 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compacted Structure for Cross-domain learning on Monocular Depth and Flow Estimation
Aug 25, 2022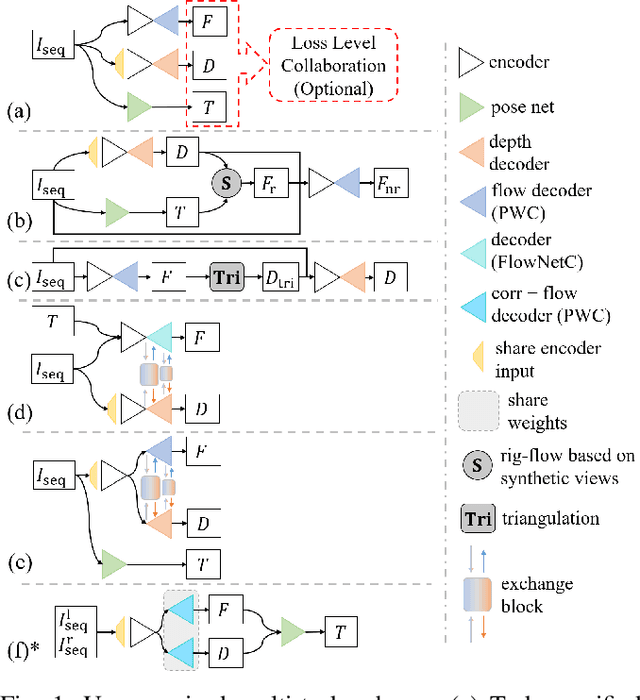
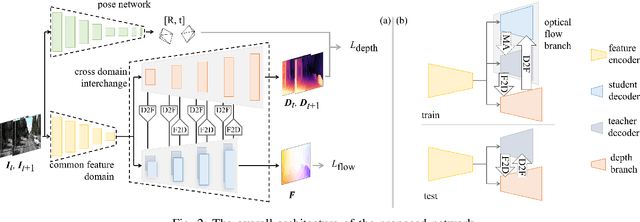
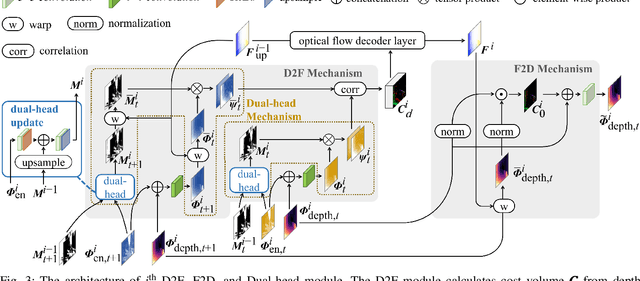
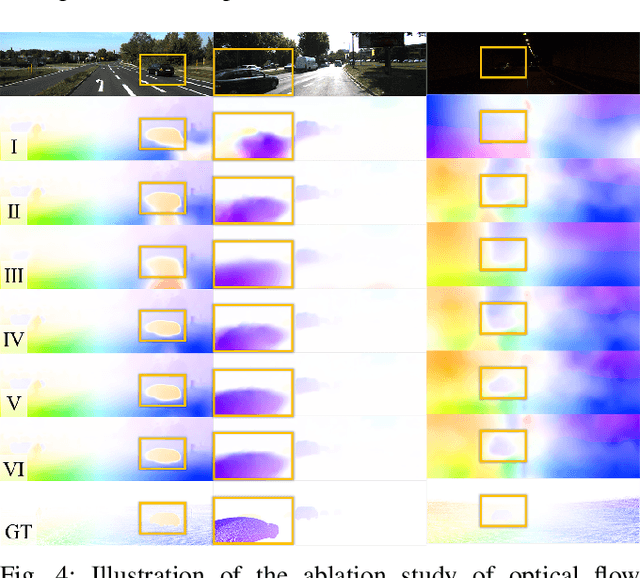
Accurate motion and depth recovery is important for many robot vision tasks including autonomous driving. Most previous studies have achieved cooperative multi-task interaction via either pre-defined loss functions or cross-domain prediction. This paper presents a multi-task scheme that achieves mutual assistance by means of our Flow to Depth (F2D), Depth to Flow (D2F), and Exponential Moving Average (EMA). F2D and D2F mechanisms enable multi-scale information integration between optical flow and depth domain based on differentiable shallow nets. A dual-head mechanism is used to predict optical flow for rigid and non-rigid motion based on a divide-and-conquer manner, which significantly improves the optical flow estimation performance. Furthermore, to make the prediction more robust and stable, EMA is used for our multi-task training. Experimental results on KITTI datasets show that our multi-task scheme outperforms other multi-task schemes and provide marked improvements on the prediction results.
A deep learning pipeline for localization, differentiation, and uncertainty estimation of liver lesions using multi-phasic and multi-sequence MRI
Oct 17, 2021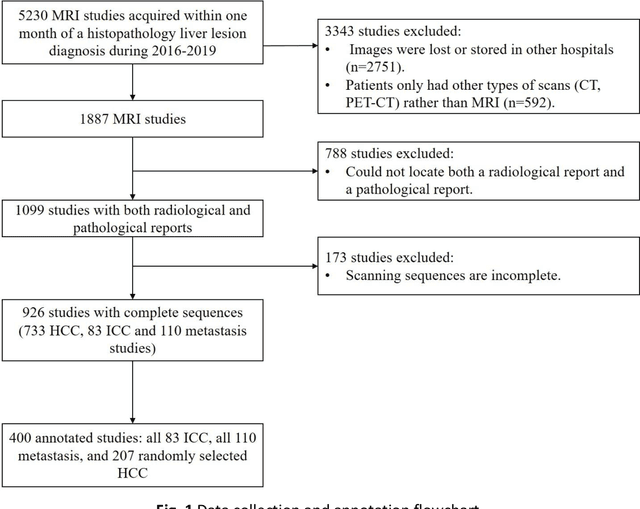
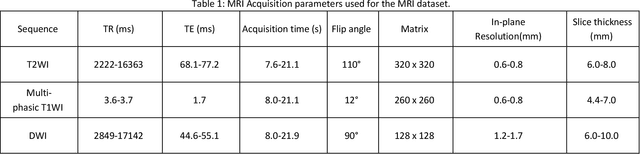
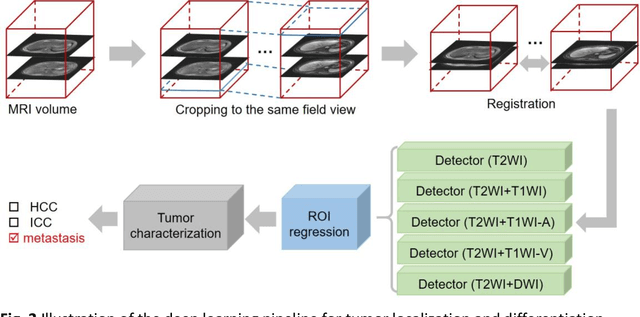
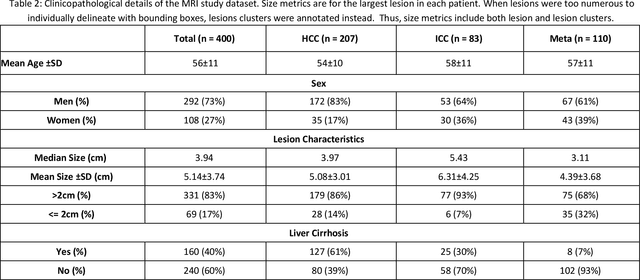
Objectives: to propose a fully-automatic computer-aided diagnosis (CAD) solution for liver lesion characterization, with uncertainty estimation. Methods: we enrolled 400 patients who had either liver resection or a biopsy and was diagnosed with either hepatocellular carcinoma (HCC), intrahepatic cholangiocarcinoma, or secondary metastasis, from 2006 to 2019. Each patient was scanned with T1WI, T2WI, T1WI venous phase (T2WI-V), T1WI arterial phase (T1WI-A), and DWI MRI sequences. We propose a fully-automatic deep CAD pipeline that localizes lesions from 3D MRI studies using key-slice parsing and provides a confidence measure for its diagnoses. We evaluate using five-fold cross validation and compare performance against three radiologists, including a senior hepatology radiologist, a junior hepatology radiologist and an abdominal radiologist. Results: the proposed CAD solution achieves a mean F1 score of 0.62, outperforming the abdominal radiologist (0.47), matching the junior hepatology radiologist (0.61), and underperforming the senior hepatology radiologist (0.68). The CAD system can informatively assess its diagnostic confidence, i.e., when only evaluating on the 70% most confident cases the mean f1 score and sensitivity at 80% specificity for HCC vs. others are boosted from 0.62 to 0.71 and 0.84 to 0.92, respectively. Conclusion: the proposed fully-automatic CAD solution can provide good diagnostic performance with informative confidence assessments in finding and discriminating liver lesions from MRI studies.
VeniBot: Towards Autonomous Venipuncture with Automatic Puncture Area and Angle Regression from NIR Images
May 27, 2021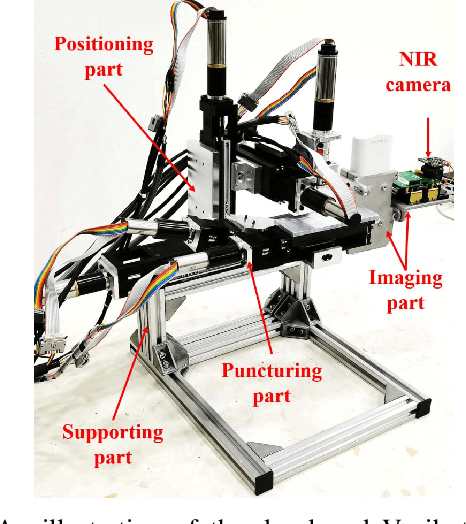
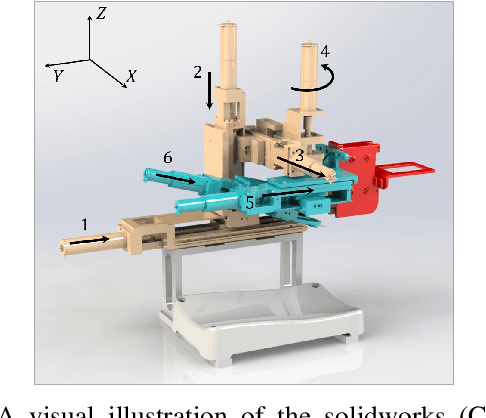
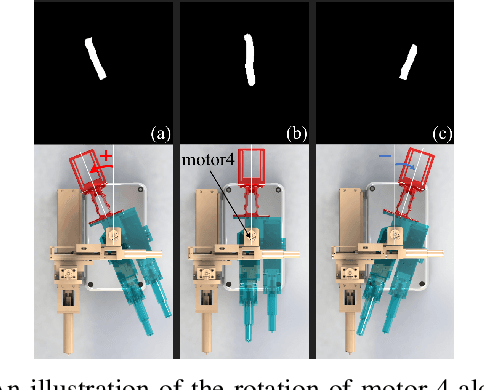
Venipucture is a common step in clinical scenarios, and is with highly practical value to be automated with robotics. Nowadays, only a few on-shelf robotic systems are developed, however, they can not fulfill practical usage due to varied reasons. In this paper, we develop a compact venipucture robot -- VeniBot, with four parts, six motors and two imaging devices. For the automation, we focus on the positioning part and propose a Dual-In-Dual-Out network based on two-step learning and two-task learning, which can achieve fully automatic regression of the suitable puncture area and angle from near-infrared(NIR) images. The regressed suitable puncture area and angle can further navigate the positioning part of VeniBot, which is an important step towards a fully autonomous venipucture robot. Validation on 30 VeniBot-collected volunteers shows a high mean dice coefficient(DSC) of 0.7634 and a low angle error of 15.58{\deg} on suitable puncture area and angle regression respectively, indicating its potentially wide and practical application in the future.
VeniBot: Towards Autonomous Venipuncture with Semi-supervised Vein Segmentation from Ultrasound Images
May 27, 2021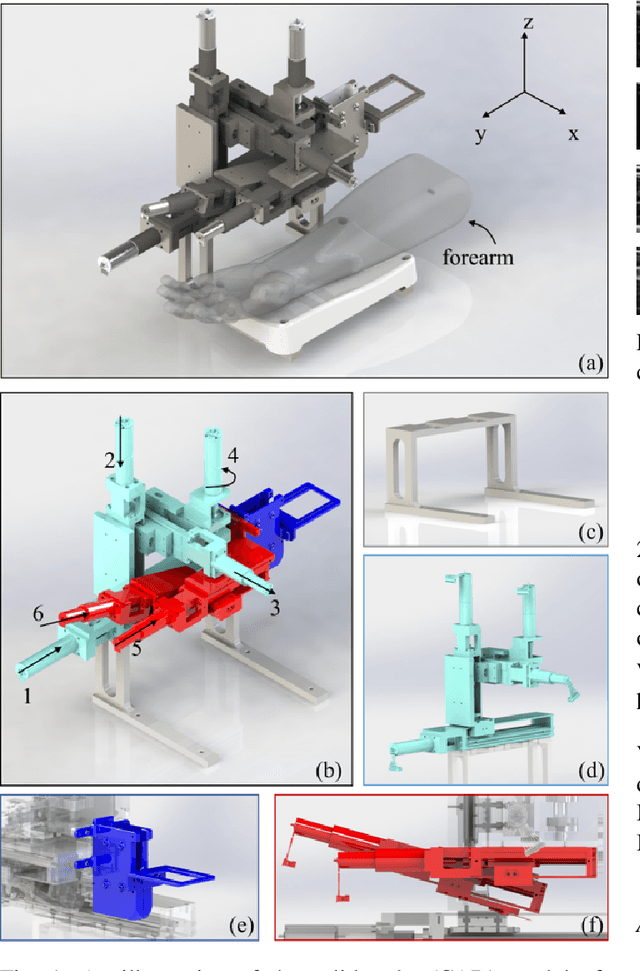
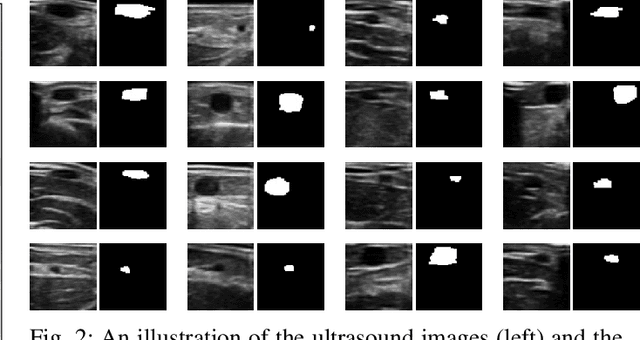
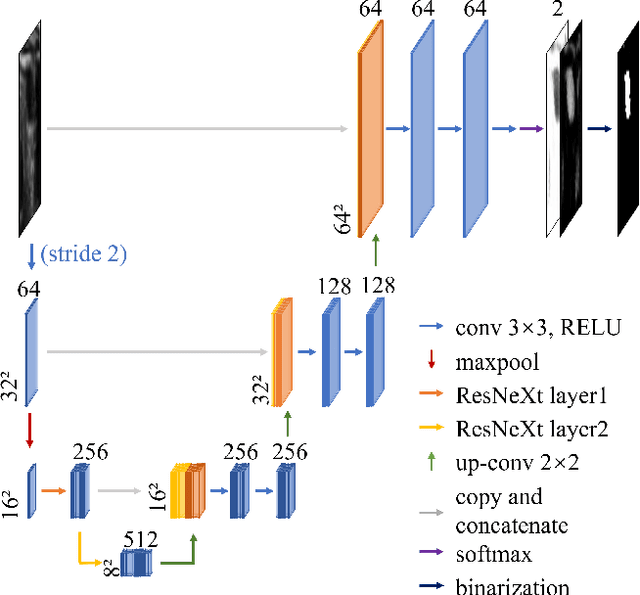
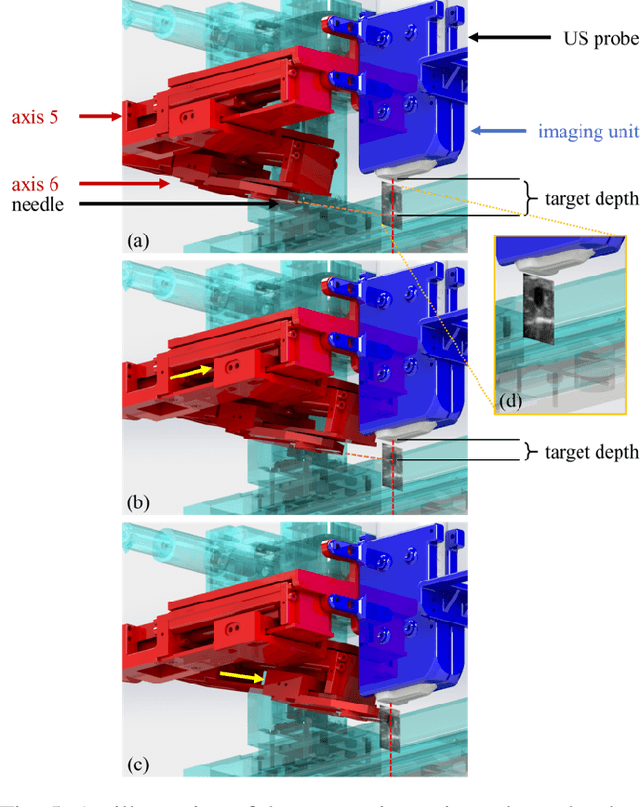
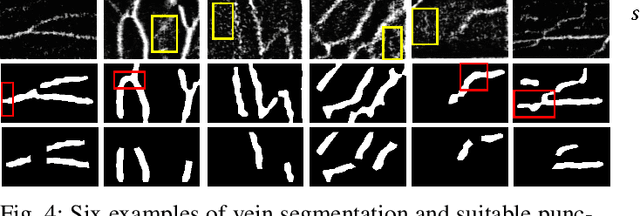
In the modern medical care, venipuncture is an indispensable procedure for both diagnosis and treatment. In this paper, unlike existing solutions that fully or partially rely on professional assistance, we propose VeniBot -- a compact robotic system solution integrating both novel hardware and software developments. For the hardware, we design a set of units to facilitate the supporting, positioning, puncturing and imaging functionalities. For the software, to move towards a full automation, we propose a novel deep learning framework -- semi-ResNeXt-Unet for semi-supervised vein segmentation from ultrasound images. From which, the depth information of vein is calculated and used to enable automated navigation for the puncturing unit. VeniBot is validated on 40 volunteers, where ultrasound images can be collected successfully. For the vein segmentation validation, the proposed semi-ResNeXt-Unet improves the dice similarity coefficient (DSC) by 5.36%, decreases the centroid error by 1.38 pixels and decreases the failure rate by 5.60%, compared to fully-supervised ResNeXt-Unet.
Scalable Semi-supervised Landmark Localization for X-ray Images using Few-shot Deep Adaptive Graph
Apr 29, 2021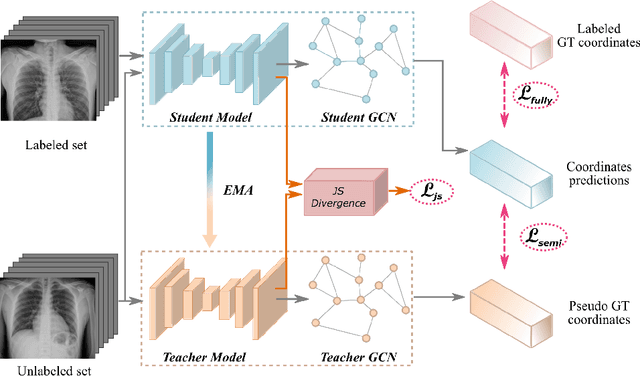
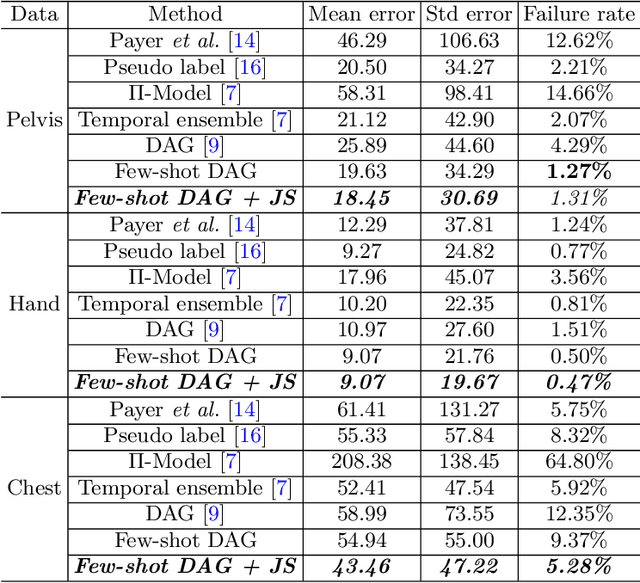

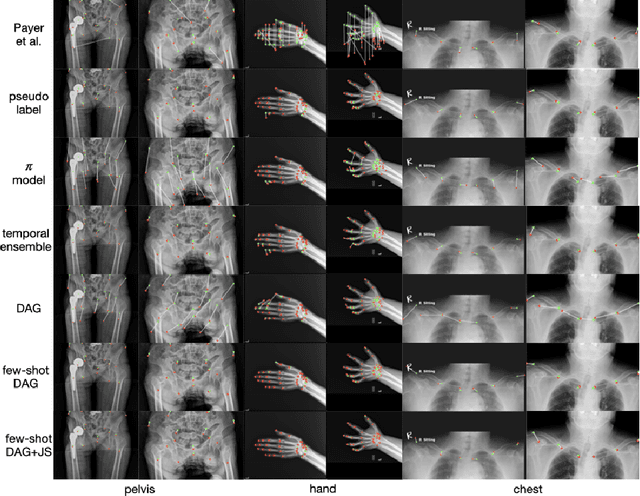
Landmark localization plays an important role in medical image analysis. Learning based methods, including CNN and GCN, have demonstrated the state-of-the-art performance. However, most of these methods are fully-supervised and heavily rely on manual labeling of a large training dataset. In this paper, based on a fully-supervised graph-based method, DAG, we proposed a semi-supervised extension of it, termed few-shot DAG, \ie five-shot DAG. It first trains a DAG model on the labeled data and then fine-tunes the pre-trained model on the unlabeled data with a teacher-student SSL mechanism. In addition to the semi-supervised loss, we propose another loss using JS divergence to regulate the consistency of the intermediate feature maps. We extensively evaluated our method on pelvis, hand and chest landmark detection tasks. Our experiment results demonstrate consistent and significant improvements over previous methods.
Hetero-Modal Learning and Expansive Consistency Constraints for Semi-Supervised Detection from Multi-Sequence Data
Mar 24, 2021

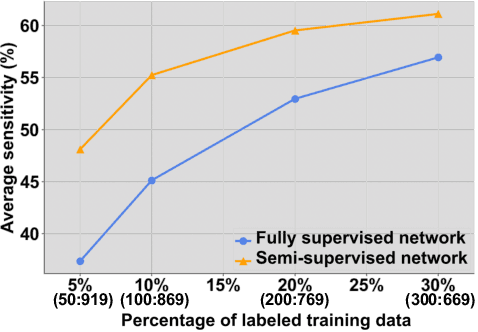
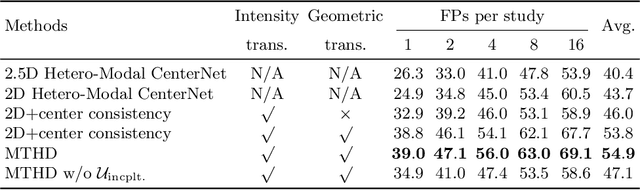
Lesion detection serves a critical role in early diagnosis and has been well explored in recent years due to methodological advancesand increased data availability. However, the high costs of annotations hinder the collection of large and completely labeled datasets, motivating semi-supervised detection approaches. In this paper, we introduce mean teacher hetero-modal detection (MTHD), which addresses two important gaps in current semi-supervised detection. First, it is not obvious how to enforce unlabeled consistency constraints across the very different outputs of various detectors, which has resulted in various compromises being used in the state of the art. Using an anchor-free framework, MTHD formulates a mean teacher approach without such compromises, enforcing consistency on the soft-output of object centers and size. Second, multi-sequence data is often critical, e.g., for abdominal lesion detection, but unlabeled data is often missing sequences. To deal with this, MTHD incorporates hetero-modal learning in its framework. Unlike prior art, MTHD is able to incorporate an expansive set of consistency constraints that include geometric transforms and random sequence combinations. We train and evaluate MTHD on liver lesion detection using the largest MR lesion dataset to date (1099 patients with >5000 volumes). MTHD surpasses the best fully-supervised and semi-supervised competitors by 10.1% and 3.5%, respectively, in average sensitivity.
Knowledge Distillation with Adaptive Asymmetric Label Sharpening for Semi-supervised Fracture Detection in Chest X-rays
Dec 30, 2020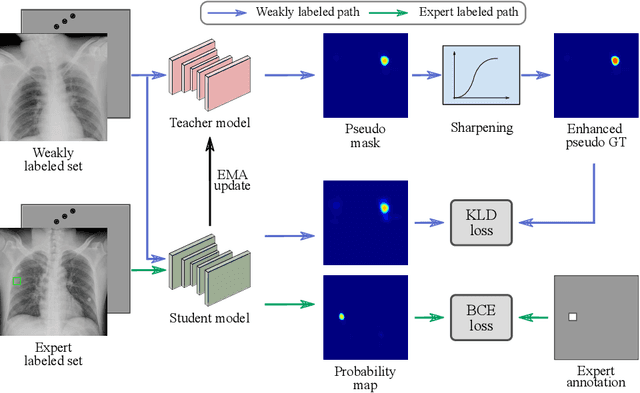
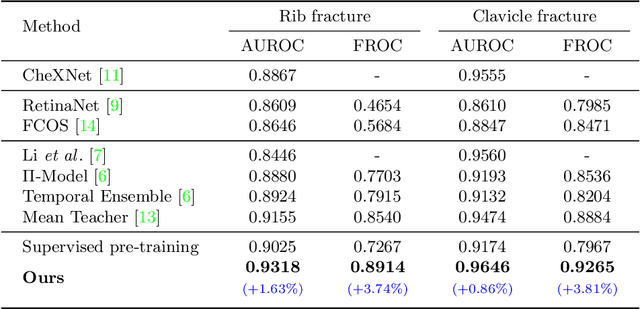
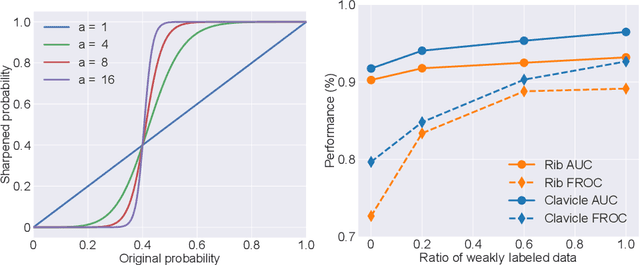
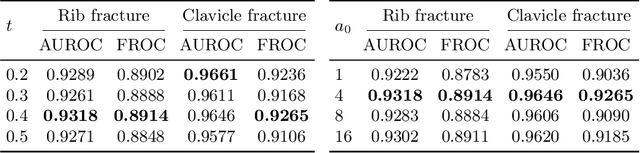
Exploiting available medical records to train high performance computer-aided diagnosis (CAD) models via the semi-supervised learning (SSL) setting is emerging to tackle the prohibitively high labor costs involved in large-scale medical image annotations. Despite the extensive attentions received on SSL, previous methods failed to 1) account for the low disease prevalence in medical records and 2) utilize the image-level diagnosis indicated from the medical records. Both issues are unique to SSL for CAD models. In this work, we propose a new knowledge distillation method that effectively exploits large-scale image-level labels extracted from the medical records, augmented with limited expert annotated region-level labels, to train a rib and clavicle fracture CAD model for chest X-ray (CXR). Our method leverages the teacher-student model paradigm and features a novel adaptive asymmetric label sharpening (AALS) algorithm to address the label imbalance problem that specially exists in medical domain. Our approach is extensively evaluated on all CXR (N = 65,845) from the trauma registry of anonymous hospital over a period of 9 years (2008-2016), on the most common rib and clavicle fractures. The experiment results demonstrate that our method achieves the state-of-the-art fracture detection performance, i.e., an area under receiver operating characteristic curve (AUROC) of 0.9318 and a free-response receiver operating characteristic (FROC) score of 0.8914 on the rib fractures, significantly outperforming previous approaches by an AUROC gap of 1.63% and an FROC improvement by 3.74%. Consistent performance gains are also observed for clavicle fracture detection.
Fully-Automated Liver Tumor Localization and Characterization from Multi-Phase MR Volumes Using Key-Slice ROI Parsing: A Physician-Inspired Approach
Dec 15, 2020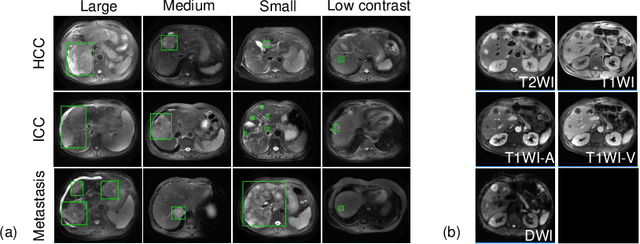
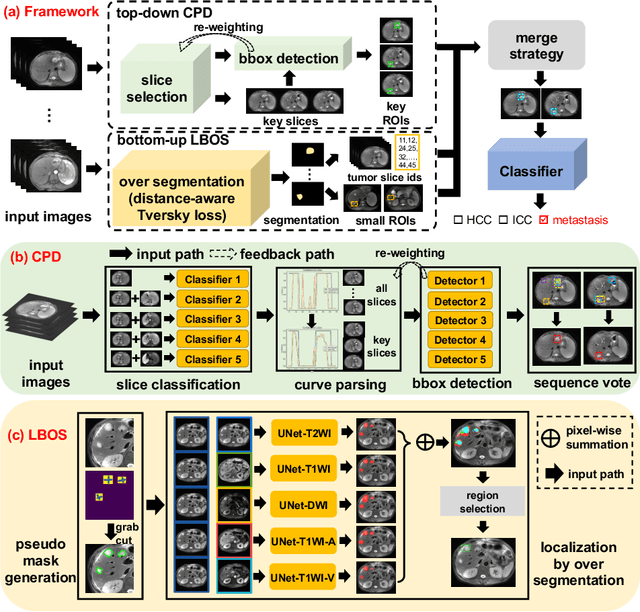
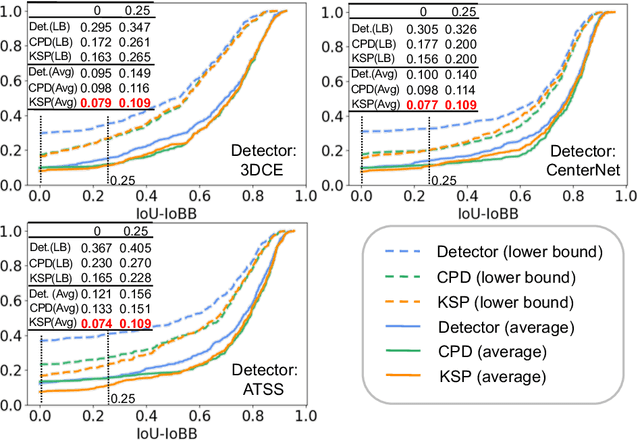
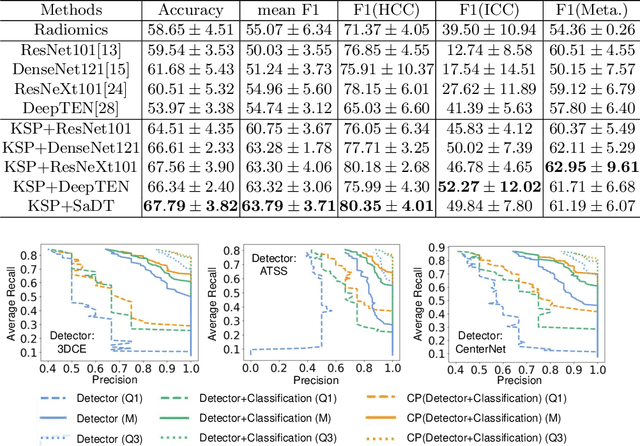
Using radiological scans to identify liver tumors is crucial for proper patient treatment. This is highly challenging, as top radiologists only achieve F1 scores of roughly 80% (hepatocellular carcinoma (HCC) vs. others) with only moderate inter-rater agreement, even when using multi-phase magnetic resonance (MR) imagery. Thus, there is great impetus for computer-aided diagnosis (CAD) solutions. A critical challengeis to reliably parse a 3D MR volume to localize diagnosable regions of interest (ROI). In this paper, we break down this problem using a key-slice parser (KSP), which emulates physician workflows by first identifying key slices and then localize their corresponding key ROIs. Because performance demands are so extreme, (not to miss any key ROI),our KSP integrates complementary modules--top-down classification-plus-detection (CPD) and bottom-up localization-by-over-segmentation(LBOS). The CPD uses a curve-parsing and detection confidence to re-weight classifier confidences. The LBOS uses over-segmentation to flag CPD failure cases and provides its own ROIs. For scalability, LBOS is only weakly trained on pseudo-masks using a new distance-aware Tversky loss. We evaluate our approach on the largest multi-phase MR liver lesion test dataset to date (430 biopsy-confirmed patients). Experiments demonstrate that our KSP can localize diagnosable ROIs with high reliability (85% patients have an average overlap of >= 40% with the ground truth). Moreover, we achieve an HCC vs. others F1 score of 0.804, providing a fully-automated CAD solution comparable with top human physicians.
Amata: An Annealing Mechanism for Adversarial Training Acceleration
Dec 15, 2020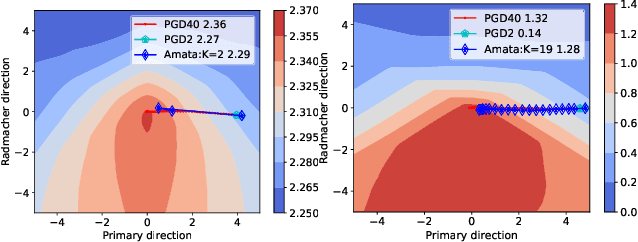



Despite the empirical success in various domains, it has been revealed that deep neural networks are vulnerable to maliciously perturbed input data that much degrade their performance. This is known as adversarial attacks. To counter adversarial attacks, adversarial training formulated as a form of robust optimization has been demonstrated to be effective. However, conducting adversarial training brings much computational overhead compared with standard training. In order to reduce the computational cost, we propose an annealing mechanism, Amata, to reduce the overhead associated with adversarial training. The proposed Amata is provably convergent, well-motivated from the lens of optimal control theory and can be combined with existing acceleration methods to further enhance performance. It is demonstrated that on standard datasets, Amata can achieve similar or better robustness with around 1/3 to 1/2 the computational time compared with traditional methods. In addition, Amata can be incorporated into other adversarial training acceleration algorithms (e.g. YOPO, Free, Fast, and ATTA), which leads to further reduction in computational time on large-scale problems.
Batch Group Normalization
Dec 09, 2020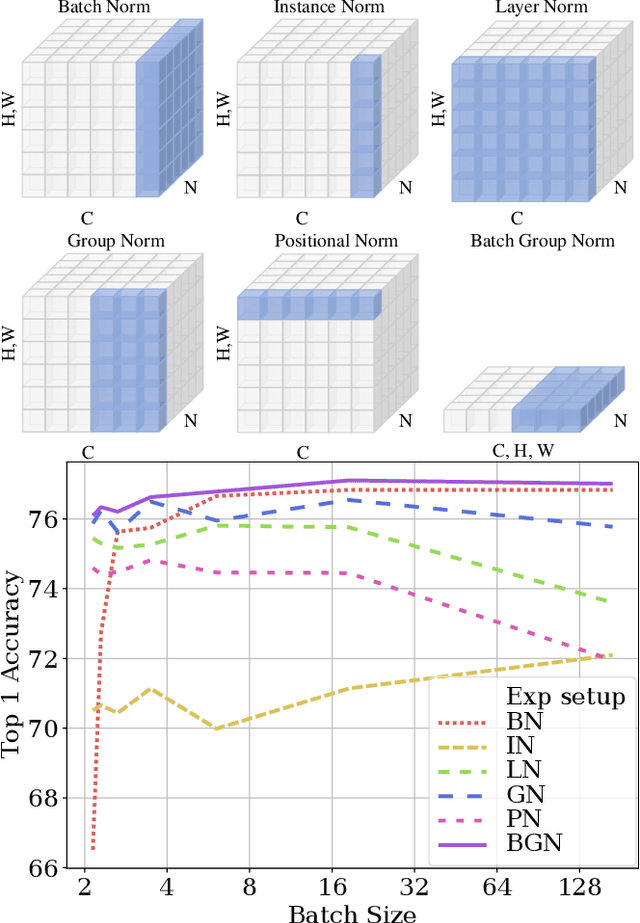

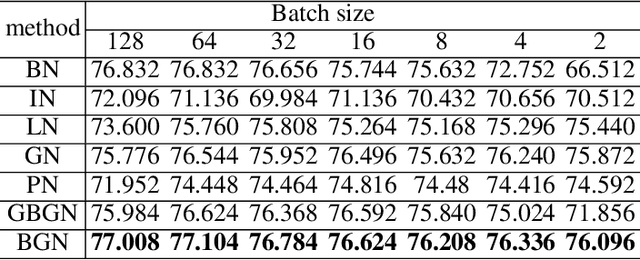
Deep Convolutional Neural Networks (DCNNs) are hard and time-consuming to train. Normalization is one of the effective solutions. Among previous normalization methods, Batch Normalization (BN) performs well at medium and large batch sizes and is with good generalizability to multiple vision tasks, while its performance degrades significantly at small batch sizes. In this paper, we find that BN saturates at extreme large batch sizes, i.e., 128 images per worker, i.e., GPU, as well and propose that the degradation/saturation of BN at small/extreme large batch sizes is caused by noisy/confused statistic calculation. Hence without adding new trainable parameters, using multiple-layer or multi-iteration information, or introducing extra computation, Batch Group Normalization (BGN) is proposed to solve the noisy/confused statistic calculation of BN at small/extreme large batch sizes with introducing the channel, height and width dimension to compensate. The group technique in Group Normalization (GN) is used and a hyper-parameter G is used to control the number of feature instances used for statistic calculation, hence to offer neither noisy nor confused statistic for different batch sizes. We empirically demonstrate that BGN consistently outperforms BN, Instance Normalization (IN), Layer Normalization (LN), GN, and Positional Normalization (PN), across a wide spectrum of vision tasks, including image classification, Neural Architecture Search (NAS), adversarial learning, Few Shot Learning (FSL) and Unsupervised Domain Adaptation (UDA), indicating its good performance, robust stability to batch size and wide generalizability. For example, for training ResNet-50 on ImageNet with a batch size of 2, BN achieves Top1 accuracy of 66.512% while BGN achieves 76.096% with notable improvement.