 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021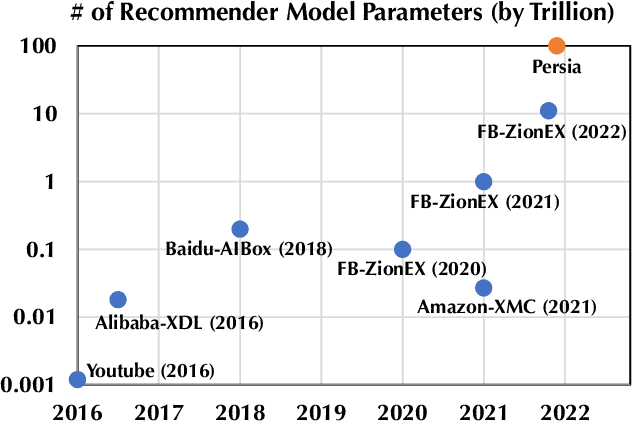
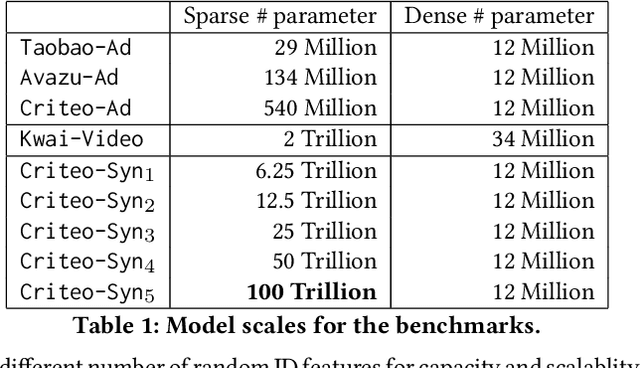
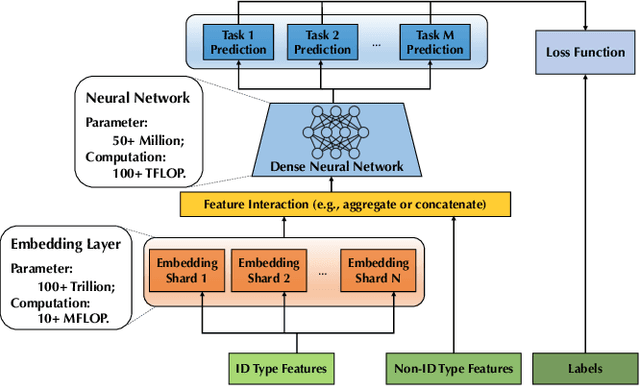
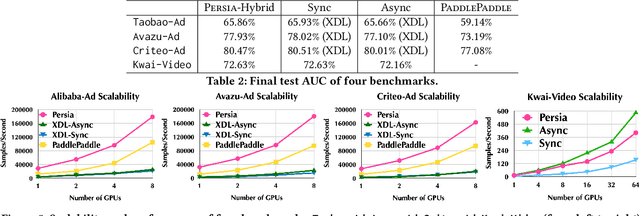
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
Semantic Graph-enhanced Visual Network for Zero-shot Learning
Jun 08, 2020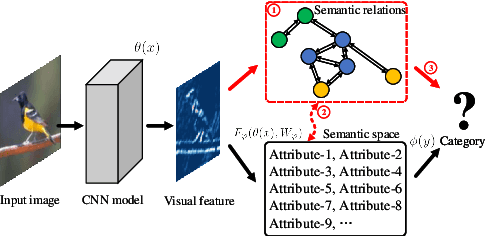
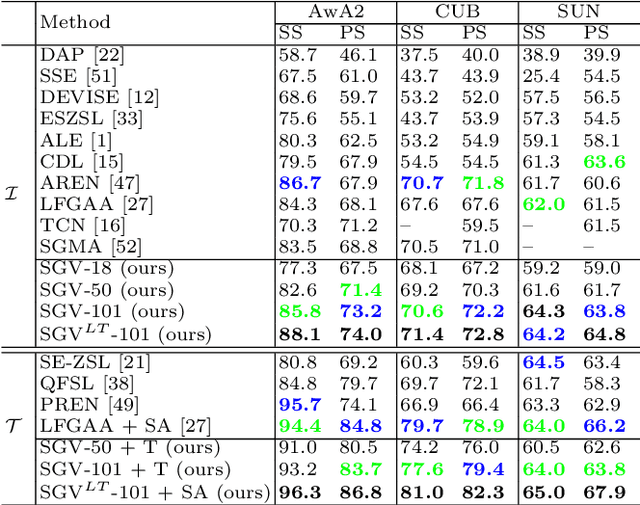

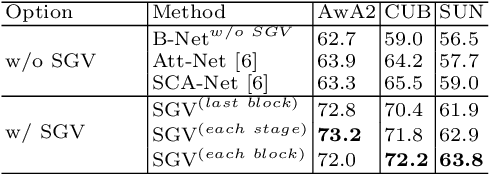
Zero-shot learning uses semantic attributes to connect the search space of unseen objects. In recent years, although the deep convolutional network brings powerful visual modeling capabilities to the ZSL task, its visual features have severe pattern inertia and lack of representation of semantic relationships, which leads to severe bias and ambiguity. In response to this, we propose the Graph-based Visual-Semantic Entanglement Network to conduct graph modeling of visual features, which is mapped to semantic attributes by using a knowledge graph, it contains several novel designs: 1. it establishes a multi-path entangled network with the convolutional neural network (CNN) and the graph convolutional network (GCN), which input the visual features from CNN to GCN to model the implicit semantic relations, then GCN feedback the graph modeled information to CNN features; 2. it uses attribute word vectors as the target for the graph semantic modeling of GCN, which forms a self-consistent regression for graph modeling and supervise GCN to learn more personalized attribute relations; 3. it fuses and supplements the hierarchical visual-semantic features refined by graph modeling into visual embedding. By promoting the semantic linkage modeling of visual features, our method outperforms state-of-the-art approaches on multiple representative ZSL datasets: AwA2, CUB, and SUN.
Multiple Attentional Pyramid Networks for Chinese Herbal Recognition
May 13, 2020
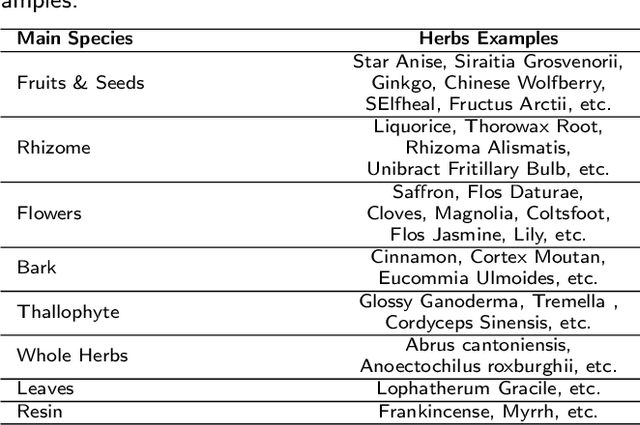
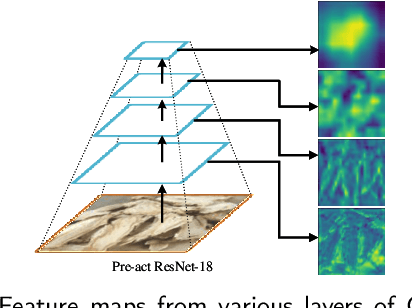
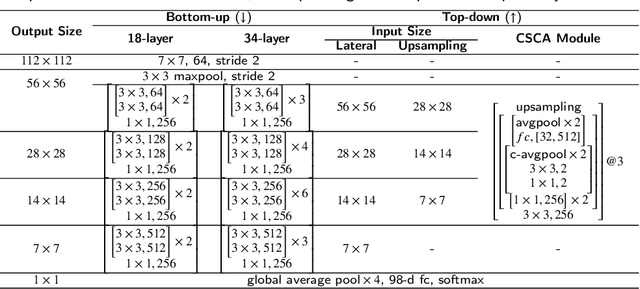
Chinese herbs play a critical role in Traditional Chinese Medicine. Due to different recognition granularity, they can be recognized accurately only by professionals with much experience. It is expected that they can be recognized automatically using new techniques like machine learning. However, there is no Chinese herbal image dataset available. Simultaneously, there is no machine learning method which can deal with Chinese herbal image recognition well. Therefore, this paper begins with building a new standard Chinese-Herbs dataset. Subsequently, a new Attentional Pyramid Networks (APN) for Chinese herbal recognition is proposed, where both novel competitive attention and spatial collaborative attention are proposed and then applied. APN can adaptively model Chinese herbal images with different feature scales. Finally, a new framework for Chinese herbal recognition is proposed as a new application of APN. Experiments are conducted on our constructed dataset and validate the effectiveness of our methods.
Inner-Imaging Convolutional Networks
Apr 22, 2019
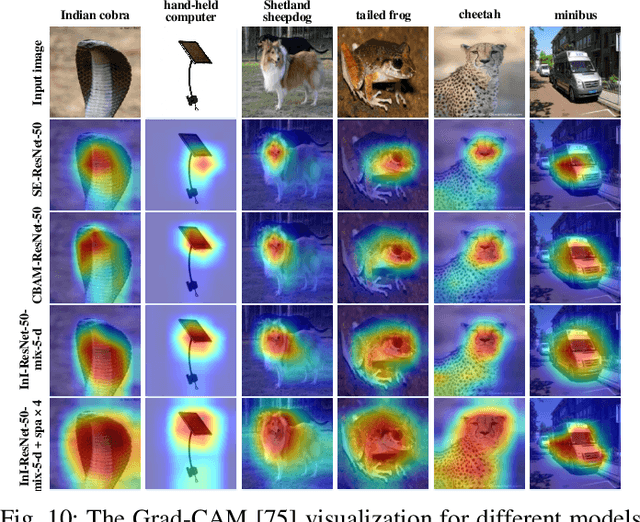
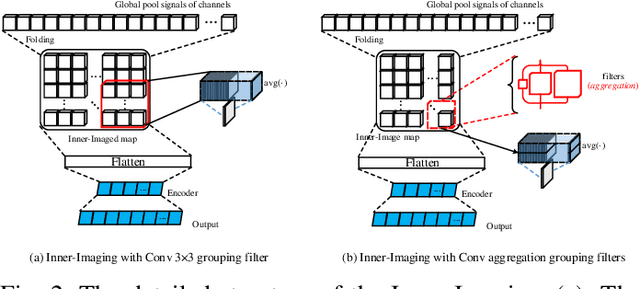
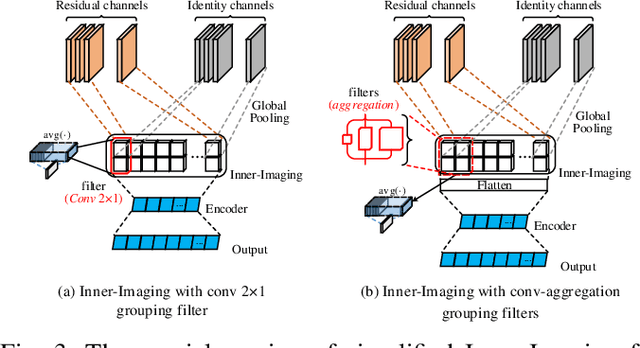
Despite the tremendous success in computer vision, deep convolutional networks suffer from serious computation cost and redundancies. Although previous works address this issue by enhancing diversities of filters, they ignore that both complementarity and completeness are required in the internal structure of convolutional network. In this setting, we propose a novel Inner-Imaging architecture, which allows relationships between channels to meet the above requirement. Specifically, we organize the filter signal points in groups using convolutional kernels to model both the intra- and inter-group relationships simultaneously. Consequently, we not only increase diversities of channels but also explicitly enhance the complementarity and completeness. Our proposed architecture is lightweight and easy to be implemented for improving the modelling efficiency and performance. We conduct extensive experiments on CIFAR, SVHN and ImageNet and verify the effectiveness of our inner-imaging architecture with residual networks as the backbone.
Stochastic Region Pooling: Make Attention More Expressive
Apr 22, 2019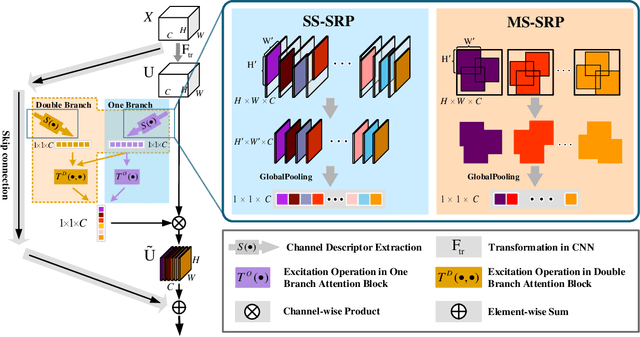
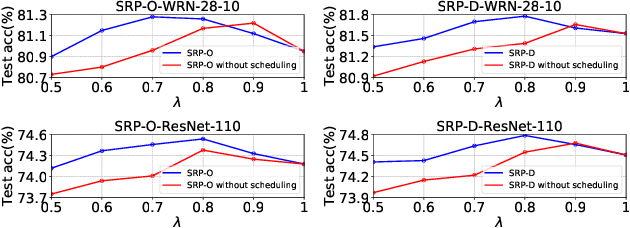
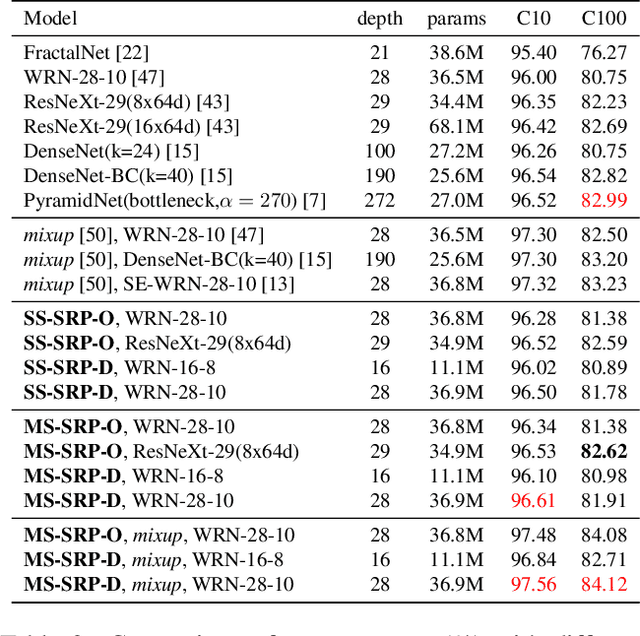
Global Average Pooling (GAP) is used by default on the channel-wise attention mechanism to extract channel descriptors. However, the simple global aggregation method of GAP is easy to make the channel descriptors have homogeneity, which weakens the detail distinction between feature maps, thus affecting the performance of the attention mechanism. In this work, we propose a novel method for channel-wise attention network, called Stochastic Region Pooling (SRP), which makes the channel descriptors more representative and diversity by encouraging the feature map to have more or wider important feature responses. Also, SRP is the general method for the attention mechanisms without any additional parameters or computation. It can be widely applied to attention networks without modifying the network structure. Experimental results on image recognition datasets including CIAFR-10/100, ImageNet and three Fine-grained datasets (CUB-200-2011, Stanford Cars and Stanford Dogs) show that SRP brings the significant improvements of the performance over efficient CNNs and achieves the state-of-the-art results.
Chinese Herbal Recognition based on Competitive Attentional Fusion of Multi-hierarchies Pyramid Features
Dec 23, 2018
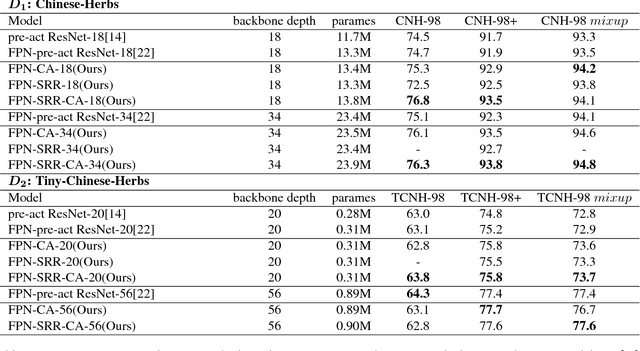

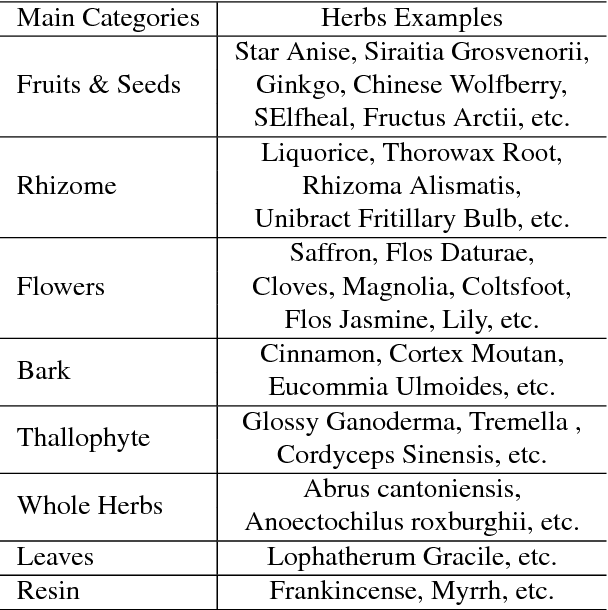
Convolution neural netwotks (CNNs) are successfully applied in image recognition task. In this study, we explore the approach of automatic herbal recognition with CNNs and build the standard Chinese herbs datasets firstly. According to the characteristics of herbal images, we proposed the competitive attentional fusion pyramid networks to model the features of herbal image, which mdoels the relationship of feature maps from different levels, and re-weights multi-level channels with channel-wise attention mechanism. In this way, we can dynamically adjust the weight of feature maps from various layers, according to the visual characteristics of each herbal image. Moreover, we also introduce the spatial attention to recalibrate the misaligned features caused by sampling in features amalgamation. Extensive experiments are conducted on our proposed datasets and validate the superior performance of our proposed models. The Chinese herbs datasets will be released upon acceptance to facilitate the research of Chinese herbal recognition.
Metabolize Neural Network
Sep 04, 2018

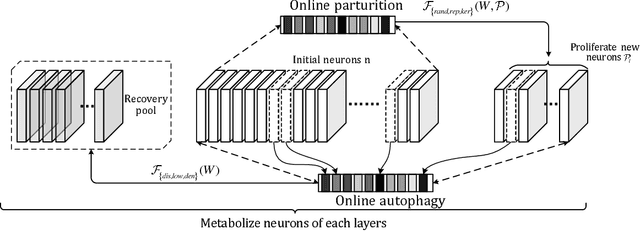
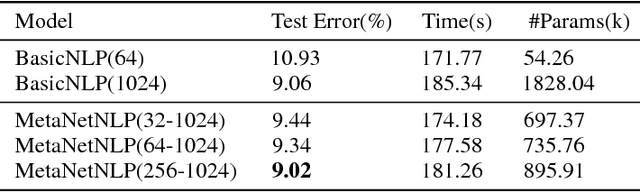
The metabolism of cells is the most basic and important part of human function. Neural networks in deep learning stem from neuronal activity. It is self-evident that the significance of metabolize neuronal network(MetaNet) in model construction. In this study, we explore neuronal metabolism for shallow network from proliferation and autophagy two aspects. First, we propose different neuron proliferate methods that constructive the selfgrowing network in metabolism cycle. Proliferate neurons alleviate resources wasting and insufficient model learning problem when network initializes more or less parameters. Then combined with autophagy mechanism in the process of model self construction to ablate under-expressed neurons. The MetaNet can automatically determine the number of neurons during training, further, save more resource consumption. We verify the performance of the proposed methods on datasets: MNIST, Fashion-MNIST and CIFAR-10.
Competitive Inner-Imaging Squeeze and Excitation for Residual Network
Jul 25, 2018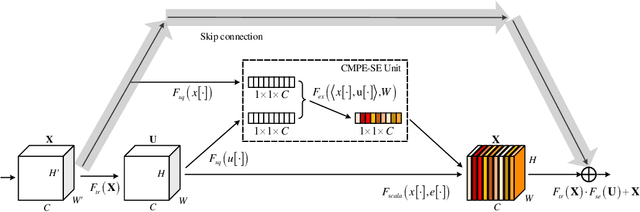
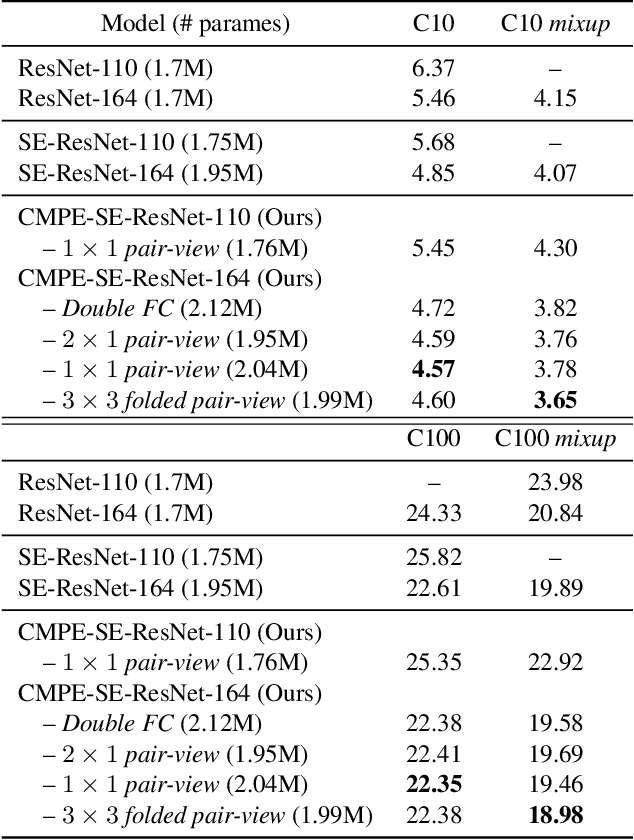
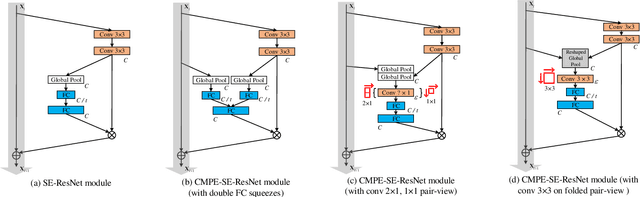
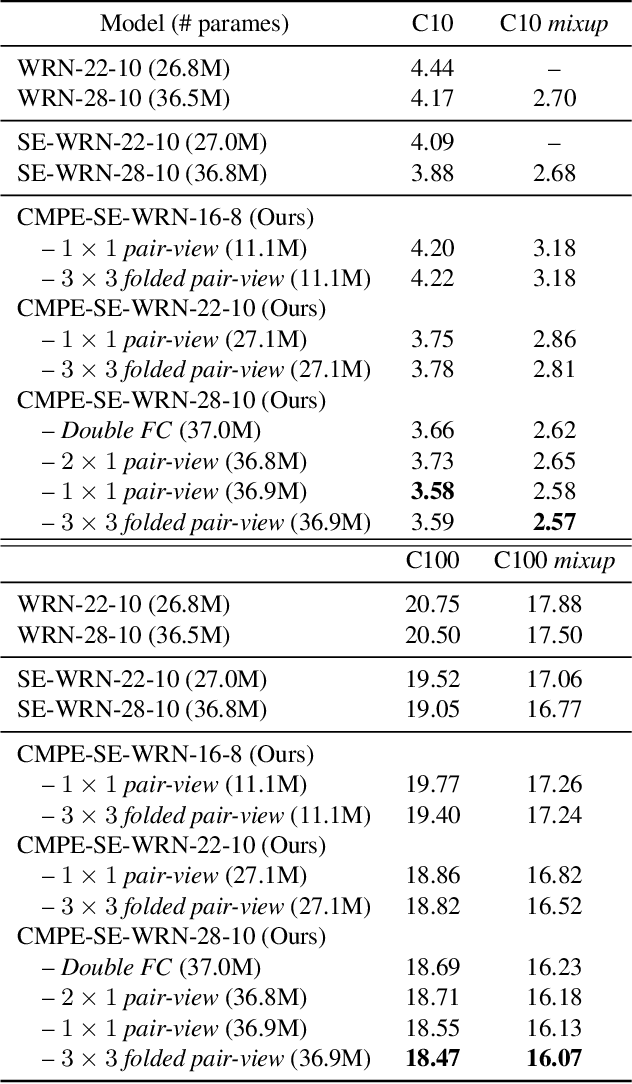
Residual Networks make the very deep convolutional architecture works well, which use the residual unit to supplement the identity mappings. On the other hand, Squeeze-Excitation (SE) network propose an adaptively recalibrates channel-wise attention approach to model the relationship of feature maps from different convolutional channel. In this work, we propose the competitive SE mechanism for residual network, rescaling value for each channel in this structure will be determined by residual and identity mappings jointly, this design enables us to expand the meaning of channel relationship modeling in residual blocks: the modeling of competition between residual and identity mappings make identity flow can controll the complement of residual feature maps for itself. Further, we design a novel pair-view competitive SE block to shrink the consumption and re-image the global characterizations of intermediate convolutional channels. We carry out experiments on datasets: CIFAR, SVHN, ImageNet, the proposed method can be compared with the state-of-the-art results.