 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Degree Multicalibration
Paper and Code
Mar 02, 2022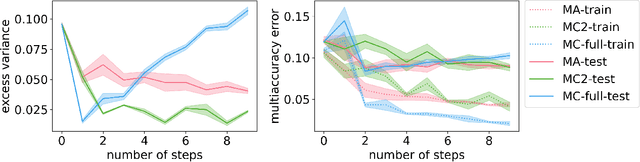
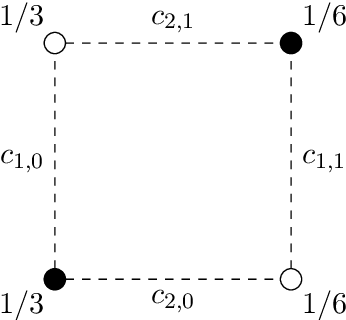
Introduced as a notion of algorithmic fairness, multicalibration has proved to be a powerful and versatile concept with implications far beyond its original intent. This stringent notion -- that predictions be well-calibrated across a rich class of intersecting subpopulations -- provides its strong guarantees at a cost: the computational and sample complexity of learning multicalibrated predictors are high, and grow exponentially with the number of class labels. In contrast, the relaxed notion of multiaccuracy can be achieved more efficiently, yet many of the most desirable properties of multicalibration cannot be guaranteed assuming multiaccuracy alone. This tension raises a key question: Can we learn predictors with multicalibration-style guarantees at a cost commensurate with multiaccuracy? In this work, we define and initiate the study of Low-Degree Multicalibration. Low-Degree Multicalibration defines a hierarchy of increasingly-powerful multi-group fairness notions that spans multiaccuracy and the original formulation of multicalibration at the extremes. Our main technical contribution demonstrates that key properties of multicalibration, related to fairness and accuracy, actually manifest as low-degree properties. Importantly, we show that low-degree multicalibration can be significantly more efficient than full multicalibration. In the multi-class setting, the sample complexity to achieve low-degree multicalibration improves exponentially (in the number of classes) over full multicalibration. Our work presents compelling evidence that low-degree multicalibration represents a sweet spot, pairing computational and sample efficiency with strong fairness and accuracy guarantees.