 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOA: Pre-training Once for Models of All Sizes
Aug 02, 2024



Large-scale self-supervised pre-training has paved the way for one foundation model to handle many different vision tasks. Most pre-training methodologies train a single model of a certain size at one time. Nevertheless, various computation or storage constraints in real-world scenarios require substantial efforts to develop a series of models with different sizes to deploy. Thus, in this study, we propose a novel tri-branch self-supervised training framework, termed as POA (Pre-training Once for All), to tackle this aforementioned issue. Our approach introduces an innovative elastic student branch into a modern self-distillation paradigm. At each pre-training step, we randomly sample a sub-network from the original student to form the elastic student and train all branches in a self-distilling fashion. Once pre-trained, POA allows the extraction of pre-trained models of diverse sizes for downstream tasks. Remarkably, the elastic student facilitates the simultaneous pre-training of multiple models with different sizes, which also acts as an additional ensemble of models of various sizes to enhance representation learning. Extensive experiments, including k-nearest neighbors, linear probing evaluation and assessments on multiple downstream tasks demonstrate the effectiveness and advantages of our POA. It achieves state-of-the-art performance using ViT, Swin Transformer and ResNet backbones, producing around a hundred models with different sizes through a single pre-training session. The code is available at: https://github.com/Qichuzyy/POA.
SkySense: A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery
Dec 15, 2023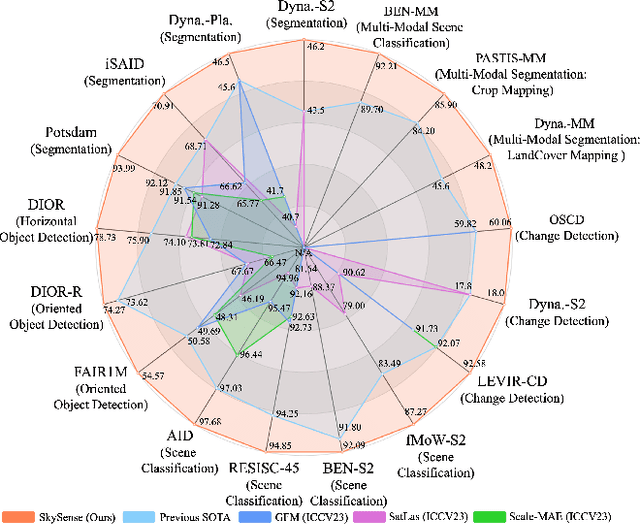
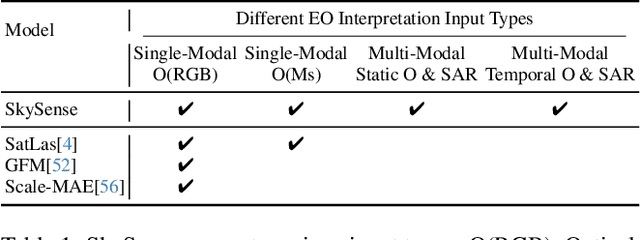
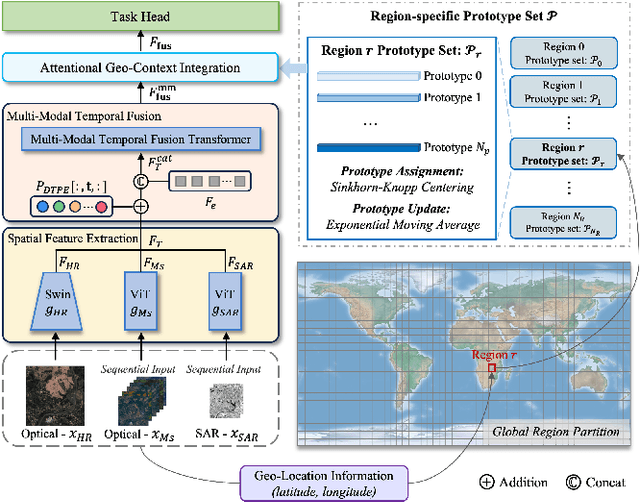
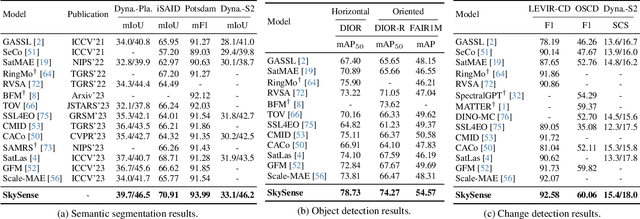
Prior studies on Remote Sensing Foundation Model (RSFM) reveal immense potential towards a generic model for Earth Observation. Nevertheless, these works primarily focus on a single modality without temporal and geo-context modeling, hampering their capabilities for diverse tasks. In this study, we present SkySense, a generic billion-scale model, pre-trained on a curated multi-modal Remote Sensing Imagery (RSI) dataset with 21.5 million temporal sequences. SkySense incorporates a factorized multi-modal spatiotemporal encoder taking temporal sequences of optical and Synthetic Aperture Radar (SAR) data as input. This encoder is pre-trained by our proposed Multi-Granularity Contrastive Learning to learn representations across different modal and spatial granularities. To further enhance the RSI representations by the geo-context clue, we introduce Geo-Context Prototype Learning to learn region-aware prototypes upon RSI's multi-modal spatiotemporal features. To our best knowledge, SkySense is the largest Multi-Modal RSFM to date, whose modules can be flexibly combined or used individually to accommodate various tasks. It demonstrates remarkable generalization capabilities on a thorough evaluation encompassing 16 datasets over 7 tasks, from single- to multi-modal, static to temporal, and classification to localization. SkySense surpasses 18 recent RSFMs in all test scenarios. Specifically, it outperforms the latest models such as GFM, SatLas and Scale-MAE by a large margin, i.e., 2.76%, 3.67% and 3.61% on average respectively. We will release the pre-trained weights to facilitate future research and Earth Observation applications.
Not All Negatives Are Worth Attending to: Meta-Bootstrapping Negative Sampling Framework for Link Prediction
Dec 12, 2023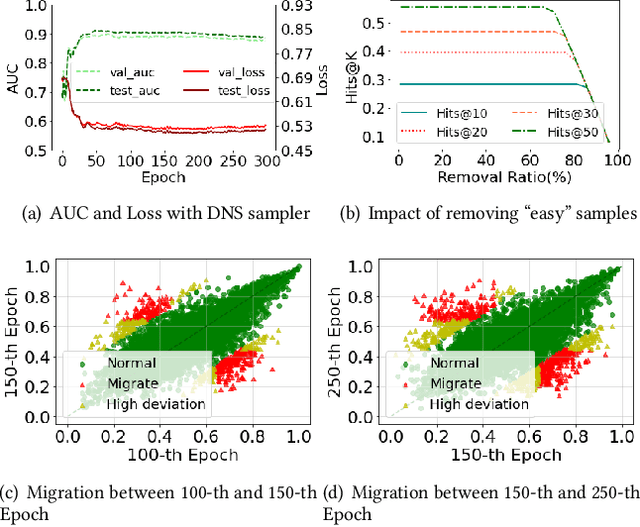
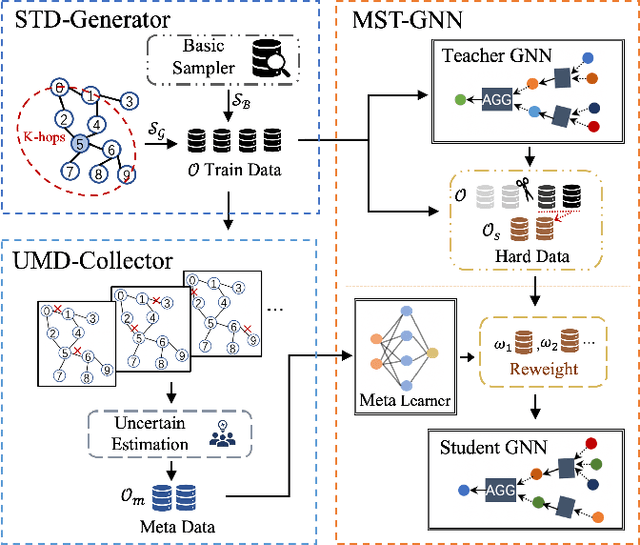
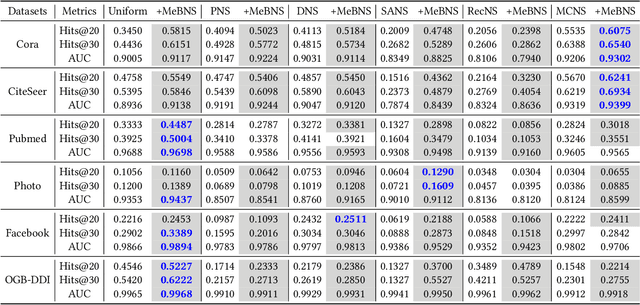
The rapid development of graph neural networks (GNNs) encourages the rising of link prediction, achieving promising performance with various applications. Unfortunately, through a comprehensive analysis, we surprisingly find that current link predictors with dynamic negative samplers (DNSs) suffer from the migration phenomenon between "easy" and "hard" samples, which goes against the preference of DNS of choosing "hard" negatives, thus severely hindering capability. Towards this end, we propose the MeBNS framework, serving as a general plugin that can potentially improve current negative sampling based link predictors. In particular, we elaborately devise a Meta-learning Supported Teacher-student GNN (MST-GNN) that is not only built upon teacher-student architecture for alleviating the migration between "easy" and "hard" samples but also equipped with a meta learning based sample re-weighting module for helping the student GNN distinguish "hard" samples in a fine-grained manner. To effectively guide the learning of MST-GNN, we prepare a Structure enhanced Training Data Generator (STD-Generator) and an Uncertainty based Meta Data Collector (UMD-Collector) for supporting the teacher and student GNN, respectively. Extensive experiments show that the MeBNS achieves remarkable performance across six link prediction benchmark datasets.