional generative models that rely on large-scale training and implicit neural representations to learn cross-modal mappings, often at high computational cost and with limited flexibility, our framework introduces an explicit symbolic representation comprising three core primitives: functions, parameters, and topological logic. Leveraging a pre-trained language model, our inference engine maps natural language instructions directly to symbolic workflows in a training-free manner. Our framework successfully performs over 12 diverse multimodal generative tasks, demonstrating strong performance and flexibility without the need for task-specific tuning. Experiments show that our method not only matches or outperforms existing state-of-the-art unified models in content quality, but also offers greater efficiency, editability, and interruptibility. We believe that symbolic task representations provide a cost-effective and extensible foundation for advancing the capabilities of generative AI.
Evaluation Under Imperfect Benchmarks and Ratings: A Case Study in Text Simplification
Apr 15, 2025
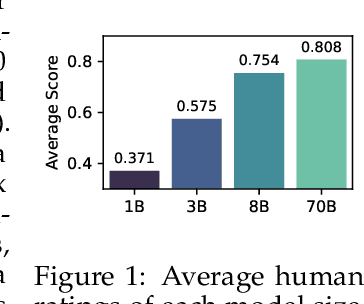


Despite the successes of language models, their evaluation remains a daunting challenge for new and existing tasks. We consider the task of text simplification, commonly used to improve information accessibility, where evaluation faces two major challenges. First, the data in existing benchmarks might not reflect the capabilities of current language models on the task, often containing disfluent, incoherent, or simplistic examples. Second, existing human ratings associated with the benchmarks often contain a high degree of disagreement, resulting in inconsistent ratings; nevertheless, existing metrics still have to show higher correlations with these imperfect ratings. As a result, evaluation for the task is not reliable and does not reflect expected trends (e.g., more powerful models being assigned higher scores). We address these challenges for the task of text simplification through three contributions. First, we introduce SynthSimpliEval, a synthetic benchmark for text simplification featuring simplified sentences generated by models of varying sizes. Through a pilot study, we show that human ratings on our benchmark exhibit high inter-annotator agreement and reflect the expected trend: larger models produce higher-quality simplifications. Second, we show that auto-evaluation with a panel of LLM judges (LLMs-as-a-jury) often suffices to obtain consistent ratings for the evaluation of text simplification. Third, we demonstrate that existing learnable metrics for text simplification benefit from training on our LLMs-as-a-jury-rated synthetic data, closing the gap with pure LLMs-as-a-jury for evaluation. Overall, through our case study on text simplification, we show that a reliable evaluation requires higher quality test data, which could be obtained through synthetic data and LLMs-as-a-jury ratings.
StyleMotif: Multi-Modal Motion Stylization using Style-Content Cross Fusion
Mar 27, 2025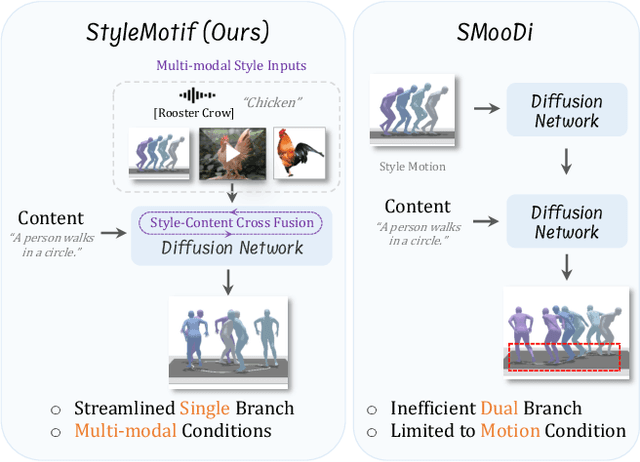
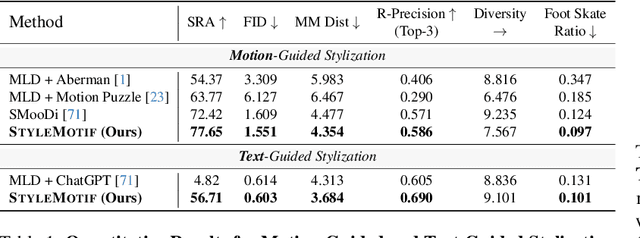
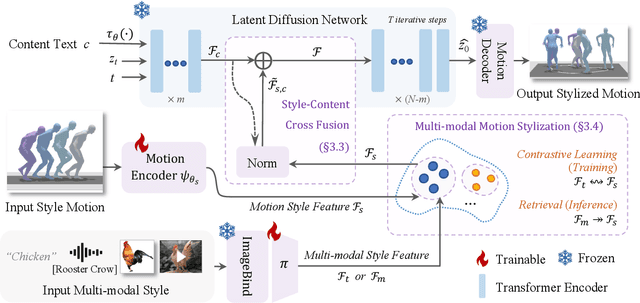
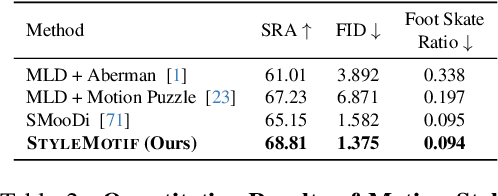
We present StyleMotif, a novel Stylized Motion Latent Diffusion model, generating motion conditioned on both content and style from multiple modalities. Unlike existing approaches that either focus on generating diverse motion content or transferring style from sequences, StyleMotif seamlessly synthesizes motion across a wide range of content while incorporating stylistic cues from multi-modal inputs, including motion, text, image, video, and audio. To achieve this, we introduce a style-content cross fusion mechanism and align a style encoder with a pre-trained multi-modal model, ensuring that the generated motion accurately captures the reference style while preserving realism. Extensive experiments demonstrate that our framework surpasses existing methods in stylized motion generation and exhibits emergent capabilities for multi-modal motion stylization, enabling more nuanced motion synthesis. Source code and pre-trained models will be released upon acceptance. Project Page: https://stylemotif.github.io
Less is More: Improving Motion Diffusion Models with Sparse Keyframes
Mar 18, 2025Recent advances in motion diffusion models have led to remarkable progress in diverse motion generation tasks, including text-to-motion synthesis. However, existing approaches represent motions as dense frame sequences, requiring the model to process redundant or less informative frames. The processing of dense animation frames imposes significant training complexity, especially when learning intricate distributions of large motion datasets even with modern neural architectures. This severely limits the performance of generative motion models for downstream tasks. Inspired by professional animators who mainly focus on sparse keyframes, we propose a novel diffusion framework explicitly designed around sparse and geometrically meaningful keyframes. Our method reduces computation by masking non-keyframes and efficiently interpolating missing frames. We dynamically refine the keyframe mask during inference to prioritize informative frames in later diffusion steps. Extensive experiments show that our approach consistently outperforms state-of-the-art methods in text alignment and motion realism, while also effectively maintaining high performance at significantly fewer diffusion steps. We further validate the robustness of our framework by using it as a generative prior and adapting it to different downstream tasks. Source code and pre-trained models will be released upon acceptance.
SmoothCache: A Universal Inference Acceleration Technique for Diffusion Transformers
Nov 15, 2024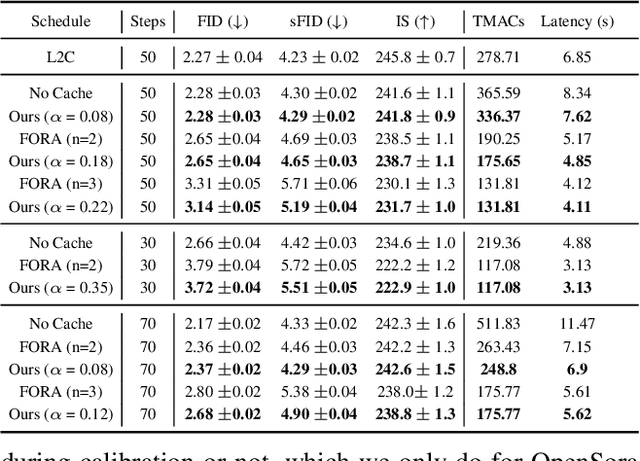
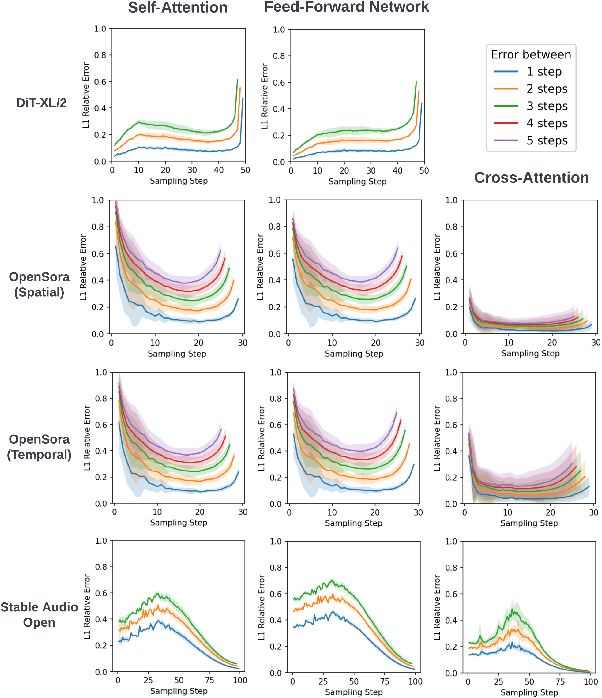

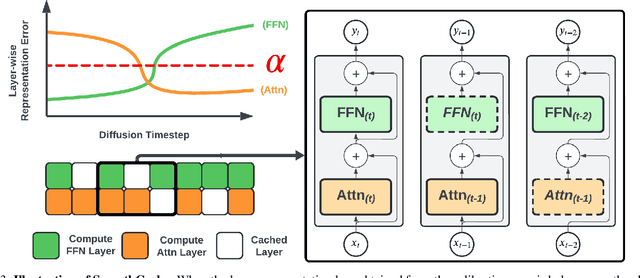
Diffusion Transformers (DiT) have emerged as powerful generative models for various tasks, including image, video, and speech synthesis. However, their inference process remains computationally expensive due to the repeated evaluation of resource-intensive attention and feed-forward modules. To address this, we introduce SmoothCache, a model-agnostic inference acceleration technique for DiT architectures. SmoothCache leverages the observed high similarity between layer outputs across adjacent diffusion timesteps. By analyzing layer-wise representation errors from a small calibration set, SmoothCache adaptively caches and reuses key features during inference. Our experiments demonstrate that SmoothCache achieves 8% to 71% speed up while maintaining or even improving generation quality across diverse modalities. We showcase its effectiveness on DiT-XL for image generation, Open-Sora for text-to-video, and Stable Audio Open for text-to-audio, highlighting its potential to enable real-time applications and broaden the accessibility of powerful DiT models.
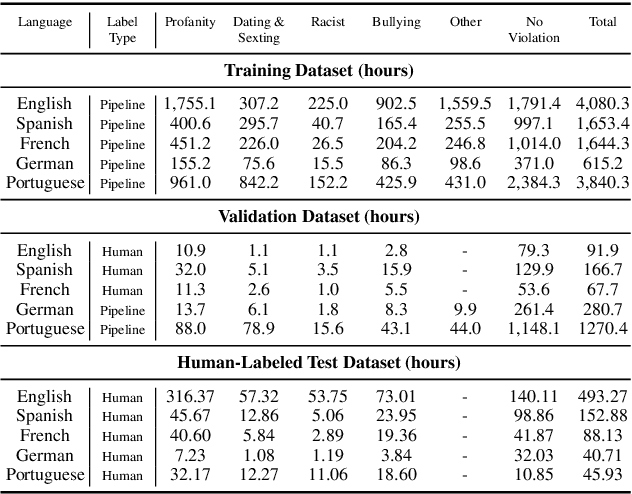
Enhancing Multilingual Voice Toxicity Detection with Speech-Text Alignment
Jun 14, 2024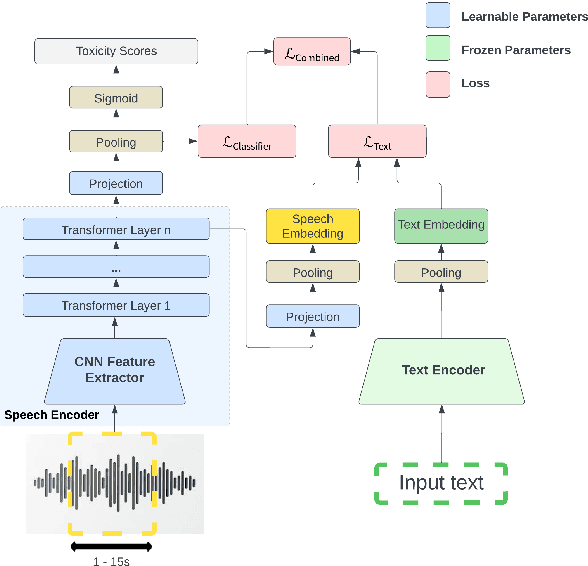
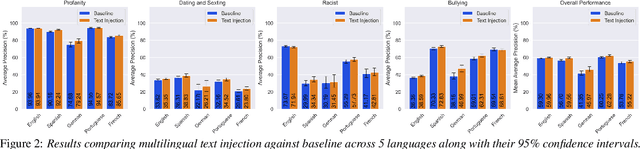
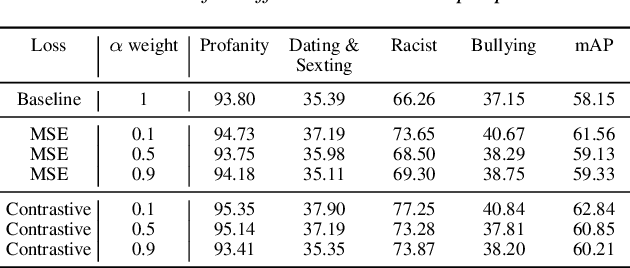
Toxicity classification for voice heavily relies on the semantic content of speech. We propose a novel framework that utilizes cross-modal learning to integrate the semantic embedding of text into a multilabel speech toxicity classifier during training. This enables us to incorporate textual information during training while still requiring only audio during inference. We evaluate this classifier on large-scale datasets with real-world characteristics to validate the effectiveness of this framework. Through ablation studies, we demonstrate that general-purpose semantic text embeddings are rich and aligned with speech for toxicity classification purposes. Conducting experiments across multiple languages at scale, we show improvements in voice toxicity classification across five languages and different toxicity categories.
Diffusion Synthesizer for Efficient Multilingual Speech to Speech Translation
Jun 14, 2024



We introduce DiffuseST, a low-latency, direct speech-to-speech translation system capable of preserving the input speaker's voice zero-shot while translating from multiple source languages into English. We experiment with the synthesizer component of the architecture, comparing a Tacotron-based synthesizer to a novel diffusion-based synthesizer. We find the diffusion-based synthesizer to improve MOS and PESQ audio quality metrics by 23\% each and speaker similarity by 5\% while maintaining comparable BLEU scores. Despite having more than double the parameter count, the diffusion synthesizer has lower latency, allowing the entire model to run more than 5$\times$ faster than real-time.