 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Fusion Strategies for Accurate RGBT Visual Object Tracking
Paper and Code

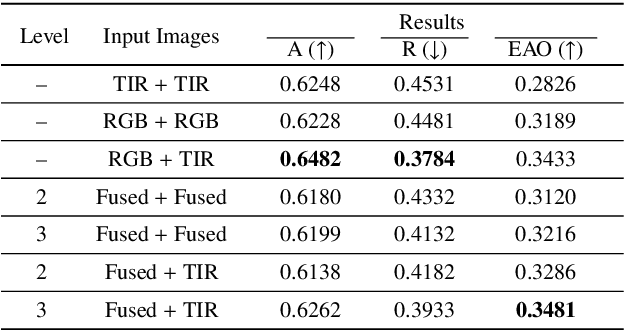
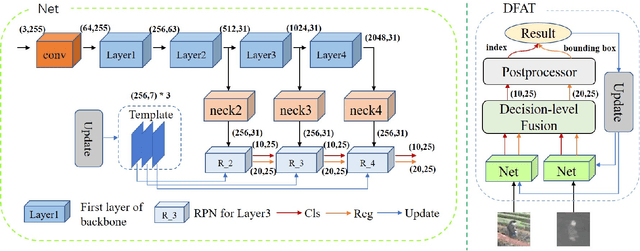
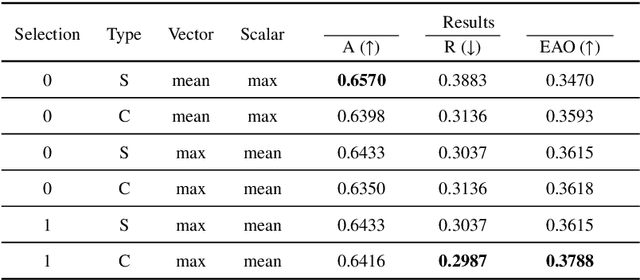
We address the problem of multi-modal object tracking in video and explore various options of fusing the complementary information conveyed by the visible (RGB) and thermal infrared (TIR) modalities including pixel-level, feature-level and decision-level fusion. Specifically, different from the existing methods, paradigm of image fusion task is heeded for fusion at pixel level. Feature-level fusion is fulfilled by attention mechanism with channels excited optionally. Besides, at decision level, a novel fusion strategy is put forward since an effortless averaging configuration has shown the superiority. The effectiveness of the proposed decision-level fusion strategy owes to a number of innovative contributions, including a dynamic weighting of the RGB and TIR contributions and a linear template update operation. A variant of which produced the winning tracker at the Visual Object Tracking Challenge 2020 (VOT-RGBT2020). The concurrent exploration of innovative pixel- and feature-level fusion strategies highlights the advantages of the proposed decision-level fusion method. Extensive experimental results on three challenging datasets, \textit{i.e.}, GTOT, VOT-RGBT2019, and VOT-RGBT2020, demonstrate the effectiveness and robustness of the proposed method, compared to the state-of-the-art approaches. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/DFAT}.