 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Cooperative Multi-Agent Reinforcement Learning via Robust Value Factorization
Feb 11, 2026Cooperative multi-agent reinforcement learning (MARL) commonly adopts centralized training with decentralized execution, where value-factorization methods enforce the individual-global-maximum (IGM) principle so that decentralized greedy actions recover the team-optimal joint action. However, the reliability of this recipe in real-world settings remains unreliable due to environmental uncertainties arising from the sim-to-real gap, model mismatch, and system noise. We address this gap by introducing Distributionally robust IGM (DrIGM), a principle that requires each agent's robust greedy action to align with the robust team-optimal joint action. We show that DrIGM holds for a novel definition of robust individual action values, which is compatible with decentralized greedy execution and yields a provable robustness guarantee for the whole system. Building on this foundation, we derive DrIGM-compliant robust variants of existing value-factorization architectures (e.g., VDN/QMIX/QTRAN) that (i) train on robust Q-targets, (ii) preserve scalability, and (iii) integrate seamlessly with existing codebases without bespoke per-agent reward shaping. Empirically, on high-fidelity SustainGym simulators and a StarCraft game environment, our methods consistently improve out-of-distribution performance. Code and data are available at https://github.com/crqu/robust-coMARL.
End-to-End Conformal Calibration for Optimization Under Uncertainty
Sep 30, 2024



Machine learning can significantly improve performance for decision-making under uncertainty in a wide range of domains. However, ensuring robustness guarantees requires well-calibrated uncertainty estimates, which can be difficult to achieve in high-capacity prediction models such as deep neural networks. Moreover, in high-dimensional settings, there may be many valid uncertainty estimates, each with their own performance profile - i.e., not all uncertainty is equally valuable for downstream decision-making. To address this problem, this paper develops an end-to-end framework to learn the uncertainty estimates for conditional robust optimization, with robustness and calibration guarantees provided by conformal prediction. In addition, we propose to represent arbitrary convex uncertainty sets with partially input-convex neural networks, which are learned as part of our framework. Our approach consistently improves upon two-stage estimate-then-optimize baselines on concrete applications in energy storage arbitrage and portfolio optimization.
SustainBench: Benchmarks for Monitoring the Sustainable Development Goals with Machine Learning
Nov 08, 2021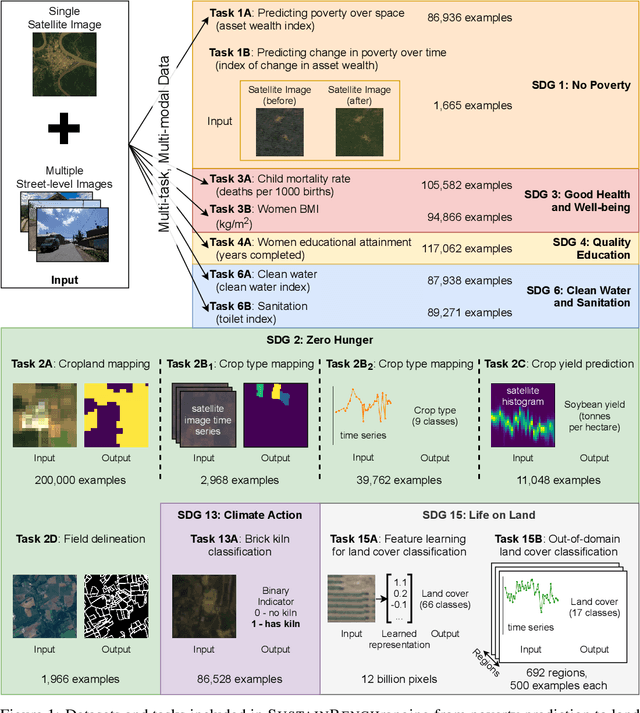
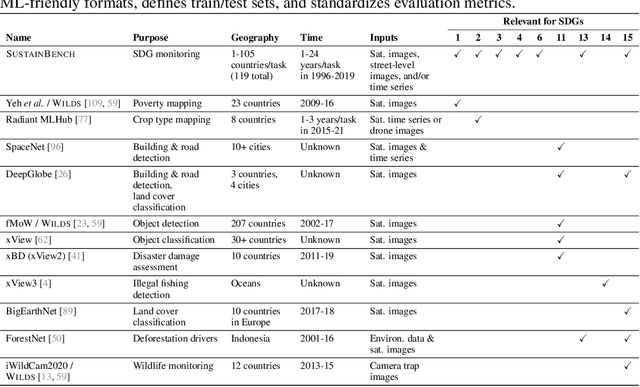
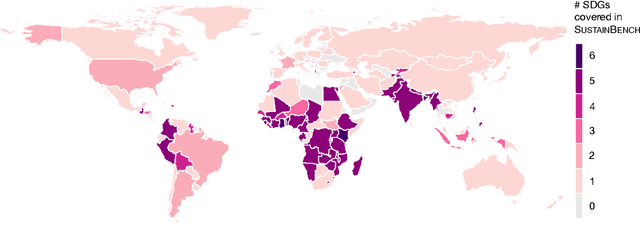
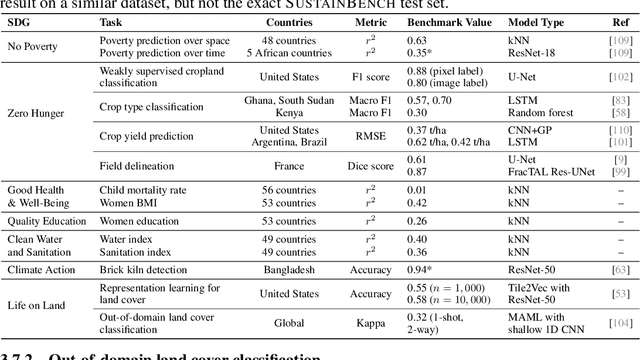
Progress toward the United Nations Sustainable Development Goals (SDGs) has been hindered by a lack of data on key environmental and socioeconomic indicators, which historically have come from ground surveys with sparse temporal and spatial coverage. Recent advances in machine learning have made it possible to utilize abundant, frequently-updated, and globally available data, such as from satellites or social media, to provide insights into progress toward SDGs. Despite promising early results, approaches to using such data for SDG measurement thus far have largely evaluated on different datasets or used inconsistent evaluation metrics, making it hard to understand whether performance is improving and where additional research would be most fruitful. Furthermore, processing satellite and ground survey data requires domain knowledge that many in the machine learning community lack. In this paper, we introduce SustainBench, a collection of 15 benchmark tasks across 7 SDGs, including tasks related to economic development, agriculture, health, education, water and sanitation, climate action, and life on land. Datasets for 11 of the 15 tasks are released publicly for the first time. Our goals for SustainBench are to (1) lower the barriers to entry for the machine learning community to contribute to measuring and achieving the SDGs; (2) provide standard benchmarks for evaluating machine learning models on tasks across a variety of SDGs; and (3) encourage the development of novel machine learning methods where improved model performance facilitates progress towards the SDGs.
A Framework for Sample Efficient Interval Estimation with Control Variates
Jun 18, 2020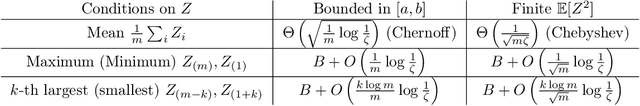
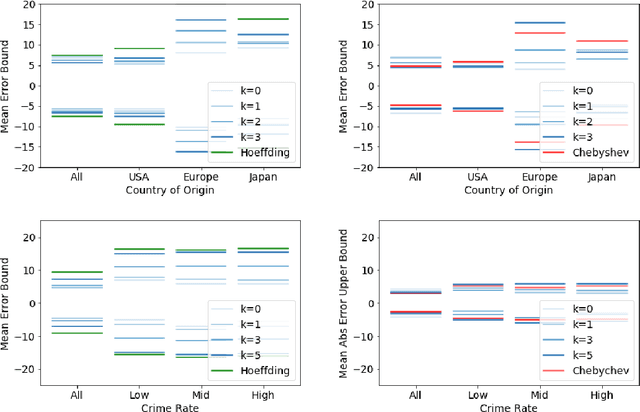

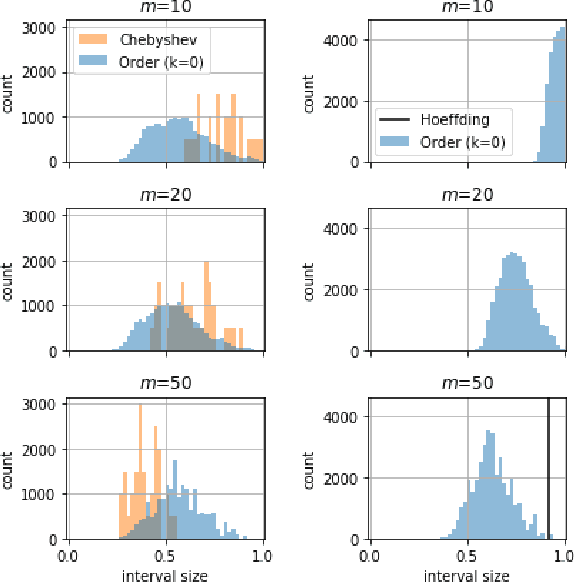
We consider the problem of estimating confidence intervals for the mean of a random variable, where the goal is to produce the smallest possible interval for a given number of samples. While minimax optimal algorithms are known for this problem in the general case, improved performance is possible under additional assumptions. In particular, we design an estimation algorithm to take advantage of side information in the form of a control variate, leveraging order statistics. Under certain conditions on the quality of the control variates, we show improved asymptotic efficiency compared to existing estimation algorithms. Empirically, we demonstrate superior performance on several real world surveying and estimation tasks where we use the output of regression models as the control variates.
Efficient Object Detection in Large Images using Deep Reinforcement Learning
Dec 09, 2019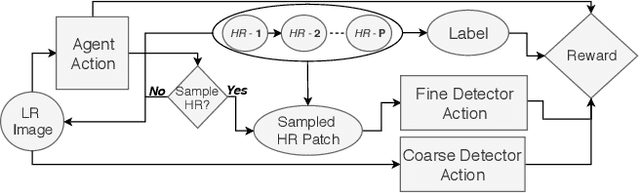

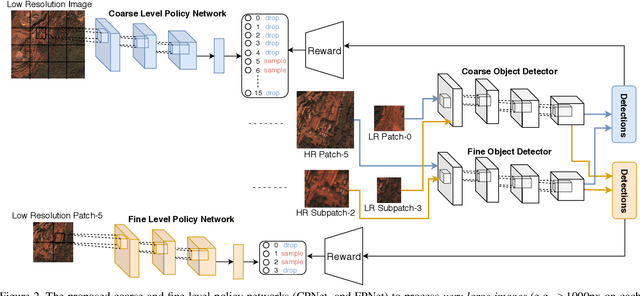
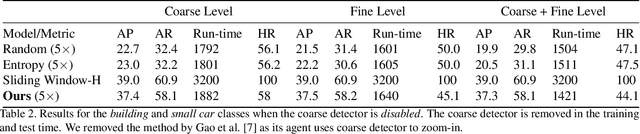
Traditionally, an object detector is applied to every part of the scene of interest, and its accuracy and computational cost increases with higher resolution images. However, in some application domains such as remote sensing, purchasing high spatial resolution images is expensive. To reduce the large computational and monetary cost associated with using high spatial resolution images, we propose a reinforcement learning agent that adaptively selects the spatial resolution of each image that is provided to the detector. In particular, we train the agent in a dual reward setting to choose low spatial resolution images to be run through a coarse level detector when the image is dominated by large objects, and high spatial resolution images to be run through a fine level detector when it is dominated by small objects. This reduces the dependency on high spatial resolution images for building a robust detector and increases run-time efficiency. We perform experiments on the xView dataset, consisting of large images, where we increase run-time efficiency by 50% and use high resolution images only 30% of the time while maintaining similar accuracy as a detector that uses only high resolution images.
Selection Via Proxy: Efficient Data Selection For Deep Learning
Jun 26, 2019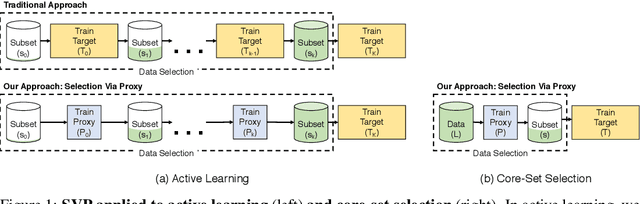
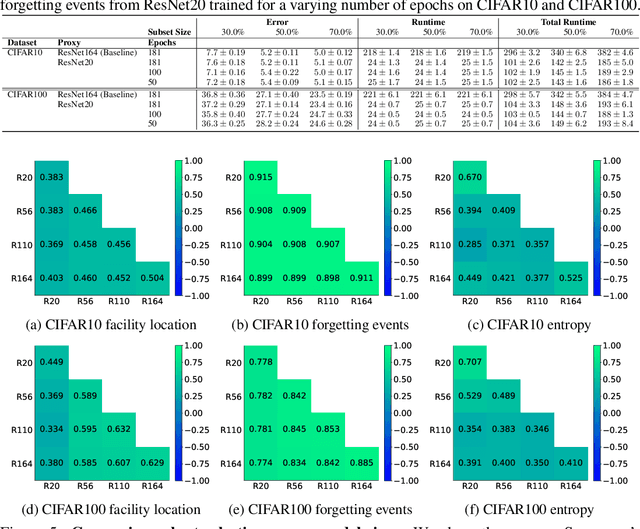
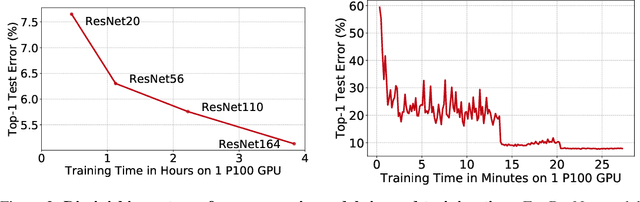
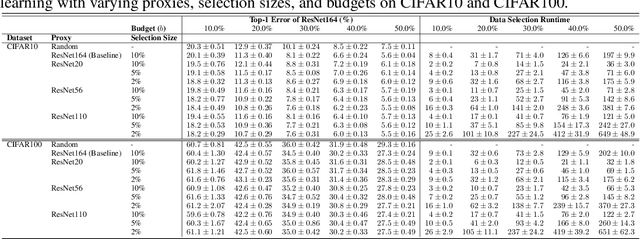
Data selection methods such as active learning and core-set selection are useful tools for machine learning on large datasets, but they can be prohibitively expensive to apply in deep learning. Unlike in other areas of machine learning, the feature representations that these techniques depend on are learned in deep learning rather than given, which takes a substantial amount of training time. In this work, we show that we can significantly improve the computational efficiency of data selection in deep learning by using a much smaller proxy model to perform data selection for tasks that will eventually require a large target model (e.g., selecting data points to label for active learning). In deep learning, we can scale down models by removing hidden layers or reducing their dimension to create proxies that are an order of magnitude faster. Although these small proxy models have significantly higher error, we find that they empirically provide useful rankings for data selection that have a high correlation with those of larger models. We evaluate this "selection via proxy" (SVP) approach on several data selection tasks. For active learning, applying SVP to Sener and Savarese [2018]'s recent method for active learning in deep learning gives a 4x improvement in execution time while yielding the same model accuracy. For core-set selection, we show that a proxy model that trains 10x faster than a target ResNet164 model on CIFAR10 can be used to remove 50% of the training data without compromising the accuracy of the target model, making end-to-end training time improvements via core-set selection possible.
Poverty Prediction with Public Landsat 7 Satellite Imagery and Machine Learning
Nov 10, 2017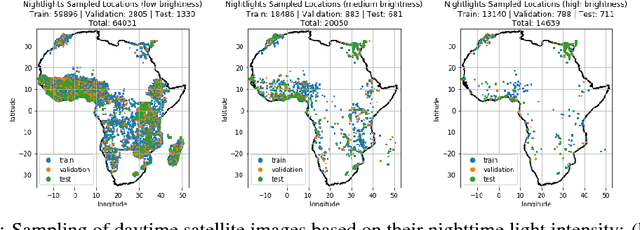
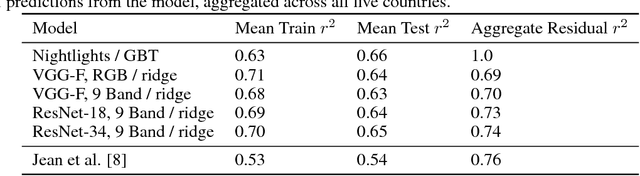
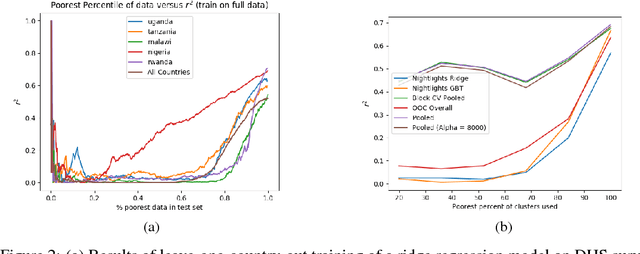
Obtaining detailed and reliable data about local economic livelihoods in developing countries is expensive, and data are consequently scarce. Previous work has shown that it is possible to measure local-level economic livelihoods using high-resolution satellite imagery. However, such imagery is relatively expensive to acquire, often not updated frequently, and is mainly available for recent years. We train CNN models on free and publicly available multispectral daytime satellite images of the African continent from the Landsat 7 satellite, which has collected imagery with global coverage for almost two decades. We show that despite these images' lower resolution, we can achieve accuracies that exceed previous benchmarks.