 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhys4D: Fine-Grained Physics-Consistent 4D Modeling from Video Diffusion
Mar 03, 2026Recent video diffusion models have achieved impressive capabilities as large-scale generative world models. However, these models often struggle with fine-grained physical consistency, exhibiting physically implausible dynamics over time. In this work, we present \textbf{Phys4D}, a pipeline for learning physics-consistent 4D world representations from video diffusion models. Phys4D adopts \textbf{a three-stage training paradigm} that progressively lifts appearance-driven video diffusion models into physics-consistent 4D world representations. We first bootstrap robust geometry and motion representations through large-scale pseudo-supervised pretraining, establishing a foundation for 4D scene modeling. We then perform physics-grounded supervised fine-tuning using simulation-generated data, enforcing temporally consistent 4D dynamics. Finally, we apply simulation-grounded reinforcement learning to correct residual physical violations that are difficult to capture through explicit supervision. To evaluate fine-grained physical consistency beyond appearance-based metrics, we introduce a set of \textbf{4D world consistency evaluation} that probe geometric coherence, motion stability, and long-horizon physical plausibility. Experimental results demonstrate that Phys4D substantially improves fine-grained spatiotemporal and physical consistency compared to appearance-driven baselines, while maintaining strong generative performance. Our project page is available at https://sensational-brioche-7657e7.netlify.app/
Learning Structure-Semantic Evolution Trajectories for Graph Domain Adaptation
Feb 11, 2026Graph Domain Adaptation (GDA) aims to bridge distribution shifts between domains by transferring knowledge from well-labeled source graphs to given unlabeled target graphs. One promising recent approach addresses graph transfer by discretizing the adaptation process, typically through the construction of intermediate graphs or stepwise alignment procedures. However, such discrete strategies often fail in real-world scenarios, where graph structures evolve continuously and nonlinearly, making it difficult for fixed-step alignment to approximate the actual transformation process. To address these limitations, we propose \textbf{DiffGDA}, a \textbf{Diff}usion-based \textbf{GDA} method that models the domain adaptation process as a continuous-time generative process. We formulate the evolution from source to target graphs using stochastic differential equations (SDEs), enabling the joint modeling of structural and semantic transitions. To guide this evolution, a domain-aware network is introduced to steer the generative process toward the target domain, encouraging the diffusion trajectory to follow an optimal adaptation path. We theoretically show that the diffusion process converges to the optimal solution bridging the source and target domains in the latent space. Extensive experiments on 14 graph transfer tasks across 8 real-world datasets demonstrate DiffGDA consistently outperforms state-of-the-art baselines.
Learning to Feel the Future: DreamTacVLA for Contact-Rich Manipulation
Dec 29, 2025Vision-Language-Action (VLA) models have shown remarkable generalization by mapping web-scale knowledge to robotic control, yet they remain blind to physical contact. Consequently, they struggle with contact-rich manipulation tasks that require reasoning about force, texture, and slip. While some approaches incorporate low-dimensional tactile signals, they fail to capture the high-resolution dynamics essential for such interactions. To address this limitation, we introduce DreamTacVLA, a framework that grounds VLA models in contact physics by learning to feel the future. Our model adopts a hierarchical perception scheme in which high-resolution tactile images serve as micro-vision inputs coupled with wrist-camera local vision and third-person macro vision. To reconcile these multi-scale sensory streams, we first train a unified policy with a Hierarchical Spatial Alignment (HSA) loss that aligns tactile tokens with their spatial counterparts in the wrist and third-person views. To further deepen the model's understanding of fine-grained contact dynamics, we finetune the system with a tactile world model that predicts future tactile signals. To mitigate tactile data scarcity and the wear-prone nature of tactile sensors, we construct a hybrid large-scale dataset sourced from both high-fidelity digital twin and real-world experiments. By anticipating upcoming tactile states, DreamTacVLA acquires a rich model of contact physics and conditions its actions on both real observations and imagined consequences. Across contact-rich manipulation tasks, it outperforms state-of-the-art VLA baselines, achieving up to 95% success, highlighting the importance of understanding physical contact for robust, touch-aware robotic agents.
Fast and Low-Cost Genomic Foundation Models via Outlier Removal
May 01, 2025We propose the first unified adversarial attack benchmark for Genomic Foundation Models (GFMs), named GERM. Unlike existing GFM benchmarks, GERM offers the first comprehensive evaluation framework to systematically assess the vulnerability of GFMs to adversarial attacks. Methodologically, we evaluate the adversarial robustness of five state-of-the-art GFMs using four widely adopted attack algorithms and three defense strategies. Importantly, our benchmark provides an accessible and comprehensive framework to analyze GFM vulnerabilities with respect to model architecture, quantization schemes, and training datasets. Empirically, transformer-based models exhibit greater robustness to adversarial perturbations compared to HyenaDNA, highlighting the impact of architectural design on vulnerability. Moreover, adversarial attacks frequently target biologically significant genomic regions, suggesting that these models effectively capture meaningful sequence features.
Smoothness Really Matters: A Simple yet Effective Approach for Unsupervised Graph Domain Adaptation
Dec 16, 2024



Unsupervised Graph Domain Adaptation (UGDA) seeks to bridge distribution shifts between domains by transferring knowledge from labeled source graphs to given unlabeled target graphs. Existing UGDA methods primarily focus on aligning features in the latent space learned by graph neural networks (GNNs) across domains, often overlooking structural shifts, resulting in limited effectiveness when addressing structurally complex transfer scenarios. Given the sensitivity of GNNs to local structural features, even slight discrepancies between source and target graphs could lead to significant shifts in node embeddings, thereby reducing the effectiveness of knowledge transfer. To address this issue, we introduce a novel approach for UGDA called Target-Domain Structural Smoothing (TDSS). TDSS is a simple and effective method designed to perform structural smoothing directly on the target graph, thereby mitigating structural distribution shifts and ensuring the consistency of node representations. Specifically, by integrating smoothing techniques with neighborhood sampling, TDSS maintains the structural coherence of the target graph while mitigating the risk of over-smoothing. Our theoretical analysis shows that TDSS effectively reduces target risk by improving model smoothness. Empirical results on three real-world datasets demonstrate that TDSS outperforms recent state-of-the-art baselines, achieving significant improvements across six transfer scenarios. The code is available in https://github.com/cwei01/TDSS.
POA: Pre-training Once for Models of All Sizes
Aug 02, 2024



Large-scale self-supervised pre-training has paved the way for one foundation model to handle many different vision tasks. Most pre-training methodologies train a single model of a certain size at one time. Nevertheless, various computation or storage constraints in real-world scenarios require substantial efforts to develop a series of models with different sizes to deploy. Thus, in this study, we propose a novel tri-branch self-supervised training framework, termed as POA (Pre-training Once for All), to tackle this aforementioned issue. Our approach introduces an innovative elastic student branch into a modern self-distillation paradigm. At each pre-training step, we randomly sample a sub-network from the original student to form the elastic student and train all branches in a self-distilling fashion. Once pre-trained, POA allows the extraction of pre-trained models of diverse sizes for downstream tasks. Remarkably, the elastic student facilitates the simultaneous pre-training of multiple models with different sizes, which also acts as an additional ensemble of models of various sizes to enhance representation learning. Extensive experiments, including k-nearest neighbors, linear probing evaluation and assessments on multiple downstream tasks demonstrate the effectiveness and advantages of our POA. It achieves state-of-the-art performance using ViT, Swin Transformer and ResNet backbones, producing around a hundred models with different sizes through a single pre-training session. The code is available at: https://github.com/Qichuzyy/POA.
Not All Negatives Are Worth Attending to: Meta-Bootstrapping Negative Sampling Framework for Link Prediction
Dec 12, 2023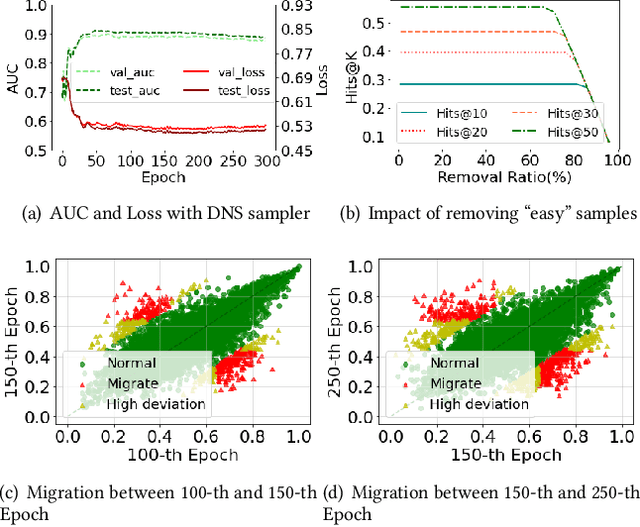
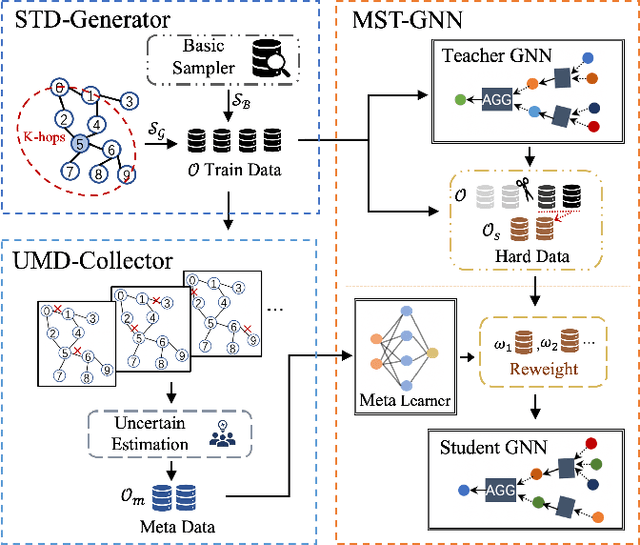
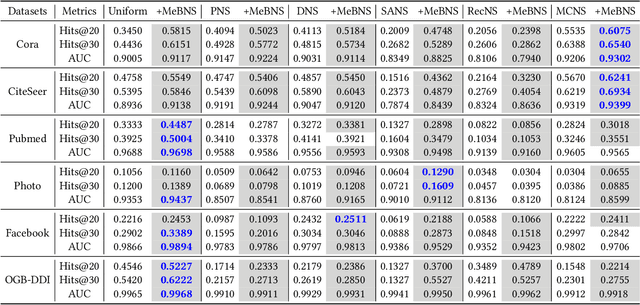
The rapid development of graph neural networks (GNNs) encourages the rising of link prediction, achieving promising performance with various applications. Unfortunately, through a comprehensive analysis, we surprisingly find that current link predictors with dynamic negative samplers (DNSs) suffer from the migration phenomenon between "easy" and "hard" samples, which goes against the preference of DNS of choosing "hard" negatives, thus severely hindering capability. Towards this end, we propose the MeBNS framework, serving as a general plugin that can potentially improve current negative sampling based link predictors. In particular, we elaborately devise a Meta-learning Supported Teacher-student GNN (MST-GNN) that is not only built upon teacher-student architecture for alleviating the migration between "easy" and "hard" samples but also equipped with a meta learning based sample re-weighting module for helping the student GNN distinguish "hard" samples in a fine-grained manner. To effectively guide the learning of MST-GNN, we prepare a Structure enhanced Training Data Generator (STD-Generator) and an Uncertainty based Meta Data Collector (UMD-Collector) for supporting the teacher and student GNN, respectively. Extensive experiments show that the MeBNS achieves remarkable performance across six link prediction benchmark datasets.
Learning to Infer Belief Embedded Communication
Mar 15, 2022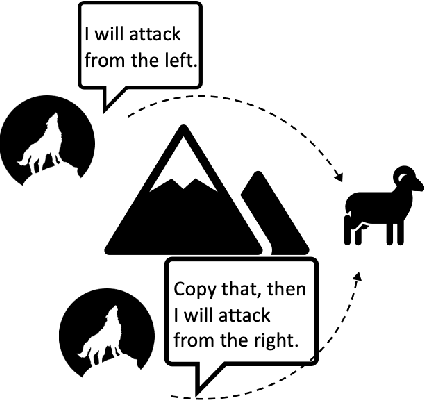
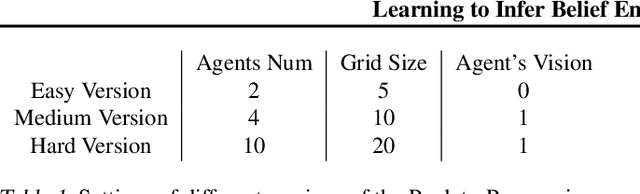
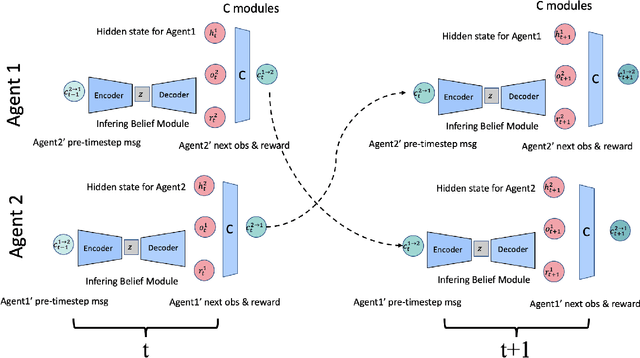
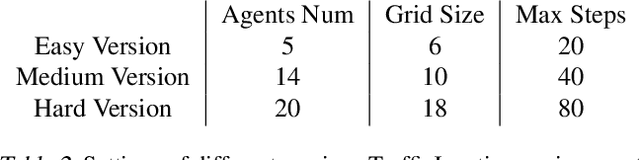
In multi-agent collaboration problems with communication, an agent's ability to encode their intention and interpret other agents' strategies is critical for planning their future actions. This paper introduces a novel algorithm called Intention Embedded Communication (IEC) to mimic an agent's language learning ability. IEC contains a perception module for decoding other agents' intentions in response to their past actions. It also includes a language generation module for learning implicit grammar during communication with two or more agents. Such grammar, by construction, should be compact for efficient communication. Both modules undergo conjoint evolution - similar to an infant's babbling that enables it to learn a language of choice by trial and error. We utilised three multi-agent environments, namely predator/prey, traffic junction and level-based foraging and illustrate that such a co-evolution enables us to learn much quicker (50%) than state-of-the-art algorithms like MADDPG. Ablation studies further show that disabling the inferring belief module, communication module, and the hidden states reduces the model performance by 38%, 60% and 30%, respectively. Hence, we suggest that modelling other agents' behaviour accelerates another agent to learn grammar and develop a language to communicate efficiently. We evaluate our method on a set of cooperative scenarios and show its superior performance to other multi-agent baselines. We also demonstrate that it is essential for agents to reason about others' states and learn this ability by continuous communication.