 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAdam: A Memory Efficient Full Parameter Training Method for Large Language Models
Apr 03, 2024This work presents BAdam, an optimizer that leverages the block coordinate optimization framework with Adam as the inner solver. BAdam offers a memory efficient approach to the full parameter finetuning of large language models and reduces running time of the backward process thanks to the chain rule property. Experimentally, we apply BAdam to instruction-tune the Llama 2-7B model on the Alpaca-GPT4 dataset using a single RTX3090-24GB GPU. The results indicate that BAdam exhibits superior convergence behavior in comparison to LoRA and LOMO. Furthermore, our downstream performance evaluation of the instruction-tuned models using the MT-bench shows that BAdam modestly surpasses LoRA and more substantially outperforms LOMO. Finally, we compare BAdam with Adam on a medium-sized task, i.e., finetuning RoBERTa-large on the SuperGLUE benchmark. The results demonstrate that BAdam is capable of narrowing the performance gap with Adam. Our code is available at https://github.com/Ledzy/BAdam.
Low-Rank Structured Clutter Covariance Matrix Estimation for Airborne STAP Radar
Jan 27, 2023In space-time adaptive processing (STAP) of the airborne radar system, it is very important to realize sparse restoration of the clutter covariance matrix with a small number of samples. In this paper, a clutter suppression method for airborne forward-looking array radar based on joint statistics and structural priority is proposed, which can estimate the clutter covariance matrix in the case of small samples. Assuming that the clutter covariance matrix obeys the inverse Wishart prior distribution, the maximum posterior estimate is obtained by using the low-rank symmetry of the matrix itself. The simulation results based on the radar forward-looking array model show that compared with the traditional covariance matrix estimation method, the proposed method can effectively improve the clutter suppression performance of airborne radar while efficiently calculating.
Finite-Time Analysis of Fully Decentralized Single-Timescale Actor-Critic
Jun 12, 2022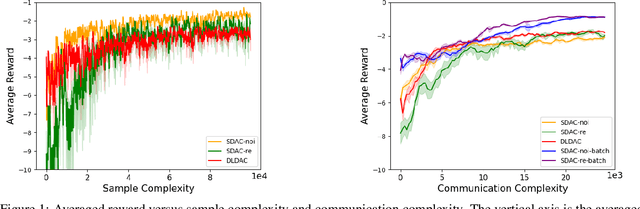
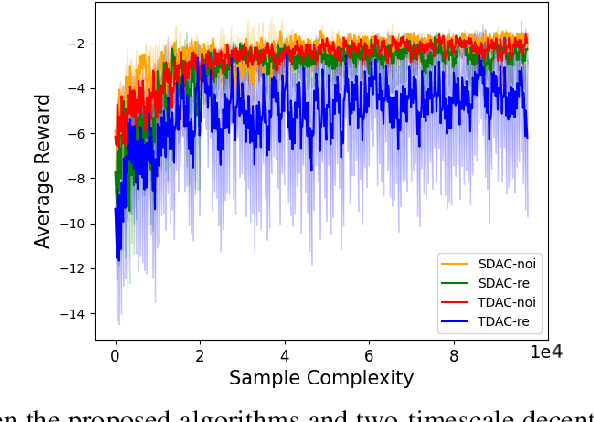
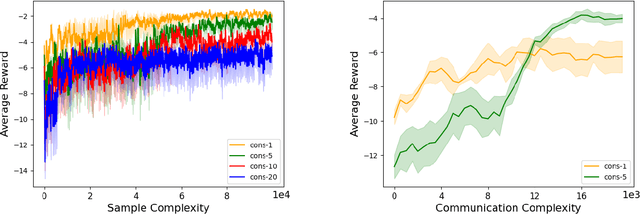
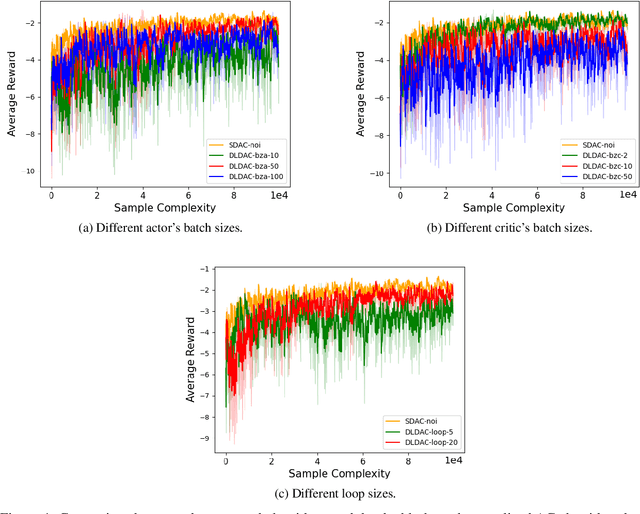
Decentralized Actor-Critic (AC) algorithms have been widely utilized for multi-agent reinforcement learning (MARL) and have achieved remarkable success. Apart from its empirical success, the theoretical convergence property of decentralized AC algorithms is largely unexplored. The existing finite-time convergence results are derived based on either double-loop update or two-timescale step sizes rule, which is not often adopted in real implementation. In this work, we introduce a fully decentralized AC algorithm, where actor, critic, and global reward estimator are updated in an alternating manner with step sizes being of the same order, namely, we adopt the \emph{single-timescale} update. Theoretically, using linear approximation for value and reward estimation, we show that our algorithm has sample complexity of $\tilde{\mathcal{O}}(\epsilon^{-2})$ under Markovian sampling, which matches the optimal complexity with double-loop implementation (here, $\tilde{\mathcal{O}}$ hides a log term). The sample complexity can be improved to ${\mathcal{O}}(\epsilon^{-2})$ under the i.i.d. sampling scheme. The central to establishing our complexity results is \emph{the hidden smoothness of the optimal critic variable} we revealed. We also provide a local action privacy-preserving version of our algorithm and its analysis. Finally, we conduct experiments to show the superiority of our algorithm over the existing decentralized AC algorithms.
Relaxed Conditional Image Transfer for Semi-supervised Domain Adaptation
Jan 05, 2021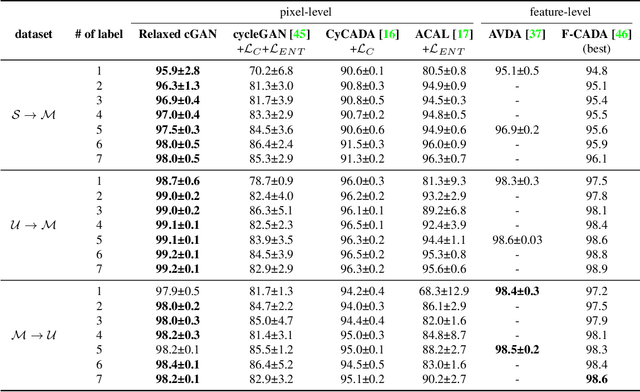
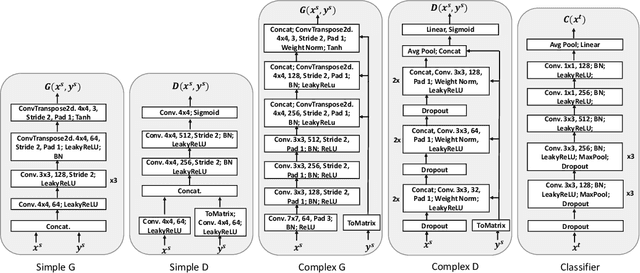
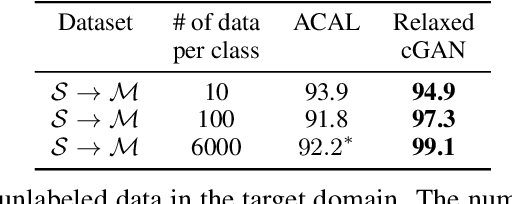
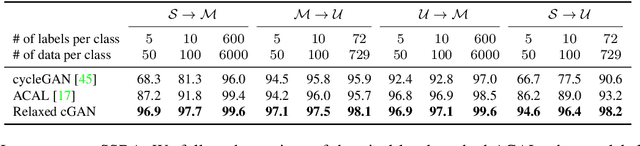
Semi-supervised domain adaptation (SSDA), which aims to learn models in a partially labeled target domain with the assistance of the fully labeled source domain, attracts increasing attention in recent years. To explicitly leverage the labeled data in both domains, we naturally introduce a conditional GAN framework to transfer images without changing the semantics in SSDA. However, we identify a label-domination problem in such an approach. In fact, the generator tends to overlook the input source image and only memorizes prototypes of each class, which results in unsatisfactory adaptation performance. To this end, we propose a simple yet effective Relaxed conditional GAN (Relaxed cGAN) framework. Specifically, we feed the image without its label to our generator. In this way, the generator has to infer the semantic information of input data. We formally prove that its equilibrium is desirable and empirically validate its practical convergence and effectiveness in image transfer. Additionally, we propose several techniques to make use of unlabeled data in the target domain, enhancing the model in SSDA settings. We validate our method on the well-adopted datasets: Digits, DomainNet, and Office-Home. We achieve state-of-the-art performance on DomainNet, Office-Home and most digit benchmarks in low-resource and high-resource settings.
Batch Group Normalization
Dec 09, 2020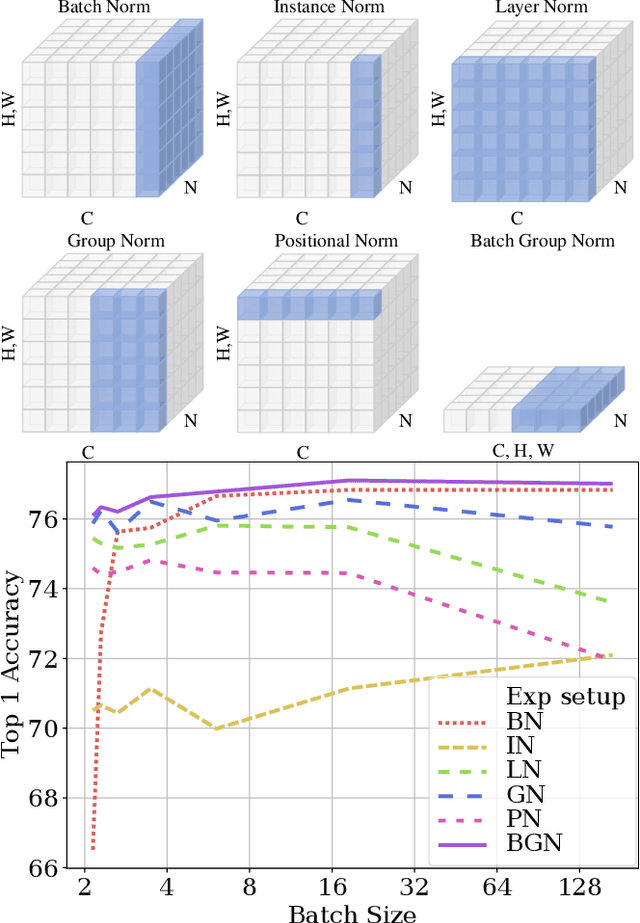

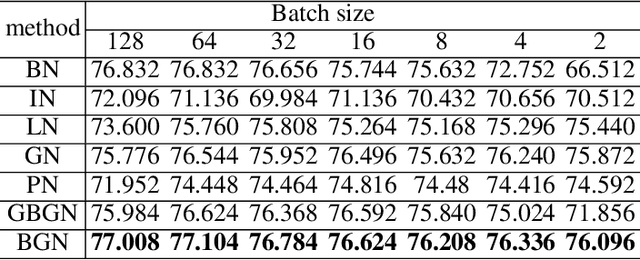
Deep Convolutional Neural Networks (DCNNs) are hard and time-consuming to train. Normalization is one of the effective solutions. Among previous normalization methods, Batch Normalization (BN) performs well at medium and large batch sizes and is with good generalizability to multiple vision tasks, while its performance degrades significantly at small batch sizes. In this paper, we find that BN saturates at extreme large batch sizes, i.e., 128 images per worker, i.e., GPU, as well and propose that the degradation/saturation of BN at small/extreme large batch sizes is caused by noisy/confused statistic calculation. Hence without adding new trainable parameters, using multiple-layer or multi-iteration information, or introducing extra computation, Batch Group Normalization (BGN) is proposed to solve the noisy/confused statistic calculation of BN at small/extreme large batch sizes with introducing the channel, height and width dimension to compensate. The group technique in Group Normalization (GN) is used and a hyper-parameter G is used to control the number of feature instances used for statistic calculation, hence to offer neither noisy nor confused statistic for different batch sizes. We empirically demonstrate that BGN consistently outperforms BN, Instance Normalization (IN), Layer Normalization (LN), GN, and Positional Normalization (PN), across a wide spectrum of vision tasks, including image classification, Neural Architecture Search (NAS), adversarial learning, Few Shot Learning (FSL) and Unsupervised Domain Adaptation (UDA), indicating its good performance, robust stability to batch size and wide generalizability. For example, for training ResNet-50 on ImageNet with a batch size of 2, BN achieves Top1 accuracy of 66.512% while BGN achieves 76.096% with notable improvement.