 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Distribution Alignment via Adaptive Optimal Transport
Mar 07, 2025To remedy the drawbacks of full-mass or fixed-mass constraints in classical optimal transport, we propose adaptive optimal transport which is distinctive from the classical optimal transport in its ability of adaptive-mass preserving. It aims to answer the mathematical problem of how to transport the probability mass adaptively between probability distributions, which is a fundamental topic in various areas of artificial intelligence. Adaptive optimal transport is able to transfer mass adaptively in the light of the intrinsic structure of the problem itself. The theoretical results shed light on the adaptive mechanism of mass transportation. Furthermore, we instantiate the adaptive optimal transport in machine learning application to align source and target distributions partially and adaptively by respecting the ubiquity of noises, outliers, and distribution shifts in the data. The experiment results on the domain adaptation benchmarks show that the proposed method significantly outperforms the state-of-the-art algorithms.
Defending Against Data Reconstruction Attacks in Federated Learning: An Information Theory Approach
Mar 02, 2024
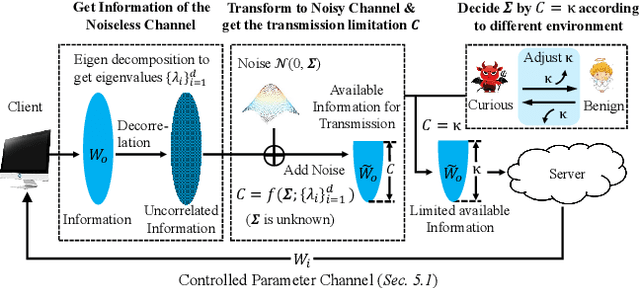
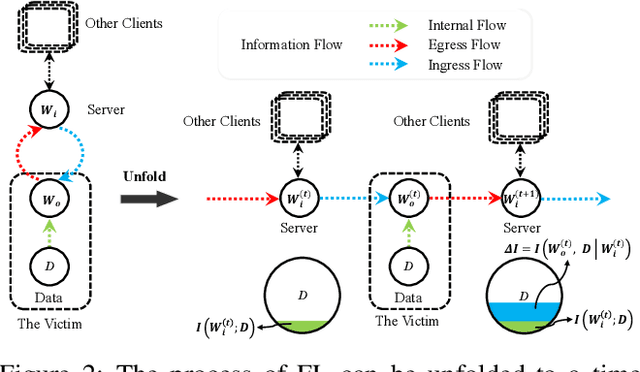
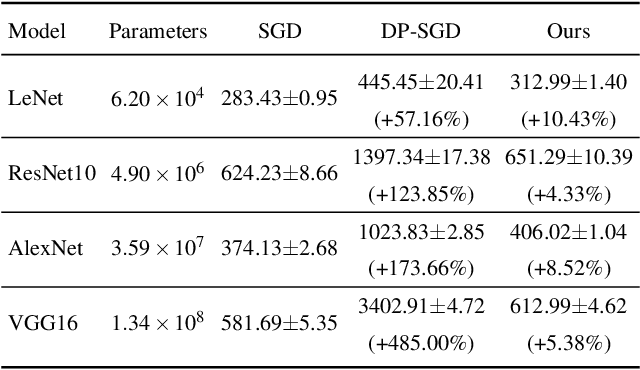
Federated Learning (FL) trains a black-box and high-dimensional model among different clients by exchanging parameters instead of direct data sharing, which mitigates the privacy leak incurred by machine learning. However, FL still suffers from membership inference attacks (MIA) or data reconstruction attacks (DRA). In particular, an attacker can extract the information from local datasets by constructing DRA, which cannot be effectively throttled by existing techniques, e.g., Differential Privacy (DP). In this paper, we aim to ensure a strong privacy guarantee for FL under DRA. We prove that reconstruction errors under DRA are constrained by the information acquired by an attacker, which means that constraining the transmitted information can effectively throttle DRA. To quantify the information leakage incurred by FL, we establish a channel model, which depends on the upper bound of joint mutual information between the local dataset and multiple transmitted parameters. Moreover, the channel model indicates that the transmitted information can be constrained through data space operation, which can improve training efficiency and the model accuracy under constrained information. According to the channel model, we propose algorithms to constrain the information transmitted in a single round of local training. With a limited number of training rounds, the algorithms ensure that the total amount of transmitted information is limited. Furthermore, our channel model can be applied to various privacy-enhancing techniques (such as DP) to enhance privacy guarantees against DRA. Extensive experiments with real-world datasets validate the effectiveness of our methods.
Item Cold Start Recommendation via Adversarial Variational Auto-encoder Warm-up
Feb 28, 2023



The gap between the randomly initialized item ID embedding and the well-trained warm item ID embedding makes the cold items hard to suit the recommendation system, which is trained on the data of historical warm items. To alleviate the performance decline of new items recommendation, the distribution of the new item ID embedding should be close to that of the historical warm items. To achieve this goal, we propose an Adversarial Variational Auto-encoder Warm-up model (AVAEW) to generate warm-up item ID embedding for cold items. Specifically, we develop a conditional variational auto-encoder model to leverage the side information of items for generating the warm-up item ID embedding. Particularly, we introduce an adversarial module to enforce the alignment between warm-up item ID embedding distribution and historical item ID embedding distribution. We demonstrate the effectiveness and compatibility of the proposed method by extensive offline experiments on public datasets and online A/B tests on a real-world large-scale news recommendation platform.
Demystifying Deep Learning in Predictive Spatio-Temporal Analytics: An Information-Theoretic Framework
Sep 17, 2020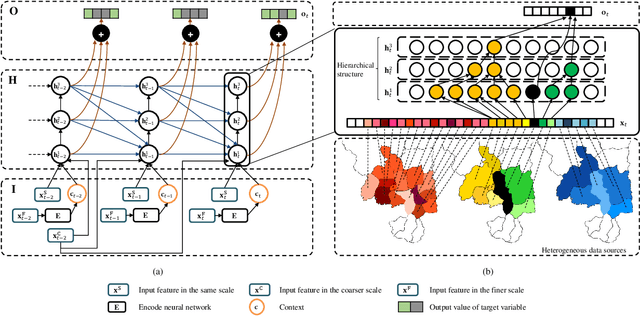
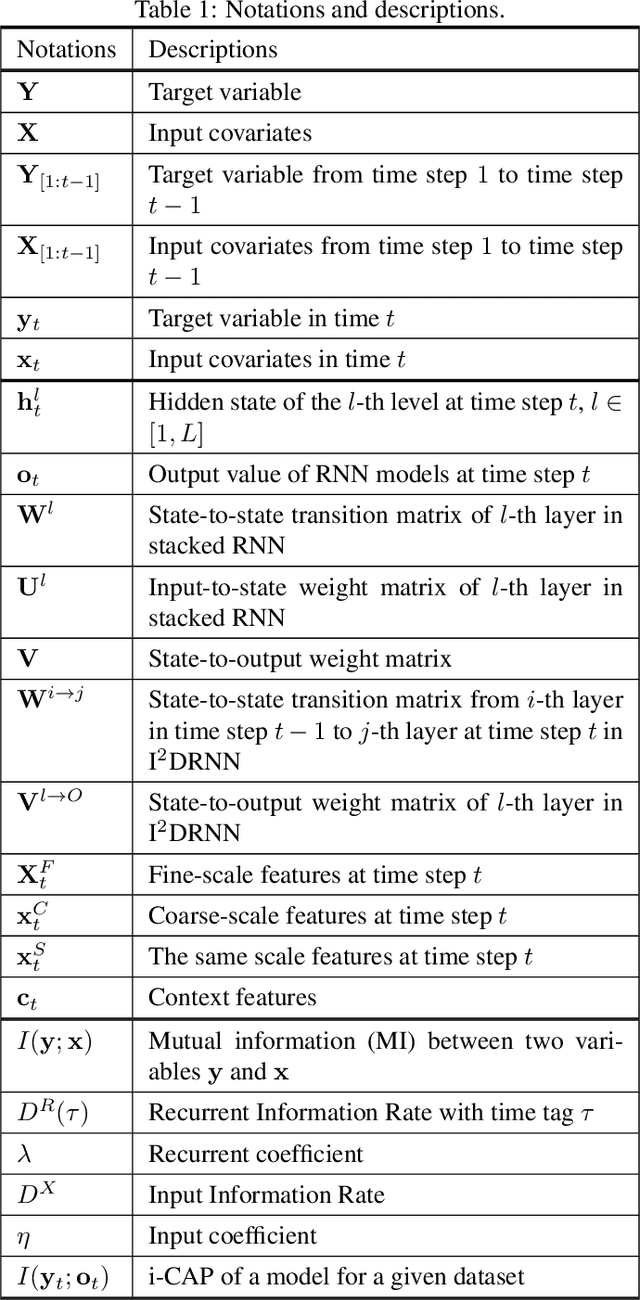
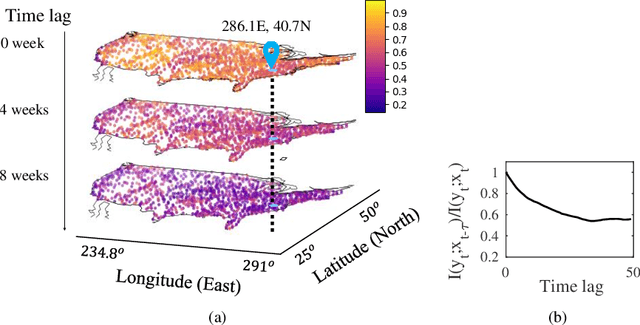
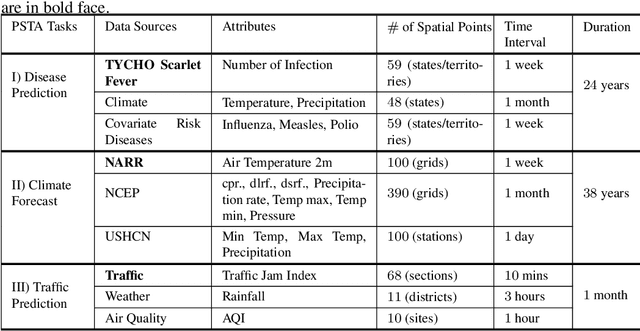
Deep learning has achieved incredible success over the past years, especially in various challenging predictive spatio-temporal analytics (PSTA) tasks, such as disease prediction, climate forecast, and traffic prediction, where intrinsic dependency relationships among data exist and generally manifest at multiple spatio-temporal scales. However, given a specific PSTA task and the corresponding dataset, how to appropriately determine the desired configuration of a deep learning model, theoretically analyze the model's learning behavior, and quantitatively characterize the model's learning capacity remains a mystery. In order to demystify the power of deep learning for PSTA, in this paper, we provide a comprehensive framework for deep learning model design and information-theoretic analysis. First, we develop and demonstrate a novel interactively- and integratively-connected deep recurrent neural network (I$^2$DRNN) model. I$^2$DRNN consists of three modules: an Input module that integrates data from heterogeneous sources; a Hidden module that captures the information at different scales while allowing the information to flow interactively between layers; and an Output module that models the integrative effects of information from various hidden layers to generate the output predictions. Second, to theoretically prove that our designed model can learn multi-scale spatio-temporal dependency in PSTA tasks, we provide an information-theoretic analysis to examine the information-based learning capacity (i-CAP) of the proposed model. Third, to validate the I$^2$DRNN model and confirm its i-CAP, we systematically conduct a series of experiments involving both synthetic datasets and real-world PSTA tasks. The experimental results show that the I$^2$DRNN model outperforms both classical and state-of-the-art models, and is able to capture meaningful multi-scale spatio-temporal dependency.