 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing DETRs Variants through Improved Content Query and Similar Query Aggregation
May 06, 2024
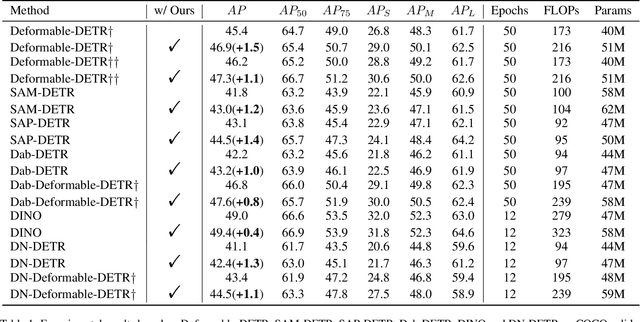
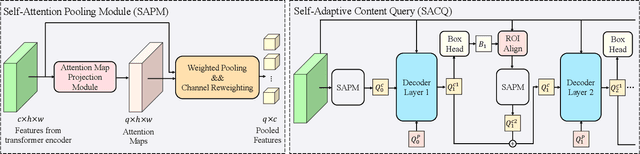
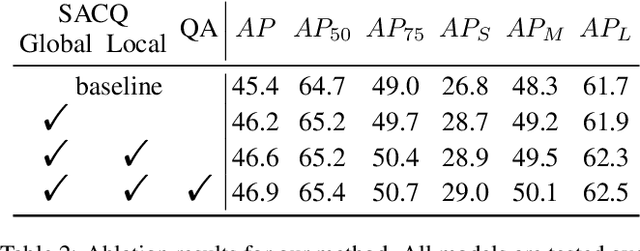
The design of the query is crucial for the performance of DETR and its variants. Each query consists of two components: a content part and a positional one. Traditionally, the content query is initialized with a zero or learnable embedding, lacking essential content information and resulting in sub-optimal performance. In this paper, we introduce a novel plug-and-play module, Self-Adaptive Content Query (SACQ), to address this limitation. The SACQ module utilizes features from the transformer encoder to generate content queries via self-attention pooling. This allows candidate queries to adapt to the input image, resulting in a more comprehensive content prior and better focus on target objects. However, this improved concentration poses a challenge for the training process that utilizes the Hungarian matching, which selects only a single candidate and suppresses other similar ones. To overcome this, we propose a query aggregation strategy to cooperate with SACQ. It merges similar predicted candidates from different queries, easing the optimization. Our extensive experiments on the COCO dataset demonstrate the effectiveness of our proposed approaches across six different DETR's variants with multiple configurations, achieving an average improvement of over 1.0 AP.
Multimodal Urban Areas of Interest Generation via Remote Sensing Imagery and Geographical Prior
Jan 31, 2024



Urban area-of-interest (AOI) refers to an integrated urban functional zone with defined boundaries. The rapid development of urban commerce has resulted in an increased demand for more precise requirements in defining AOIs. However, existing research primarily concentrates on broad AOI mining for urban planning or regional economic analysis, failing to cater to the precise requirements of mobile Internet online-to-offline businesses. These businesses necessitate accuracy down to a specific community, school, or hospital. In this paper, we propose an end-to-end multimodal deep learning algorithm for detecting AOI fence polygon using remote sensing images and multi-semantics reference information. We then evaluate its timeliness through a cascaded module that incorporates dynamic human mobility and logistics address information. Specifically, we begin by selecting a point-of-interest (POI) of specific category, and use it to recall corresponding remote sensing images, nearby POIs, road nodes, human mobility, and logistics addresses to build a multimodal detection model based on transformer encoder-decoder architecture, titled AOITR. In the model, in addition to the remote sensing images, multi-semantic information including core POI and road nodes is embedded and reorganized as the query content part for the transformer decoder to generate the AOI polygon. Meanwhile, relatively dynamic distribution features of human mobility, nearby POIs, and logistics addresses are used for AOI reliability evaluation through a cascaded feedforward network. The experimental results demonstrate that our algorithm significantly outperforms two existing methods.
Token-free LLMs Can Generate Chinese Classical Poetry with More Accurate Format
Jan 09, 2024Finetuned large language models (such as ChatGPT and Qwen-chat) can generate Chinese classical poetry following human's instructions. LLMs perform well in content, but are usually lacking in format, with occasionally excess or insufficient number of characters in each line. Since most SOTA LLMs are token-based, we assume that the format inaccuracy is due to the difficulty of the "token planning" task, which means that the LLM need to know exactly how much characters are contained in each token and do length-control planning based on that knowledge. In this paper, we first confirm our assumption by showing that existing token-based large language models has limited knowledge on token-character relationship. We use a spelling bee probing procedure, and find that Qwen-chat failed in nearly 15% Chinese spelling test. We then show that a token-based model can be easily tailored into a token-free model (in terms of Chinese), which can largely solve the format accuracy problem. Our tailoring procedure removes long-tokens from the vocabulary and the language model head, and keeps only character-level or byte-level tokens. As part of our contribution, we release the finetuned token-free model (which is based on Qwen-chat-7B), which can generate chinese classical poetry following complex instructions like LLMs (such as story paraphrasing), and also perform well in format. On the test set, our token-free model achives an format accuracy of 0.96, compared to 0.84 for token-based equivalents and 0.38 for GPT-4.