 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Mutual Learning across Task Towers for Effective Multi-Task Recommender Learning
Sep 19, 2023



Recommender systems usually leverage multi-task learning methods to simultaneously optimize several objectives because of the multi-faceted user behavior data. The typical way of conducting multi-task learning is to establish appropriate parameter sharing across multiple tasks at lower layers while reserving a separate task tower for each task at upper layers. Since the task towers exert direct impact on the prediction results, we argue that the architecture of standalone task towers is sub-optimal for promoting positive knowledge sharing. Accordingly, we propose the framework of Deep Mutual Learning across task towers, which is compatible with various backbone multi-task networks. Extensive offline experiments and online AB tests are conducted to evaluate and verify the proposed approach's effectiveness.
* 6 pages
Item Cold Start Recommendation via Adversarial Variational Auto-encoder Warm-up
Feb 28, 2023



The gap between the randomly initialized item ID embedding and the well-trained warm item ID embedding makes the cold items hard to suit the recommendation system, which is trained on the data of historical warm items. To alleviate the performance decline of new items recommendation, the distribution of the new item ID embedding should be close to that of the historical warm items. To achieve this goal, we propose an Adversarial Variational Auto-encoder Warm-up model (AVAEW) to generate warm-up item ID embedding for cold items. Specifically, we develop a conditional variational auto-encoder model to leverage the side information of items for generating the warm-up item ID embedding. Particularly, we introduce an adversarial module to enforce the alignment between warm-up item ID embedding distribution and historical item ID embedding distribution. We demonstrate the effectiveness and compatibility of the proposed method by extensive offline experiments on public datasets and online A/B tests on a real-world large-scale news recommendation platform.
Slate-Aware Ranking for Recommendation
Feb 24, 2023
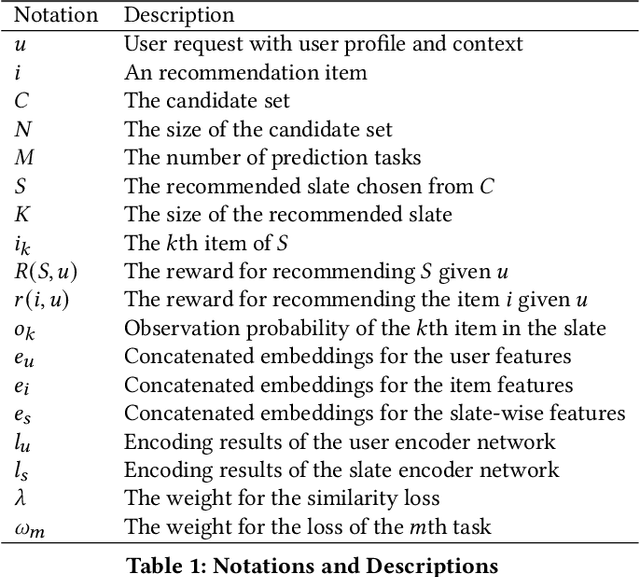

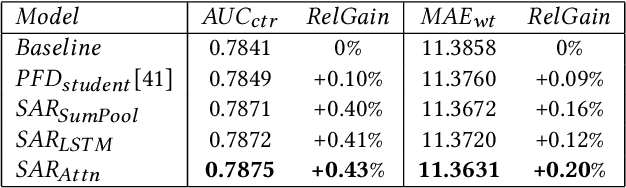
We see widespread adoption of slate recommender systems, where an ordered item list is fed to the user based on the user interests and items' content. For each recommendation, the user can select one or several items from the list for further interaction. In this setting, the significant impact on user behaviors from the mutual influence among the items is well understood. The existing methods add another step of slate re-ranking after the ranking stage of recommender systems, which considers the mutual influence among recommended items to re-rank and generate the recommendation results so as to maximize the expected overall utility. However, to model the complex interaction of multiple recommended items, the re-ranking stage usually can just handle dozens of candidates because of the constraint of limited hardware resource and system latency. Therefore, the ranking stage is still essential for most applications to provide high-quality candidate set for the re-ranking stage. In this paper, we propose a solution named Slate-Aware ranking (SAR) for the ranking stage. By implicitly considering the relations among the slate items, it significantly enhances the quality of the re-ranking stage's candidate set and boosts the relevance and diversity of the overall recommender systems. Both experiments with the public datasets and internal online A/B testing are conducted to verify its effectiveness.
Improving Item Cold-start Recommendation via Model-agnostic Conditional Variational Autoencoder
May 27, 2022



Embedding & MLP has become a paradigm for modern large-scale recommendation system. However, this paradigm suffers from the cold-start problem which will seriously compromise the ecological health of recommendation systems. This paper attempts to tackle the item cold-start problem by generating enhanced warmed-up ID embeddings for cold items with historical data and limited interaction records. From the aspect of industrial practice, we mainly focus on the following three points of item cold-start: 1) How to conduct cold-start without additional data requirements and make strategy easy to be deployed in online recommendation scenarios. 2) How to leverage both historical records and constantly emerging interaction data of new items. 3) How to model the relationship between item ID and side information stably from interaction data. To address these problems, we propose a model-agnostic Conditional Variational Autoencoder based Recommendation(CVAR) framework with some advantages including compatibility on various backbones, no extra requirements for data, utilization of both historical data and recent emerging interactions. CVAR uses latent variables to learn a distribution over item side information and generates desirable item ID embeddings using a conditional decoder. The proposed method is evaluated by extensive offline experiments on public datasets and online A/B tests on Tencent News recommendation platform, which further illustrate the advantages and robustness of CVAR.