 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmata: An Annealing Mechanism for Adversarial Training Acceleration
Paper and Code
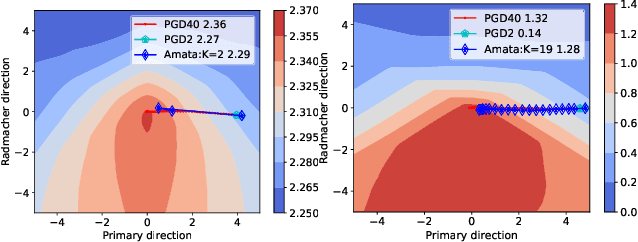



Despite the empirical success in various domains, it has been revealed that deep neural networks are vulnerable to maliciously perturbed input data that much degrade their performance. This is known as adversarial attacks. To counter adversarial attacks, adversarial training formulated as a form of robust optimization has been demonstrated to be effective. However, conducting adversarial training brings much computational overhead compared with standard training. In order to reduce the computational cost, we propose an annealing mechanism, Amata, to reduce the overhead associated with adversarial training. The proposed Amata is provably convergent, well-motivated from the lens of optimal control theory and can be combined with existing acceleration methods to further enhance performance. It is demonstrated that on standard datasets, Amata can achieve similar or better robustness with around 1/3 to 1/2 the computational time compared with traditional methods. In addition, Amata can be incorporated into other adversarial training acceleration algorithms (e.g. YOPO, Free, Fast, and ATTA), which leads to further reduction in computational time on large-scale problems.