 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Diffusion with Test-Time Training on Efficient Image Restoration
Jun 17, 2025Image restoration faces challenges including ineffective feature fusion, computational bottlenecks and inefficient diffusion processes. To address these, we propose DiffRWKVIR, a novel framework unifying Test-Time Training (TTT) with efficient diffusion. Our approach introduces three key innovations: (1) Omni-Scale 2D State Evolution extends RWKV's location-dependent parameterization to hierarchical multi-directional 2D scanning, enabling global contextual awareness with linear complexity O(L); (2) Chunk-Optimized Flash Processing accelerates intra-chunk parallelism by 3.2x via contiguous chunk processing (O(LCd) complexity), reducing sequential dependencies and computational overhead; (3) Prior-Guided Efficient Diffusion extracts a compact Image Prior Representation (IPR) in only 5-20 steps, proving 45% faster training/inference than DiffIR while solving computational inefficiency in denoising. Evaluated across super-resolution and inpainting benchmarks (Set5, Set14, BSD100, Urban100, Places365), DiffRWKVIR outperforms SwinIR, HAT, and MambaIR/v2 in PSNR, SSIM, LPIPS, and efficiency metrics. Our method establishes a new paradigm for adaptive, high-efficiency image restoration with optimized hardware utilization.
Aggregation of Multi Diffusion Models for Enhancing Learned Representations
Oct 02, 2024Diffusion models have achieved remarkable success in image generation, particularly with the various applications of classifier-free guidance conditional diffusion models. While many diffusion models perform well when controlling for particular aspect among style, character, and interaction, they struggle with fine-grained control due to dataset limitations and intricate model architecture design. This paper introduces a novel algorithm, Aggregation of Multi Diffusion Models (AMDM), which synthesizes features from multiple diffusion models into a specified model, enhancing its learned representations to activate specific features for fine-grained control. AMDM consists of two key components: spherical aggregation and manifold optimization. Spherical aggregation merges intermediate variables from different diffusion models with minimal manifold deviation, while manifold optimization refines these variables to align with the intermediate data manifold, enhancing sampling quality. Experimental results demonstrate that AMDM significantly improves fine-grained control without additional training or inference time, proving its effectiveness. Additionally, it reveals that diffusion models initially focus on features such as position, attributes, and style, with later stages improving generation quality and consistency. AMDM offers a new perspective for tackling the challenges of fine-grained conditional control generation in diffusion models: We can fully utilize existing conditional diffusion models that control specific aspects, or develop new ones, and then aggregate them using the AMDM algorithm. This eliminates the need for constructing complex datasets, designing intricate model architectures, and incurring high training costs. Code is available at: https://github.com/Hammour-steak/AMDM
Enhanced Control for Diffusion Bridge in Image Restoration
Aug 29, 2024



Image restoration refers to the process of restoring a damaged low-quality image back to its corresponding high-quality image. Typically, we use convolutional neural networks to directly learn the mapping from low-quality images to high-quality images achieving image restoration. Recently, a special type of diffusion bridge model has achieved more advanced results in image restoration. It can transform the direct mapping from low-quality to high-quality images into a diffusion process, restoring low-quality images through a reverse process. However, the current diffusion bridge restoration models do not emphasize the idea of conditional control, which may affect performance. This paper introduces the ECDB model enhancing the control of the diffusion bridge with low-quality images as conditions. Moreover, in response to the characteristic of diffusion models having low denoising level at larger values of \(\bm t \), we also propose a Conditional Fusion Schedule, which more effectively handles the conditional feature information of various modules. Experimental results prove that the ECDB model has achieved state-of-the-art results in many image restoration tasks, including deraining, inpainting and super-resolution. Code is avaliable at https://github.com/Hammour-steak/ECDB.
Image Restoration Through Generalized Ornstein-Uhlenbeck Bridge
Dec 16, 2023


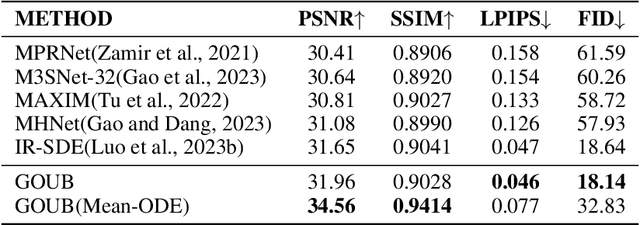
Diffusion models possess powerful generative capabilities enabling the mapping of noise to data using reverse stochastic differential equations. However, in image restoration tasks, the focus is on the mapping relationship from low-quality images to high-quality images. To address this, we introduced the Generalized Ornstein-Uhlenbeck Bridge (GOUB) model. By leveraging the natural mean-reverting property of the generalized OU process and further adjusting the variance of its steady-state distribution through the Doob's h-transform, we achieve diffusion mappings from point to point with minimal cost. This allows for end-to-end training, enabling the recovery of high-quality images from low-quality ones. Additionally, we uncovered the mathematical essence of some bridge models, all of which are special cases of the GOUB and empirically demonstrated the optimality of our proposed models. Furthermore, benefiting from our distinctive parameterization mechanism, we proposed the Mean-ODE model that is better at capturing pixel-level information and structural perceptions. Experimental results show that both models achieved state-of-the-art results in various tasks, including inpainting, deraining, and super-resolution. Code is available at https://github.com/Hammour-steak/GOUB.