 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalized Calibration: Metrics and Recalibration
Paper and Code
Feb 22, 2021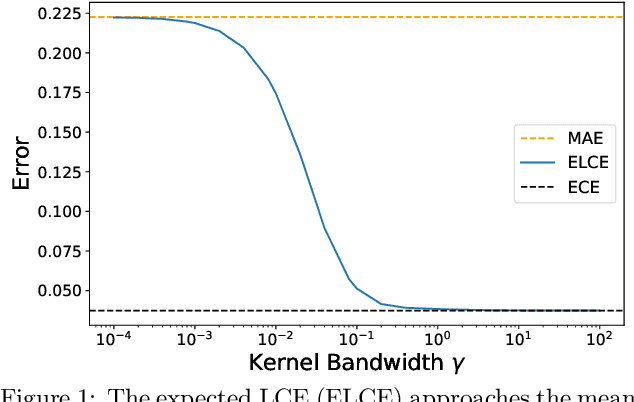
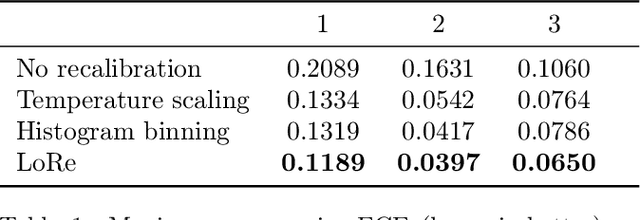
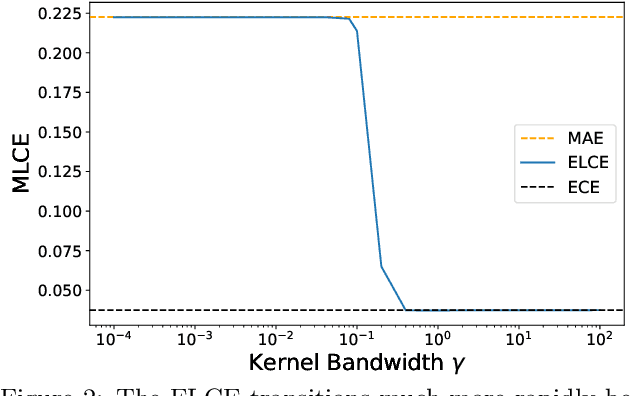
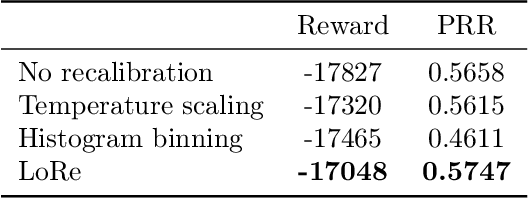
Probabilistic classifiers output confidence scores along with their predictions, and these confidence scores must be well-calibrated (i.e. reflect the true probability of an event) to be meaningful and useful for downstream tasks. However, existing metrics for measuring calibration are insufficient. Commonly used metrics such as the expected calibration error (ECE) only measure global trends, making them ineffective for measuring the calibration of a particular sample or subgroup. At the other end of the spectrum, a fully individualized calibration error is in general intractable to estimate from finite samples. In this work, we propose the local calibration error (LCE), a fine-grained calibration metric that spans the gap between fully global and fully individualized calibration. The LCE leverages learned features to automatically capture rich subgroups, and it measures the calibration error around each individual example via a similarity function. We then introduce a localized recalibration method, LoRe, that improves the LCE better than existing recalibration methods. Finally, we show that applying our recalibration method improves decision-making on downstream tasks.