 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Online Distribution Shift Detection via Recency Prediction
Nov 17, 2022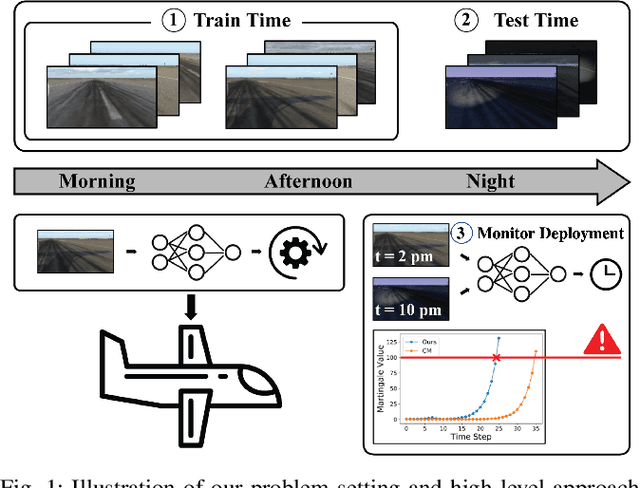

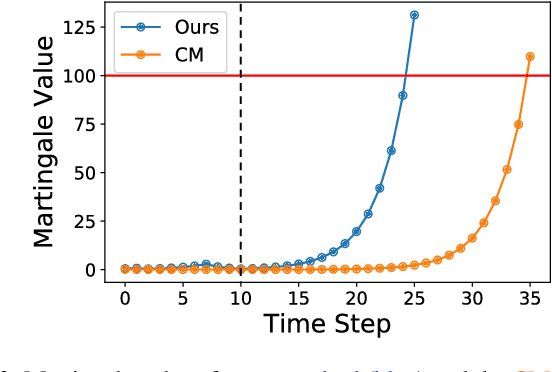

When deploying modern machine learning-enabled robotic systems in high-stakes applications, detecting distribution shift is critical. However, most existing methods for detecting distribution shift are not well-suited to robotics settings, where data often arrives in a streaming fashion and may be very high-dimensional. In this work, we present an online method for detecting distribution shift with guarantees on the false positive rate - i.e., when there is no distribution shift, our system is very unlikely (with probability $< \epsilon$) to falsely issue an alert; any alerts that are issued should therefore be heeded. Our method is specifically designed for efficient detection even with high dimensional data, and it empirically achieves up to 11x faster detection on realistic robotics settings compared to prior work while maintaining a low false negative rate in practice (whenever there is a distribution shift in our experiments, our method indeed emits an alert).
Generalizing Bayesian Optimization with Decision-theoretic Entropies
Oct 04, 2022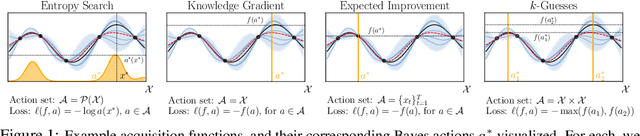
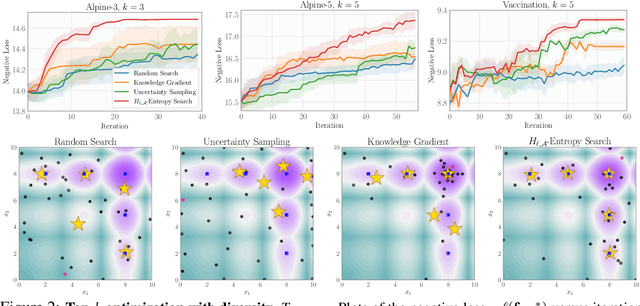
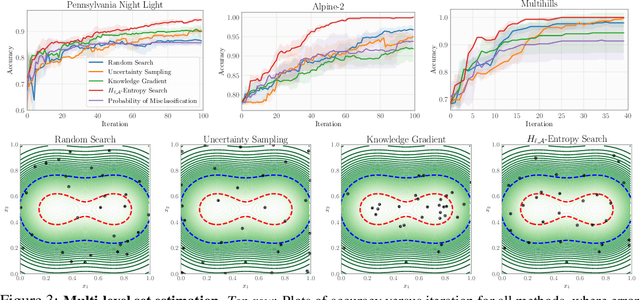
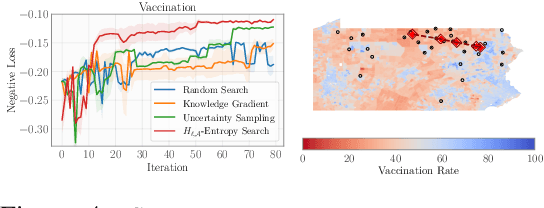
Bayesian optimization (BO) is a popular method for efficiently inferring optima of an expensive black-box function via a sequence of queries. Existing information-theoretic BO procedures aim to make queries that most reduce the uncertainty about optima, where the uncertainty is captured by Shannon entropy. However, an optimal measure of uncertainty would, ideally, factor in how we intend to use the inferred quantity in some downstream procedure. In this paper, we instead consider a generalization of Shannon entropy from work in statistical decision theory (DeGroot 1962, Rao 1984), which contains a broad class of uncertainty measures parameterized by a problem-specific loss function corresponding to a downstream task. We first show that special cases of this entropy lead to popular acquisition functions used in BO procedures such as knowledge gradient, expected improvement, and entropy search. We then show how alternative choices for the loss yield a flexible family of acquisition functions that can be customized for use in novel optimization settings. Additionally, we develop gradient-based methods to efficiently optimize our proposed family of acquisition functions, and demonstrate strong empirical performance on a diverse set of sequential decision making tasks, including variants of top-$k$ optimization, multi-level set estimation, and sequence search.
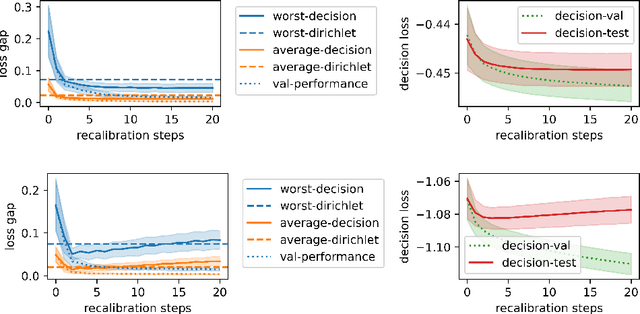
Modular Conformal Calibration
Jul 05, 2022

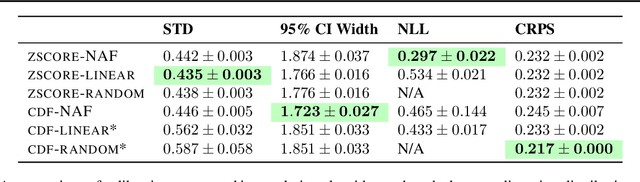

Uncertainty estimates must be calibrated (i.e., accurate) and sharp (i.e., informative) in order to be useful. This has motivated a variety of methods for recalibration, which use held-out data to turn an uncalibrated model into a calibrated model. However, the applicability of existing methods is limited due to their assumption that the original model is also a probabilistic model. We introduce a versatile class of algorithms for recalibration in regression that we call Modular Conformal Calibration (MCC). This framework allows one to transform any regression model into a calibrated probabilistic model. The modular design of MCC allows us to make simple adjustments to existing algorithms that enable well-behaved distribution predictions. We also provide finite-sample calibration guarantees for MCC algorithms. Our framework recovers isotonic recalibration, conformal calibration, and conformal interval prediction, implying that our theoretical results apply to those methods as well. Finally, we conduct an empirical study of MCC on 17 regression datasets. Our results show that new algorithms designed in our framework achieve near-perfect calibration and improve sharpness relative to existing methods.
Low-Degree Multicalibration
Mar 02, 2022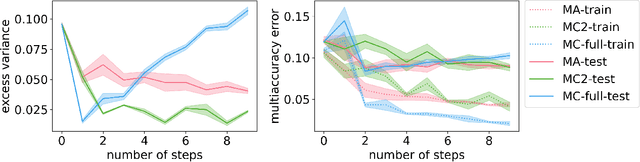
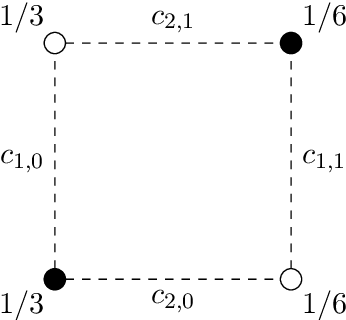
Introduced as a notion of algorithmic fairness, multicalibration has proved to be a powerful and versatile concept with implications far beyond its original intent. This stringent notion -- that predictions be well-calibrated across a rich class of intersecting subpopulations -- provides its strong guarantees at a cost: the computational and sample complexity of learning multicalibrated predictors are high, and grow exponentially with the number of class labels. In contrast, the relaxed notion of multiaccuracy can be achieved more efficiently, yet many of the most desirable properties of multicalibration cannot be guaranteed assuming multiaccuracy alone. This tension raises a key question: Can we learn predictors with multicalibration-style guarantees at a cost commensurate with multiaccuracy? In this work, we define and initiate the study of Low-Degree Multicalibration. Low-Degree Multicalibration defines a hierarchy of increasingly-powerful multi-group fairness notions that spans multiaccuracy and the original formulation of multicalibration at the extremes. Our main technical contribution demonstrates that key properties of multicalibration, related to fairness and accuracy, actually manifest as low-degree properties. Importantly, we show that low-degree multicalibration can be significantly more efficient than full multicalibration. In the multi-class setting, the sample complexity to achieve low-degree multicalibration improves exponentially (in the number of classes) over full multicalibration. Our work presents compelling evidence that low-degree multicalibration represents a sweet spot, pairing computational and sample efficiency with strong fairness and accuracy guarantees.
Sample-Efficient Safety Assurances using Conformal Prediction
Sep 28, 2021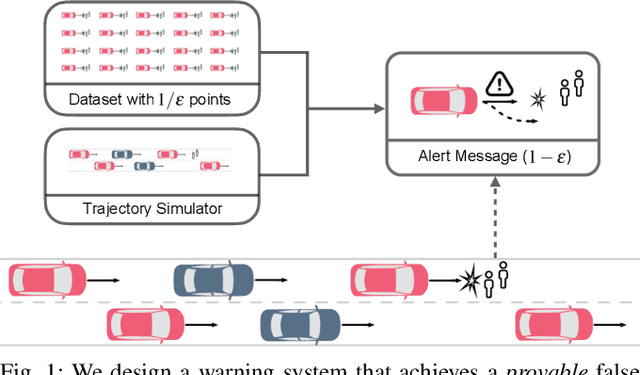
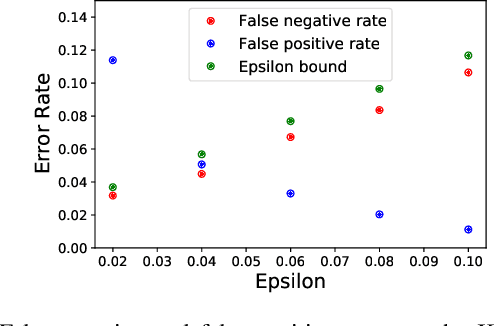
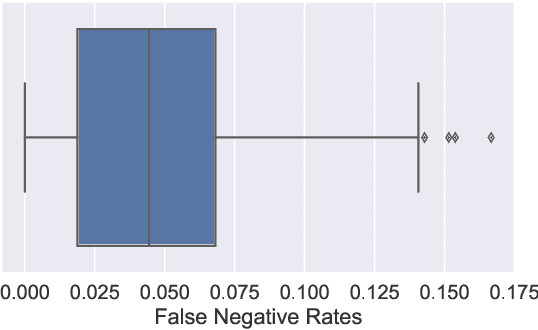
When deploying machine learning models in high-stakes robotics applications, the ability to detect unsafe situations is crucial. Early warning systems can provide alerts when an unsafe situation is imminent (in the absence of corrective action). To reliably improve safety, these warning systems should have a provable false negative rate; i.e. of the situations that are unsafe, fewer than $\epsilon$ will occur without an alert. In this work, we present a framework that combines a statistical inference technique known as conformal prediction with a simulator of robot/environment dynamics, in order to tune warning systems to provably achieve an $\epsilon$ false negative rate using as few as $1/\epsilon$ data points. We apply our framework to a driver warning system and a robotic grasping application, and empirically demonstrate guaranteed false negative rate and low false detection (positive) rate using very little data.
Calibrating Predictions to Decisions: A Novel Approach to Multi-Class Calibration
Jul 12, 2021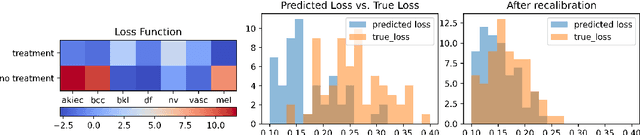


When facing uncertainty, decision-makers want predictions they can trust. A machine learning provider can convey confidence to decision-makers by guaranteeing their predictions are distribution calibrated -- amongst the inputs that receive a predicted class probabilities vector $q$, the actual distribution over classes is $q$. For multi-class prediction problems, however, achieving distribution calibration tends to be infeasible, requiring sample complexity exponential in the number of classes $C$. In this work, we introduce a new notion -- \emph{decision calibration} -- that requires the predicted distribution and true distribution to be ``indistinguishable'' to a set of downstream decision-makers. When all possible decision makers are under consideration, decision calibration is the same as distribution calibration. However, when we only consider decision makers choosing between a bounded number of actions (e.g. polynomial in $C$), our main result shows that decisions calibration becomes feasible -- we design a recalibration algorithm that requires sample complexity polynomial in the number of actions and the number of classes. We validate our recalibration algorithm empirically: compared to existing methods, decision calibration improves decision-making on skin lesion and ImageNet classification with modern neural network predictors.
Improved Autoregressive Modeling with Distribution Smoothing
Mar 28, 2021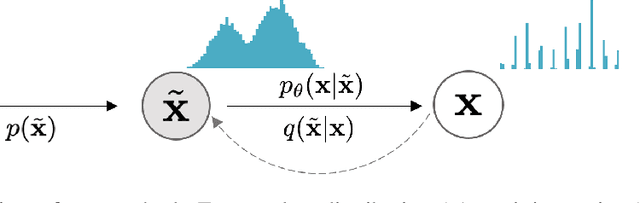


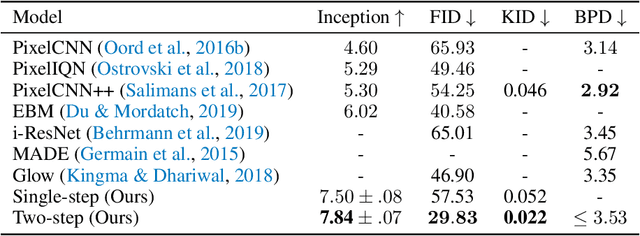
While autoregressive models excel at image compression, their sample quality is often lacking. Although not realistic, generated images often have high likelihood according to the model, resembling the case of adversarial examples. Inspired by a successful adversarial defense method, we incorporate randomized smoothing into autoregressive generative modeling. We first model a smoothed version of the data distribution, and then reverse the smoothing process to recover the original data distribution. This procedure drastically improves the sample quality of existing autoregressive models on several synthetic and real-world image datasets while obtaining competitive likelihoods on synthetic datasets.