 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multilingual Voice Toxicity Detection with Speech-Text Alignment
Jun 14, 2024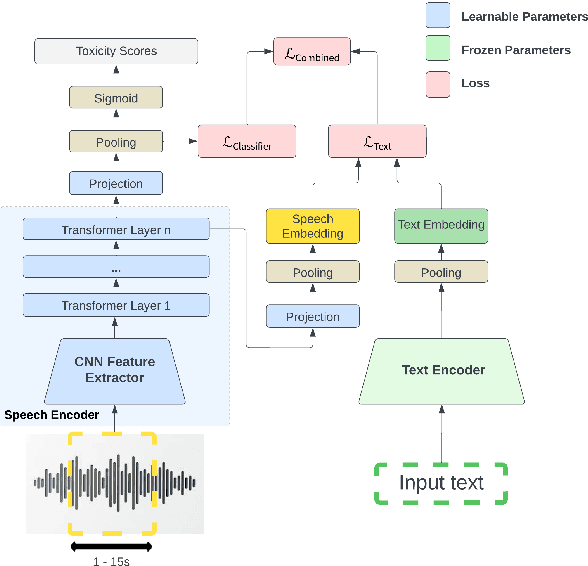
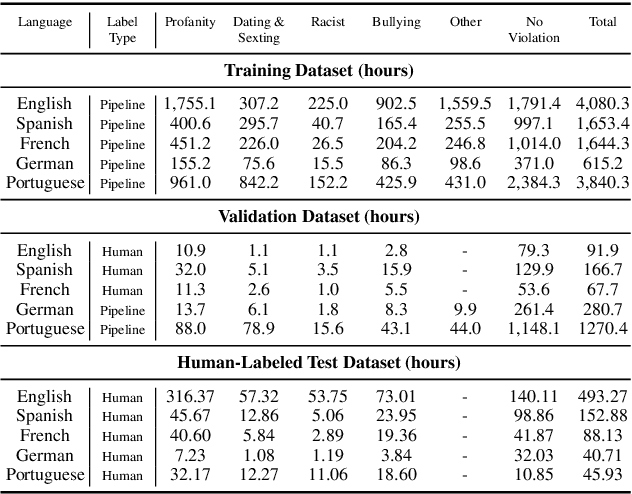
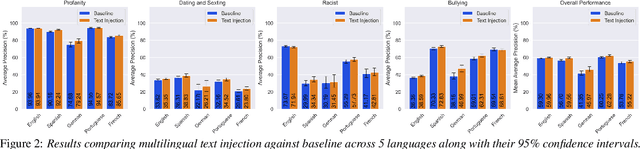
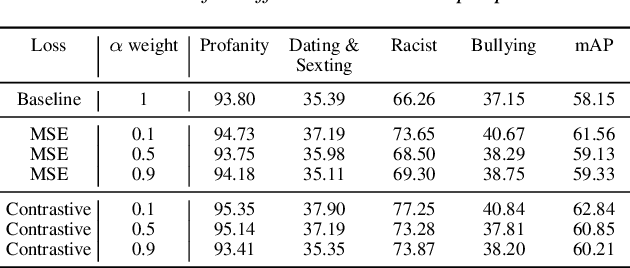
Toxicity classification for voice heavily relies on the semantic content of speech. We propose a novel framework that utilizes cross-modal learning to integrate the semantic embedding of text into a multilabel speech toxicity classifier during training. This enables us to incorporate textual information during training while still requiring only audio during inference. We evaluate this classifier on large-scale datasets with real-world characteristics to validate the effectiveness of this framework. Through ablation studies, we demonstrate that general-purpose semantic text embeddings are rich and aligned with speech for toxicity classification purposes. Conducting experiments across multiple languages at scale, we show improvements in voice toxicity classification across five languages and different toxicity categories.
Fast Text-Only Domain Adaptation of RNN-Transducer Prediction Network
Apr 22, 2021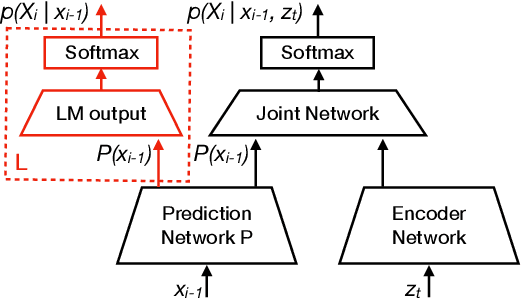

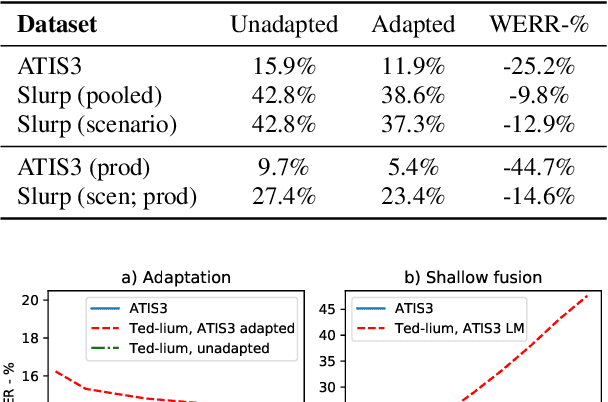
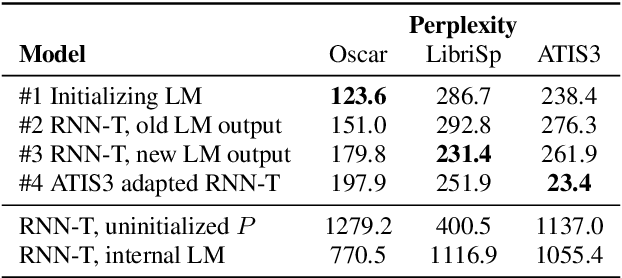
Adaption of end-to-end speech recognition systems to new tasks is known to be challenging. A number of solutions have been proposed which apply external language models with various fusion methods, possibly with a combination of two-pass decoding. Also TTS systems have been used to generate adaptation data for the end-to-end models. In this paper we show that RNN-transducer models can be effectively adapted to new domains using only small amounts of textual data. By taking advantage of model's inherent structure, where the prediction network is interpreted as a language model, we can apply fast adaptation to the model. Adapting the model avoids the need for complicated decoding time fusions and external language models. Using appropriate regularization, the prediction network can be adapted to new domains while still retaining good generalization capabilities. We show with multiple ASR evaluation tasks how this method can provide relative gains of 10-45% in target task WER. We also share insights how RNN-transducer prediction network performs as a language model.