 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Playback Performance in Video Recommender Systems with an On-Device Gating and Ranking Framework
Oct 08, 2024Video recommender systems (RSs) have gained increasing attention in recent years. Existing mainstream RSs focus on optimizing the matching function between users and items. However, we noticed that users frequently encounter playback issues such as slow loading or stuttering while browsing the videos, especially in weak network conditions, which will lead to a subpar browsing experience, and may cause users to leave, even when the video content and recommendations are superior. It is quite a serious issue, yet easily overlooked. To tackle this issue, we propose an on-device Gating and Ranking Framework (GRF) that cooperates with server-side RS. Specifically, we utilize a gate model to identify videos that may have playback issues in real-time, and then we employ a ranking model to select the optimal result from a locally-cached pool to replace the stuttering videos. Our solution has been fully deployed on Kwai, a large-scale short video platform with hundreds of millions of users globally. Moreover, it significantly enhances video playback performance and improves overall user experience and retention rates.
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021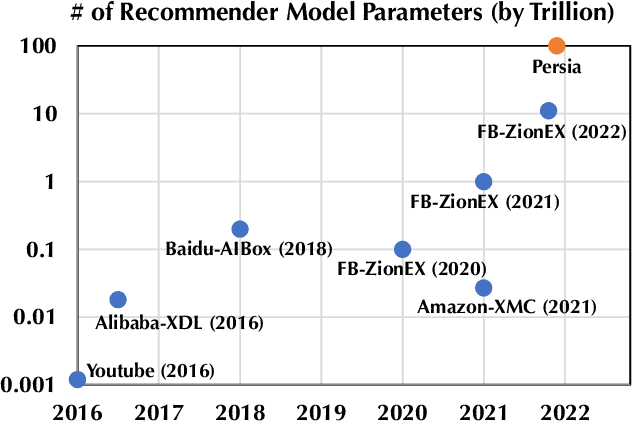
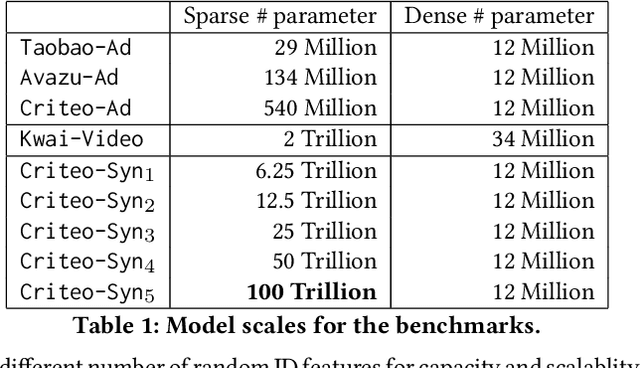
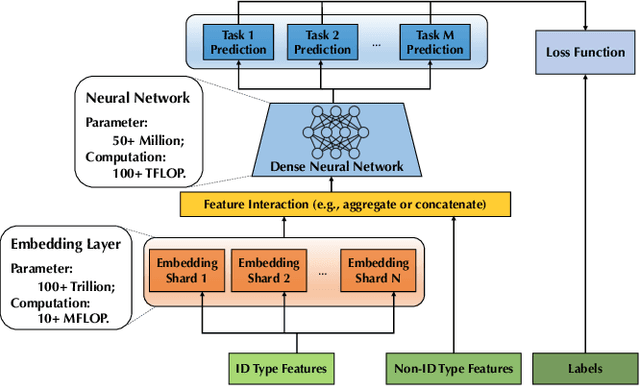
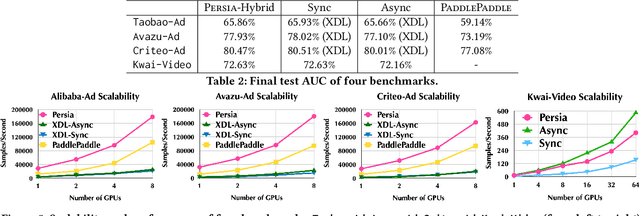
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
POSO: Personalized Cold Start Modules for Large-scale Recommender Systems
Aug 24, 2021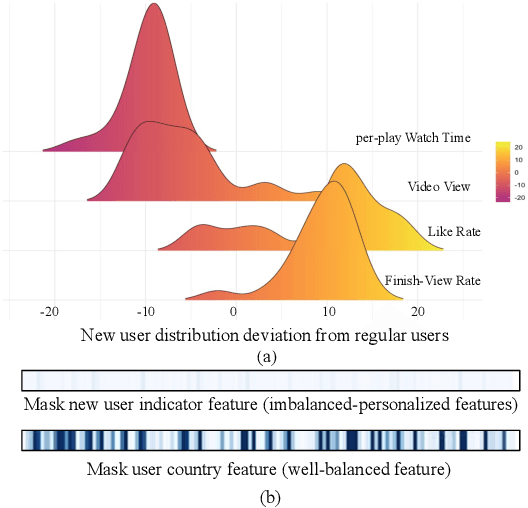
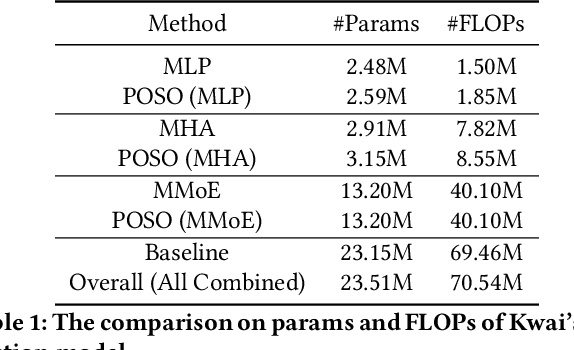
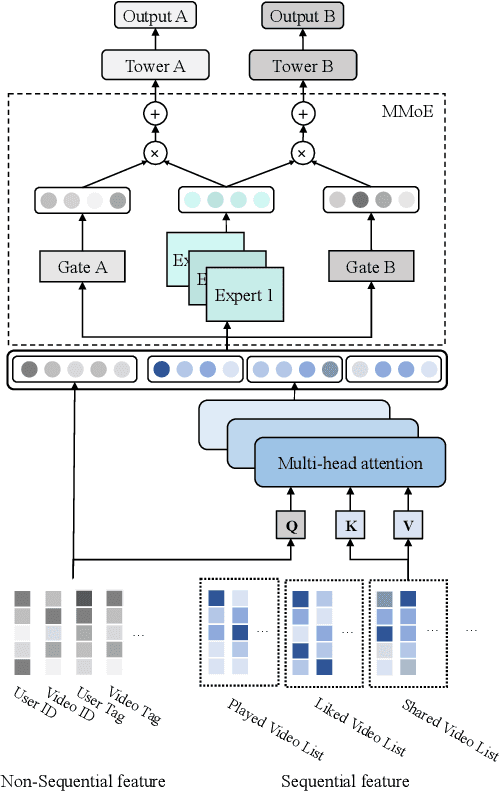
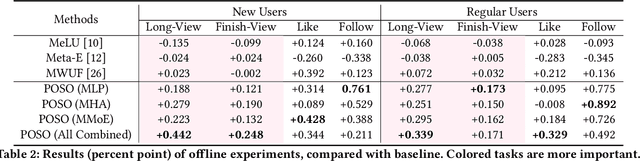
Recommendation for new users, also called user cold start, has been a well-recognized challenge for online recommender systems. Most existing methods view the crux as the lack of initial data. However, in this paper, we argue that there are neglected problems: 1) New users' behaviour follows much different distributions from regular users. 2) Although personalized features are involved, heavily imbalanced samples prevent the model from balancing new/regular user distributions, as if the personalized features are overwhelmed. We name the problem as the "submergence" of personalization. To tackle this problem, we propose a novel module: Personalized COld Start MOdules (POSO). Considering from a model architecture perspective, POSO personalizes existing modules by introducing multiple user-group-specialized sub-modules. Then, it fuses their outputs by personalized gates, resulting in comprehensive representations. In such way, POSO projects imbalanced features to even modules. POSO can be flexibly integrated into many existing modules and effectively improves their performance with negligible computational overheads. The proposed method shows remarkable advantage in industrial scenario. It has been deployed on the large-scale recommender system of Kwai, and improves new user Watch Time by a large margin (+7.75%). Moreover, POSO can be further generalized to regular users, inactive users and returning users (+2%-3% on Watch Time), as well as item cold start (+3.8% on Watch Time). Its effectiveness has also been verified on public dataset (MovieLens 20M). We believe such practical experience can be well generalized to other scenarios.