 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Negatives Are Worth Attending to: Meta-Bootstrapping Negative Sampling Framework for Link Prediction
Dec 12, 2023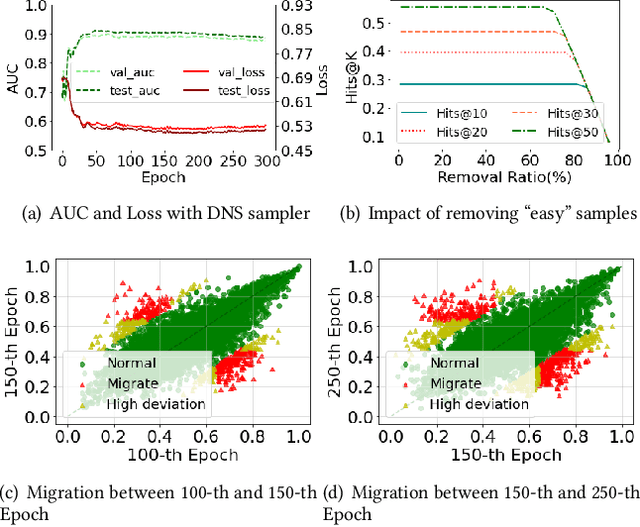
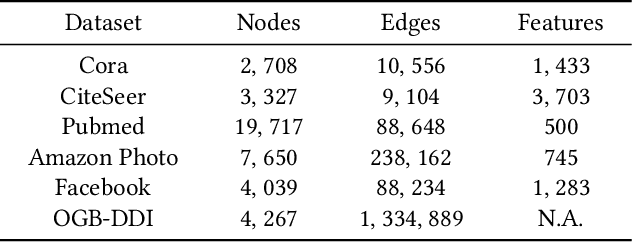
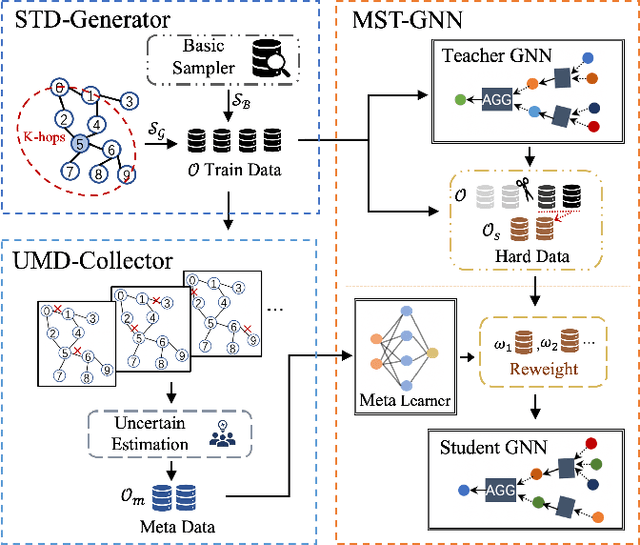
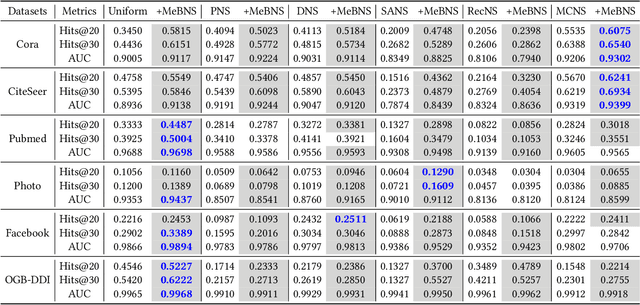
The rapid development of graph neural networks (GNNs) encourages the rising of link prediction, achieving promising performance with various applications. Unfortunately, through a comprehensive analysis, we surprisingly find that current link predictors with dynamic negative samplers (DNSs) suffer from the migration phenomenon between "easy" and "hard" samples, which goes against the preference of DNS of choosing "hard" negatives, thus severely hindering capability. Towards this end, we propose the MeBNS framework, serving as a general plugin that can potentially improve current negative sampling based link predictors. In particular, we elaborately devise a Meta-learning Supported Teacher-student GNN (MST-GNN) that is not only built upon teacher-student architecture for alleviating the migration between "easy" and "hard" samples but also equipped with a meta learning based sample re-weighting module for helping the student GNN distinguish "hard" samples in a fine-grained manner. To effectively guide the learning of MST-GNN, we prepare a Structure enhanced Training Data Generator (STD-Generator) and an Uncertainty based Meta Data Collector (UMD-Collector) for supporting the teacher and student GNN, respectively. Extensive experiments show that the MeBNS achieves remarkable performance across six link prediction benchmark datasets.
Interpreting and Unifying Graph Neural Networks with An Optimization Framework
Jan 28, 2021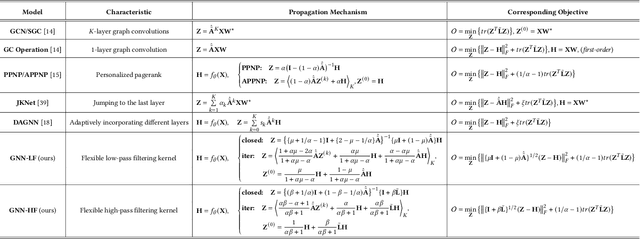
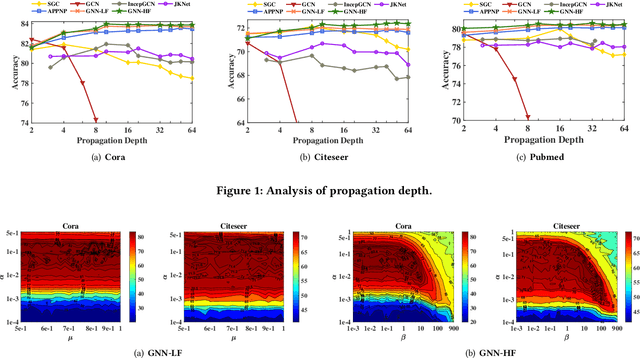
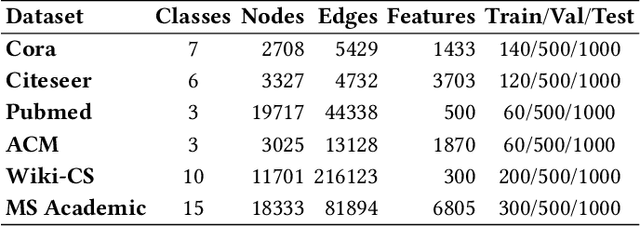
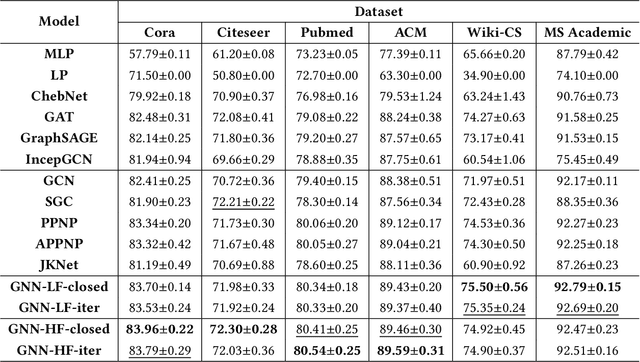
Graph Neural Networks (GNNs) have received considerable attention on graph-structured data learning for a wide variety of tasks. The well-designed propagation mechanism which has been demonstrated effective is the most fundamental part of GNNs. Although most of GNNs basically follow a message passing manner, litter effort has been made to discover and analyze their essential relations. In this paper, we establish a surprising connection between different propagation mechanisms with a unified optimization problem, showing that despite the proliferation of various GNNs, in fact, their proposed propagation mechanisms are the optimal solution optimizing a feature fitting function over a wide class of graph kernels with a graph regularization term. Our proposed unified optimization framework, summarizing the commonalities between several of the most representative GNNs, not only provides a macroscopic view on surveying the relations between different GNNs, but also further opens up new opportunities for flexibly designing new GNNs. With the proposed framework, we discover that existing works usually utilize naive graph convolutional kernels for feature fitting function, and we further develop two novel objective functions considering adjustable graph kernels showing low-pass or high-pass filtering capabilities respectively. Moreover, we provide the convergence proofs and expressive power comparisons for the proposed models. Extensive experiments on benchmark datasets clearly show that the proposed GNNs not only outperform the state-of-the-art methods but also have good ability to alleviate over-smoothing, and further verify the feasibility for designing GNNs with our unified optimization framework.
AM-GCN: Adaptive Multi-channel Graph Convolutional Networks
Jul 11, 2020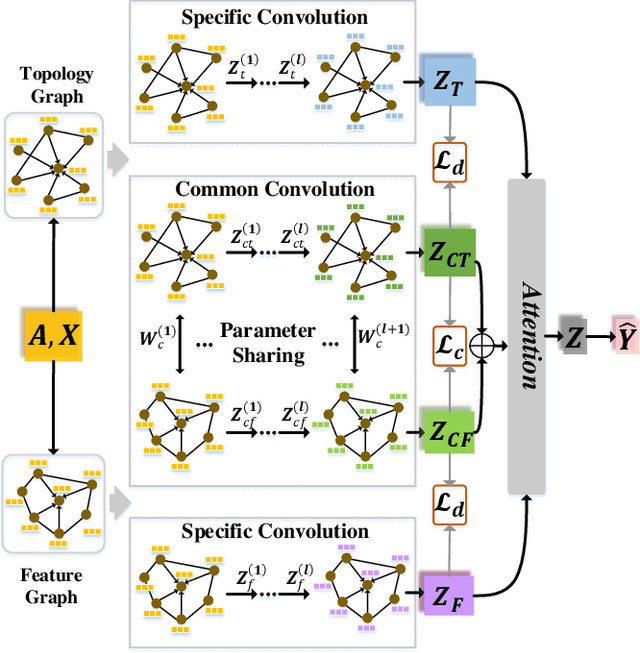
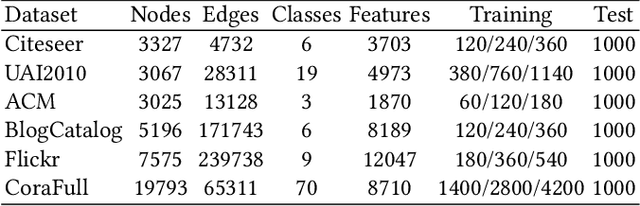


Graph Convolutional Networks (GCNs) have gained great popularity in tackling various analytics tasks on graph and network data. However, some recent studies raise concerns about whether GCNs can optimally integrate node features and topological structures in a complex graph with rich information. In this paper, we first present an experimental investigation. Surprisingly, our experimental results clearly show that the capability of the state-of-the-art GCNs in fusing node features and topological structures is distant from optimal or even satisfactory. The weakness may severely hinder the capability of GCNs in some classification tasks, since GCNs may not be able to adaptively learn some deep correlation information between topological structures and node features. Can we remedy the weakness and design a new type of GCNs that can retain the advantages of the state-of-the-art GCNs and, at the same time, enhance the capability of fusing topological structures and node features substantially? We tackle the challenge and propose an adaptive multi-channel graph convolutional networks for semi-supervised classification (AM-GCN). The central idea is that we extract the specific and common embeddings from node features, topological structures, and their combinations simultaneously, and use the attention mechanism to learn adaptive importance weights of the embeddings. Our extensive experiments on benchmark data sets clearly show that AM-GCN extracts the most correlated information from both node features and topological structures substantially, and improves the classification accuracy with a clear margin.
Structural Deep Clustering Network
Feb 12, 2020
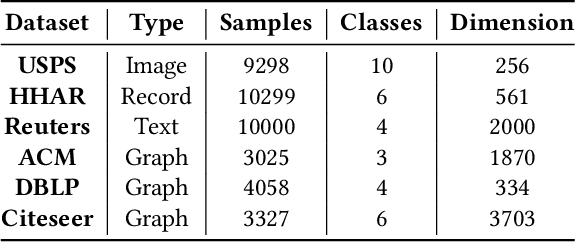


Clustering is a fundamental task in data analysis. Recently, deep clustering, which derives inspiration primarily from deep learning approaches, achieves state-of-the-art performance and has attracted considerable attention. Current deep clustering methods usually boost the clustering results by means of the powerful representation ability of deep learning, e.g., autoencoder, suggesting that learning an effective representation for clustering is a crucial requirement. The strength of deep clustering methods is to extract the useful representations from the data itself, rather than the structure of data, which receives scarce attention in representation learning. Motivated by the great success of Graph Convolutional Network (GCN) in encoding the graph structure, we propose a Structural Deep Clustering Network (SDCN) to integrate the structural information into deep clustering. Specifically, we design a delivery operator to transfer the representations learned by autoencoder to the corresponding GCN layer, and a dual self-supervised mechanism to unify these two different deep neural architectures and guide the update of the whole model. In this way, the multiple structures of data, from low-order to high-order, are naturally combined with the multiple representations learned by autoencoder. Furthermore, we theoretically analyze the delivery operator, i.e., with the delivery operator, GCN improves the autoencoder-specific representation as a high-order graph regularization constraint and autoencoder helps alleviate the over-smoothing problem in GCN. Through comprehensive experiments, we demonstrate that our propose model can consistently perform better over the state-of-the-art techniques.