 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Semi-supervised Landmark Localization for X-ray Images using Few-shot Deep Adaptive Graph
Apr 29, 2021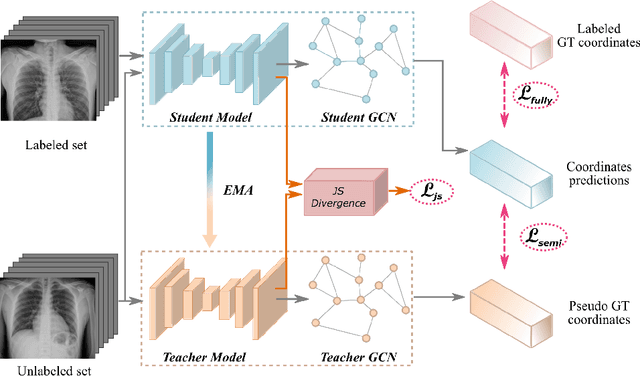
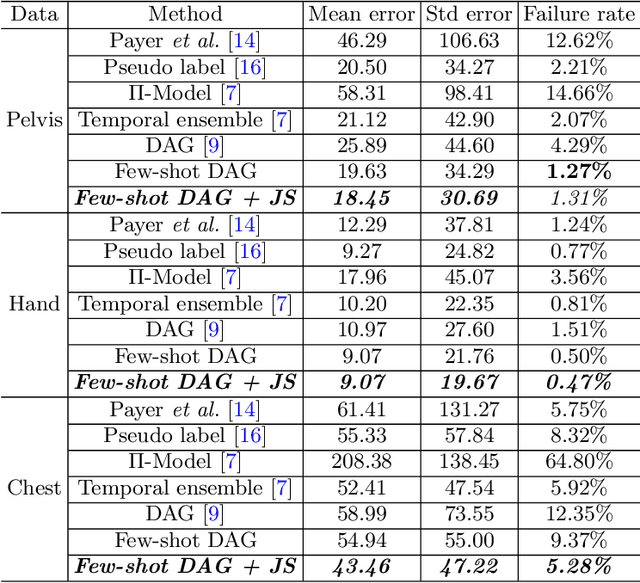

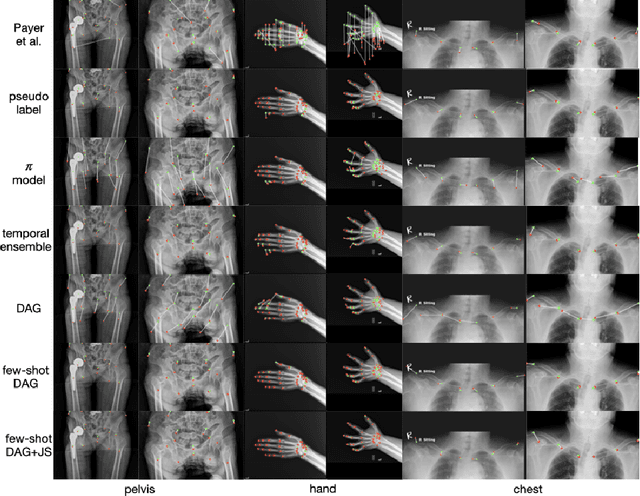
Landmark localization plays an important role in medical image analysis. Learning based methods, including CNN and GCN, have demonstrated the state-of-the-art performance. However, most of these methods are fully-supervised and heavily rely on manual labeling of a large training dataset. In this paper, based on a fully-supervised graph-based method, DAG, we proposed a semi-supervised extension of it, termed few-shot DAG, \ie five-shot DAG. It first trains a DAG model on the labeled data and then fine-tunes the pre-trained model on the unlabeled data with a teacher-student SSL mechanism. In addition to the semi-supervised loss, we propose another loss using JS divergence to regulate the consistency of the intermediate feature maps. We extensively evaluated our method on pelvis, hand and chest landmark detection tasks. Our experiment results demonstrate consistent and significant improvements over previous methods.
Semi-Supervised Learning for Bone Mineral Density Estimation in Hip X-ray Images
Mar 24, 2021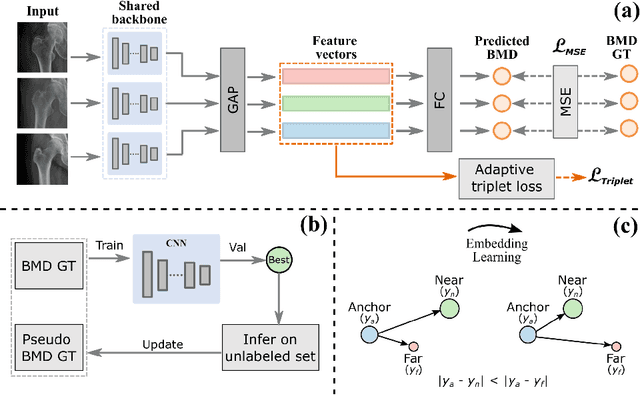

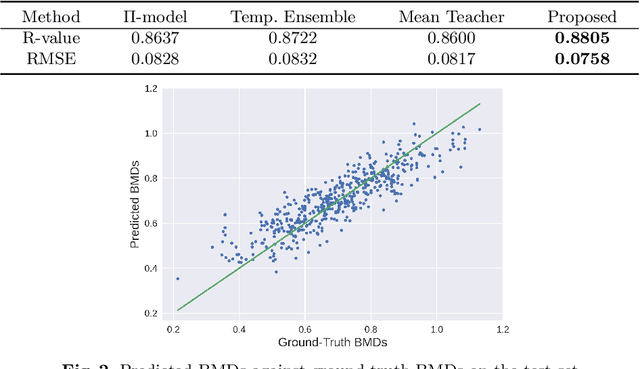
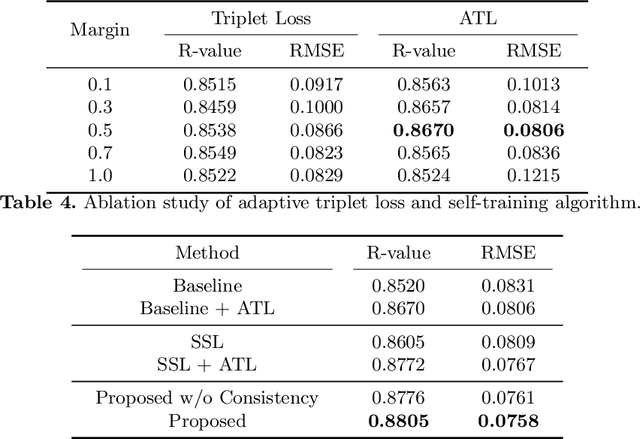
Bone mineral density (BMD) is a clinically critical indicator of osteoporosis, usually measured by dual-energy X-ray absorptiometry (DEXA). Due to the limited accessibility of DEXA machines and examinations, osteoporosis is often under-diagnosed and under-treated, leading to increased fragility fracture risks. Thus it is highly desirable to obtain BMDs with alternative cost-effective and more accessible medical imaging examinations such as X-ray plain films. In this work, we formulate the BMD estimation from plain hip X-ray images as a regression problem. Specifically, we propose a new semi-supervised self-training algorithm to train the BMD regression model using images coupled with DEXA measured BMDs and unlabeled images with pseudo BMDs. Pseudo BMDs are generated and refined iteratively for unlabeled images during self-training. We also present a novel adaptive triplet loss to improve the model's regression accuracy. On an in-house dataset of 1,090 images (819 unique patients), our BMD estimation method achieves a high Pearson correlation coefficient of 0.8805 to ground-truth BMDs. It offers good feasibility to use the more accessible and cheaper X-ray imaging for opportunistic osteoporosis screening.
Contour Transformer Network for One-shot Segmentation of Anatomical Structures
Dec 02, 2020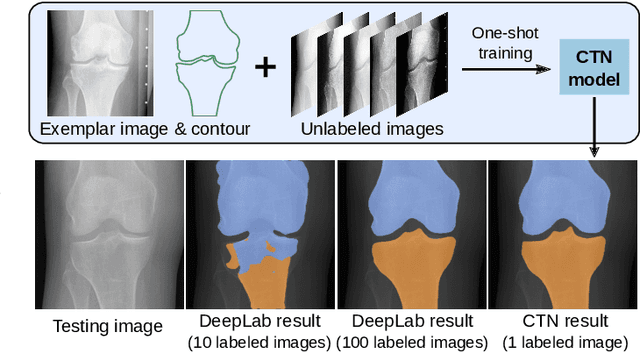
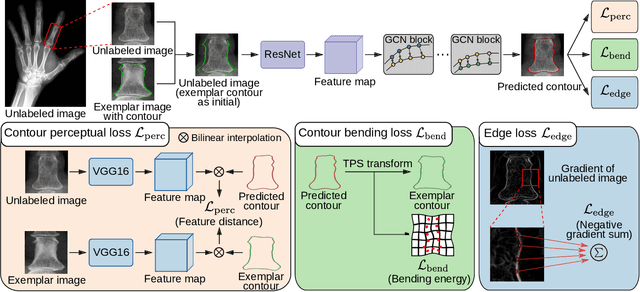
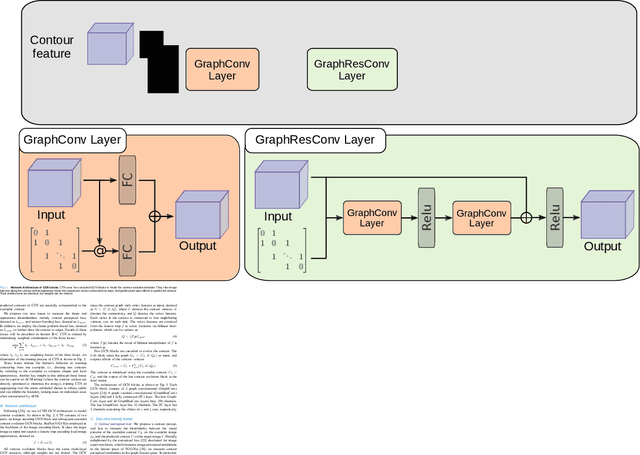
Accurate segmentation of anatomical structures is vital for medical image analysis. The state-of-the-art accuracy is typically achieved by supervised learning methods, where gathering the requisite expert-labeled image annotations in a scalable manner remains a main obstacle. Therefore, annotation-efficient methods that permit to produce accurate anatomical structure segmentation are highly desirable. In this work, we present Contour Transformer Network (CTN), a one-shot anatomy segmentation method with a naturally built-in human-in-the-loop mechanism. We formulate anatomy segmentation as a contour evolution process and model the evolution behavior by graph convolutional networks (GCNs). Training the CTN model requires only one labeled image exemplar and leverages additional unlabeled data through newly introduced loss functions that measure the global shape and appearance consistency of contours. On segmentation tasks of four different anatomies, we demonstrate that our one-shot learning method significantly outperforms non-learning-based methods and performs competitively to the state-of-the-art fully supervised deep learning methods. With minimal human-in-the-loop editing feedback, the segmentation performance can be further improved to surpass the fully supervised methods.
Learning to Segment Anatomical Structures Accurately from One Exemplar
Jul 08, 2020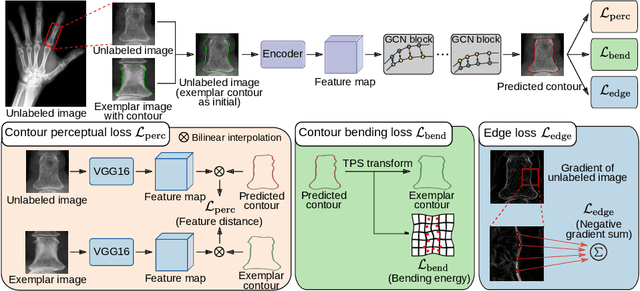

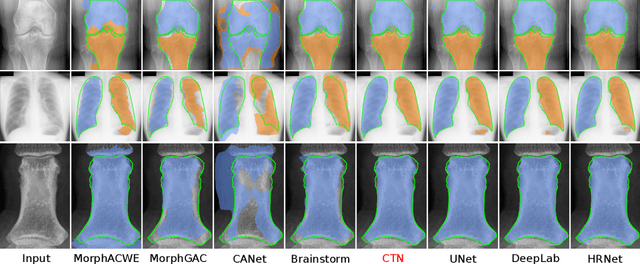

Accurate segmentation of critical anatomical structures is at the core of medical image analysis. The main bottleneck lies in gathering the requisite expert-labeled image annotations in a scalable manner. Methods that permit to produce accurate anatomical structure segmentation without using a large amount of fully annotated training images are highly desirable. In this work, we propose a novel contribution of Contour Transformer Network (CTN), a one-shot anatomy segmentor including a naturally built-in human-in-the-loop mechanism. Segmentation is formulated by learning a contour evolution behavior process based on graph convolutional networks (GCNs). Training of our CTN model requires only one labeled image exemplar and leverages additional unlabeled data through newly introduced loss functions that measure the global shape and appearance consistency of contours. We demonstrate that our one-shot learning method significantly outperforms non-learning-based methods and performs competitively to the state-of-the-art fully supervised deep learning approaches. With minimal human-in-the-loop editing feedback, the segmentation performance can be further improved and tailored towards the observer desired outcomes. This can facilitate the clinician designed imaging-based biomarker assessments (to support personalized quantitative clinical diagnosis) and outperforms fully supervised baselines.
Structured Landmark Detection via Topology-Adapting Deep Graph Learning
Apr 23, 2020
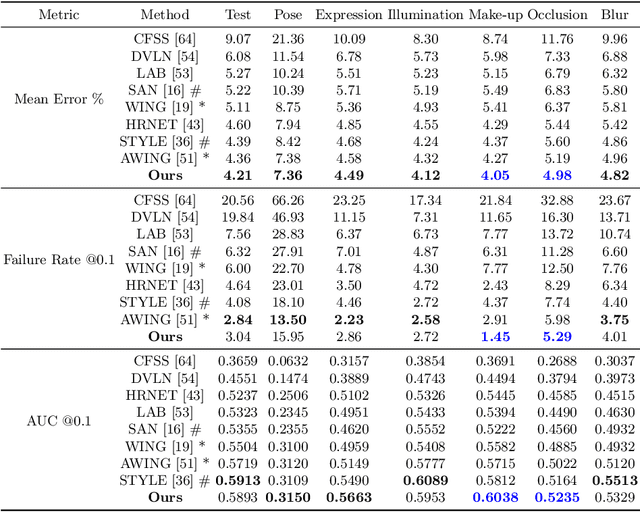


Image landmark detection aims to automatically identify the locations of predefined fiducial points. Despite recent success in this filed, higher-ordered structural modeling to capture implicit or explicit relationships among anatomical landmarks has not been adequately exploited. In this work, we present a new topology-adapting deep graph learning approach for accurate anatomical facial and medical (e.g., hand, pelvis) landmark detection. The proposed method constructs graph signals leveraging both local image features and global shape features. The adaptive graph topology naturally explores and lands on task-specific structures which is learned end-to-end with two Graph Convolutional Networks (GCNs). Extensive experiments are conducted on three public facial image datasets (WFLW, 300W and COFW-68) as well as three real-world X-ray medical datasets (Cephalometric (public), Hand and Pelvis). Quantitative results comparing with the previous state-of-the-art approaches across all studied datasets indicating the superior performance in both robustness and accuracy. Qualitative visualizations of the learned graph topologies demonstrate a physically plausible connectivity laying behind the landmarks.