 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Subframe Splitting and Spatio-Temporal Motion Entangled Sparse Attention for RGB-E Tracking
Sep 26, 2024Event-based bionic camera asynchronously captures dynamic scenes with high temporal resolution and high dynamic range, offering potential for the integration of events and RGB under conditions of illumination degradation and fast motion. Existing RGB-E tracking methods model event characteristics utilising attention mechanism of Transformer before integrating both modalities. Nevertheless, these methods involve aggregating the event stream into a single event frame, lacking the utilisation of the temporal information inherent in the event stream.Moreover, the traditional attention mechanism is well-suited for dense semantic features, while the attention mechanism for sparse event features require revolution. In this paper, we propose a dynamic event subframe splitting strategy to split the event stream into more fine-grained event clusters, aiming to capture spatio-temporal features that contain motion cues. Based on this, we design an event-based sparse attention mechanism to enhance the interaction of event features in temporal and spatial dimensions. The experimental results indicate that our method outperforms existing state-of-the-art methods on the FE240 and COESOT datasets, providing an effective processing manner for the event data.
Revisiting RGBT Tracking Benchmarks from the Perspective of Modality Validity: A New Benchmark, Problem, and Method
Apr 30, 2024RGBT tracking draws increasing attention due to its robustness in multi-modality warranting (MMW) scenarios, such as nighttime and bad weather, where relying on a single sensing modality fails to ensure stable tracking results. However, the existing benchmarks predominantly consist of videos collected in common scenarios where both RGB and thermal infrared (TIR) information are of sufficient quality. This makes the data unrepresentative of severe imaging conditions, leading to tracking failures in MMW scenarios. To bridge this gap, we present a new benchmark, MV-RGBT, captured specifically in MMW scenarios. In contrast with the existing datasets, MV-RGBT comprises more object categories and scenes, providing a diverse and challenging benchmark. Furthermore, for severe imaging conditions of MMW scenarios, a new problem is posed, namely \textit{when to fuse}, to stimulate the development of fusion strategies for such data. We propose a new method based on a mixture of experts, namely MoETrack, as a baseline fusion strategy. In MoETrack, each expert generates independent tracking results along with the corresponding confidence score, which is used to control the fusion process. Extensive experimental results demonstrate the significant potential of MV-RGBT in advancing RGBT tracking and elicit the conclusion that fusion is not always beneficial, especially in MMW scenarios. Significantly, the proposed MoETrack method achieves new state-of-the-art results not only on MV-RGBT, but also on standard benchmarks, such as RGBT234, LasHeR, and the short-term split of VTUAV (VTUAV-ST). More information of MV-RGBT and the source code of MoETrack will be released at https://github.com/Zhangyong-Tang/MoETrack.
Generative-based Fusion Mechanism for Multi-Modal Tracking
Sep 07, 2023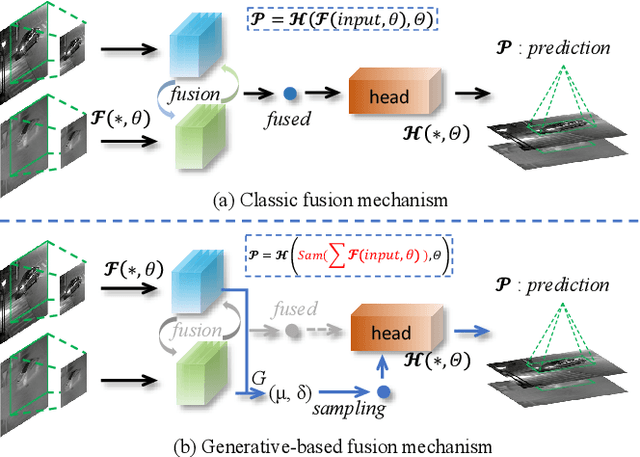

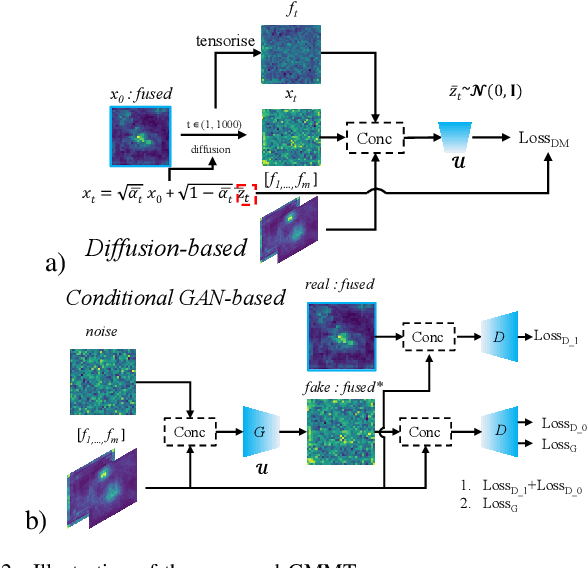

Generative models (GMs) have received increasing research interest for their remarkable capacity to achieve comprehensive understanding. However, their potential application in the domain of multi-modal tracking has remained relatively unexplored. In this context, we seek to uncover the potential of harnessing generative techniques to address the critical challenge, information fusion, in multi-modal tracking. In this paper, we delve into two prominent GM techniques, namely, Conditional Generative Adversarial Networks (CGANs) and Diffusion Models (DMs). Different from the standard fusion process where the features from each modality are directly fed into the fusion block, we condition these multi-modal features with random noise in the GM framework, effectively transforming the original training samples into harder instances. This design excels at extracting discriminative clues from the features, enhancing the ultimate tracking performance. To quantitatively gauge the effectiveness of our approach, we conduct extensive experiments across two multi-modal tracking tasks, three baseline methods, and three challenging benchmarks. The experimental results demonstrate that the proposed generative-based fusion mechanism achieves state-of-the-art performance, setting new records on LasHeR and RGBD1K.
The 3rd Anti-UAV Workshop & Challenge: Methods and Results
May 12, 2023


The 3rd Anti-UAV Workshop & Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two main differences between this year's competition and the previous two. First, we have expanded the existing dataset, and for the first time, released a training set so that participants can focus on improving their models. Second, we set up two tracks for the first time, i.e., Anti-UAV Tracking and Anti-UAV Detection & Tracking. Around 76 participating teams from the globe competed in the 3rd Anti-UAV Challenge. In this paper, we provide a brief summary of the 3rd Anti-UAV Workshop & Challenge including brief introductions to the top three methods in each track. The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.
Exploring Fusion Strategies for Accurate RGBT Visual Object Tracking
Jan 21, 2022
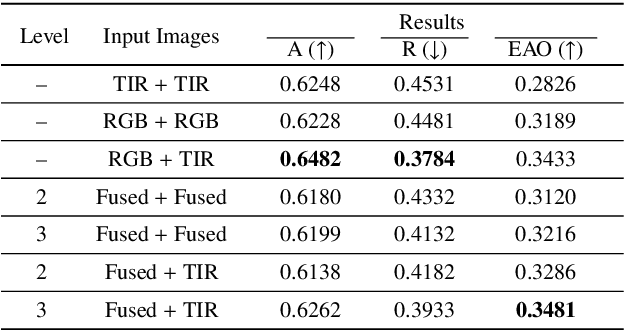
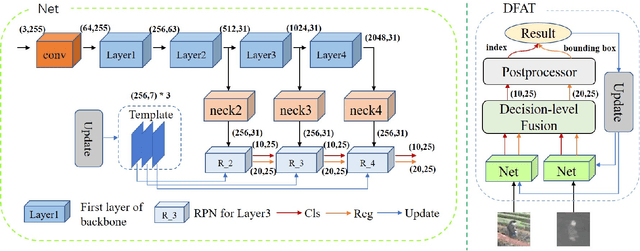
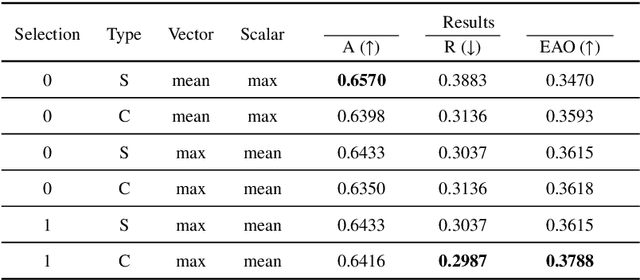
We address the problem of multi-modal object tracking in video and explore various options of fusing the complementary information conveyed by the visible (RGB) and thermal infrared (TIR) modalities including pixel-level, feature-level and decision-level fusion. Specifically, different from the existing methods, paradigm of image fusion task is heeded for fusion at pixel level. Feature-level fusion is fulfilled by attention mechanism with channels excited optionally. Besides, at decision level, a novel fusion strategy is put forward since an effortless averaging configuration has shown the superiority. The effectiveness of the proposed decision-level fusion strategy owes to a number of innovative contributions, including a dynamic weighting of the RGB and TIR contributions and a linear template update operation. A variant of which produced the winning tracker at the Visual Object Tracking Challenge 2020 (VOT-RGBT2020). The concurrent exploration of innovative pixel- and feature-level fusion strategies highlights the advantages of the proposed decision-level fusion method. Extensive experimental results on three challenging datasets, \textit{i.e.}, GTOT, VOT-RGBT2019, and VOT-RGBT2020, demonstrate the effectiveness and robustness of the proposed method, compared to the state-of-the-art approaches. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/DFAT}.
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021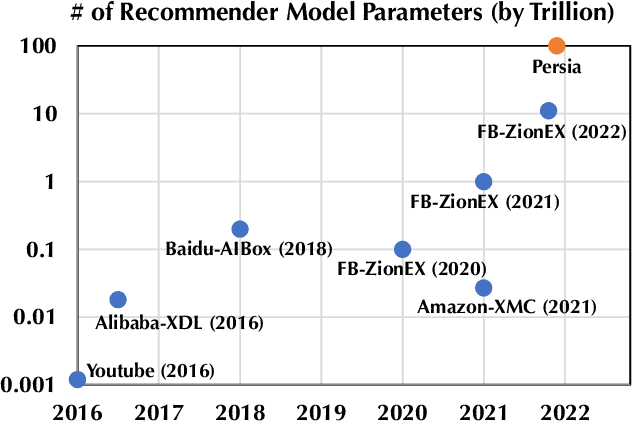
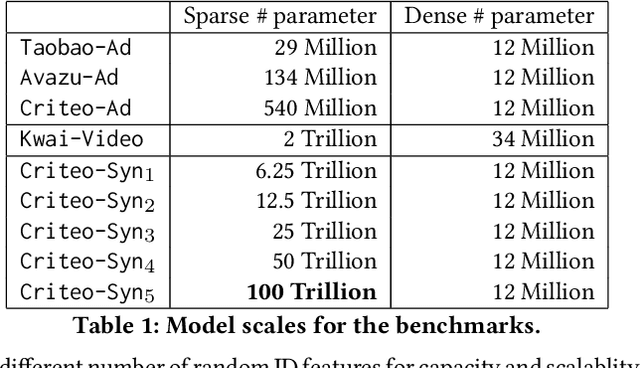
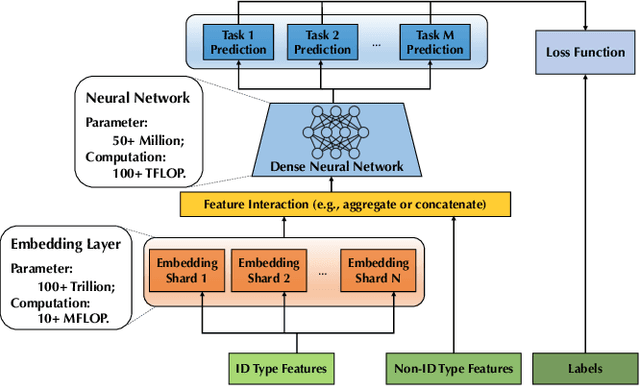
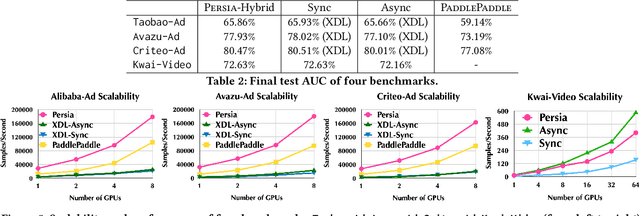
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
A Quantum-Inspired Probabilistic Model for the Inverse Design of Meta-Structures
Nov 11, 2020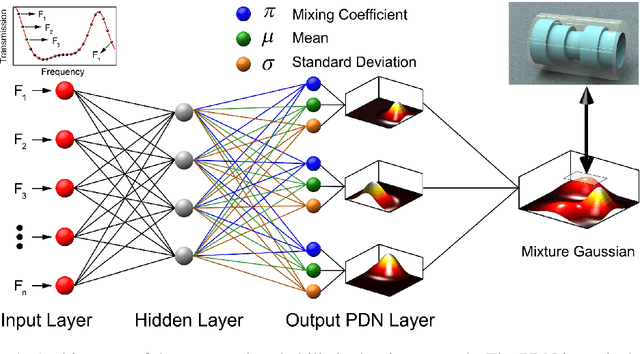

In quantum mechanics, a norm squared wave function can be interpreted as the probability density that describes the likelihood of a particle to be measured in a given position or momentum. This statistical property is at the core of the microcosmos. Meanwhile, machine learning inverse design of materials raised intensive attention, resulting in various intelligent systems for matter engineering. Here, inspired by quantum theory, we propose a probabilistic deep learning paradigm for the inverse design of functional meta-structures. Our probability-density-based neural network (PDN) can accurately capture all plausible meta-structures to meet the desired performances. Local maxima in probability density distribution correspond to the most likely candidates. We verify this approach by designing multiple meta-structures for each targeted transmission spectrum to enrich design choices.