 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpixels algorithms through network community detection
Aug 27, 2023Community detection is a powerful tool from complex networks analysis that finds applications in various research areas. Several image segmentation methods rely for instance on community detection algorithms as a black box in order to compute undersegmentations, i.e. a small number of regions that represent areas of interest of the image. However, to the best of our knowledge, the efficiency of such an approach w.r.t. superpixels, that aim at representing the image at a smaller level while preserving as much as possible original information, has been neglected so far. The only related work seems to be the one by Liu et. al. (IET Image Processing, 2022) that developed a superpixels algorithm using a so-called modularity maximization approach, leading to relevant results. We follow this line of research by studying the efficiency of superpixels computed by state-of-the-art community detection algorithms on a 4-connected pixel graph, so-called pixel-grid. We first detect communities on such a graph and then apply a simple merging procedure that allows to obtain the desired number of superpixels. As we shall see, such methods result in the computation of relevant superpixels as emphasized by both qualitative and quantitative experiments, according to different widely-used metrics based on ground-truth comparison or on superpixels only. We observe that the choice of the community detection algorithm has a great impact on the number of communities and hence on the merging procedure. Similarly, small variations on the pixel-grid may provide different results from both qualitative and quantitative viewpoints. For the sake of completeness, we compare our results with those of several state-of-the-art superpixels algorithms as computed by Stutz et al. (Computer Vision and Image Understanding, 2018).
Semi-Supervised Multitask Learning on Multispectral Satellite Images Using Wasserstein Generative Adversarial Networks (GANs) for Predicting Poverty
Feb 13, 2019
Obtaining reliable data describing local poverty metrics at a granularity that is informative to policy-makers requires expensive and logistically difficult surveys, particularly in the developing world. Not surprisingly, the poverty stricken regions are also the ones which have a high probability of being a war zone, have poor infrastructure and sometimes have governments that do not cooperate with internationally funded development efforts. We train a CNN on free and publicly available daytime satellite images of the African continent from Landsat 7 to build a model for predicting local economic livelihoods. Only 5% of the satellite images can be associated with labels (which are obtained from DHS Surveys) and thus a semi-supervised approach using a GAN (similar to the approach of Salimans, et al. (2016)), albeit with a more stable-to-train flavor of GANs called the Wasserstein GAN regularized with gradient penalty(Gulrajani, et al. (2017)) is used. The method of multitask learning is employed to regularize the network and also create an end-to-end model for the prediction of multiple poverty metrics.
Poverty Prediction with Public Landsat 7 Satellite Imagery and Machine Learning
Nov 10, 2017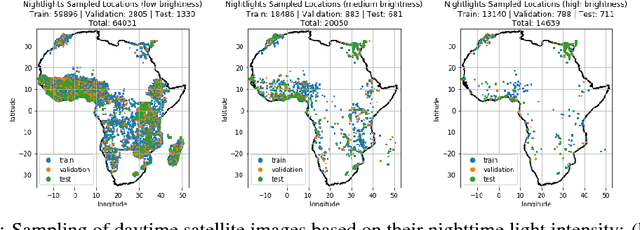
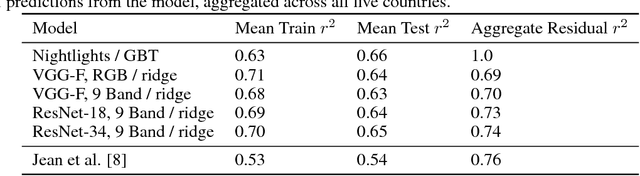
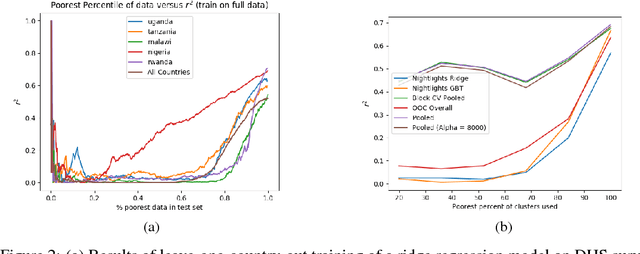
Obtaining detailed and reliable data about local economic livelihoods in developing countries is expensive, and data are consequently scarce. Previous work has shown that it is possible to measure local-level economic livelihoods using high-resolution satellite imagery. However, such imagery is relatively expensive to acquire, often not updated frequently, and is mainly available for recent years. We train CNN models on free and publicly available multispectral daytime satellite images of the African continent from the Landsat 7 satellite, which has collected imagery with global coverage for almost two decades. We show that despite these images' lower resolution, we can achieve accuracies that exceed previous benchmarks.