 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaNet: Towards More Efficient and Consistent Infrared and Visible Image Fusion Assessment
Apr 03, 2026Evaluation is essential in image fusion research, yet most existing metrics are directly borrowed from other vision tasks without proper adaptation. These traditional metrics, often based on complex image transformations, not only fail to capture the true quality of the fusion results but also are computationally demanding. To address these issues, we propose a unified evaluation framework specifically tailored for image fusion. At its core is a lightweight network designed efficiently to approximate widely used metrics, following a divide-and-conquer strategy. Unlike conventional approaches that directly assess similarity between fused and source images, we first decompose the fusion result into infrared and visible components. The evaluation model is then used to measure the degree of information preservation in these separated components, effectively disentangling the fusion evaluation process. During training, we incorporate a contrastive learning strategy and inform our evaluation model by perceptual scene assessment provided by a large language model. Last, we propose the first consistency evaluation framework, which measures the alignment between image fusion metrics and human visual perception, using both independent no-reference scores and downstream tasks performance as objective references. Extensive experiments show that our learning-based evaluation paradigm delivers both superior efficiency (up to 1,000 times faster) and greater consistency across a range of standard image fusion benchmarks. Our code will be publicly available at https://github.com/AWCXV/EvaNet.
Learning Progressive Adaptation for Multi-Modal Tracking
Mar 22, 2026Due to the limited availability of paired multi-modal data, multi-modal trackers are typically built by adopting pre-trained RGB models with parameter-efficient fine-tuning modules. However, these fine-tuning methods overlook advanced adaptations for applying RGB pre-trained models and fail to modulate a single specific modality, cross-modal interactions, and the prediction head. To address the issues, we propose to perform Progressive Adaptation for Multi-Modal Tracking (PATrack). This innovative approach incorporates modality-dependent, modality-entangled, and task-level adapters, effectively bridging the gap in adapting RGB pre-trained networks to multi-modal data through a progressive strategy. Specifically, modality-specific information is enhanced through the modality-dependent adapter, decomposing the high- and low-frequency components, which ensures a more robust feature representation within each modality. The inter-modal interactions are introduced in the modality-entangled adapter, which implements a cross-attention operation guided by inter-modal shared information, ensuring the reliability of features conveyed between modalities. Additionally, recognising that the strong inductive bias of the prediction head does not adapt to the fused information, a task-level adapter specific to the prediction head is introduced. In summary, our design integrates intra-modal, inter-modal, and task-level adapters into a unified framework. Extensive experiments on RGB+Thermal, RGB+Depth, and RGB+Event tracking tasks demonstrate that our method shows impressive performance against state-of-the-art methods. Code is available at https://github.com/ouha1998/Learning-Progressive-Adaptation-for-Multi-Modal-Tracking.
UASTrack: A Unified Adaptive Selection Framework with Modality-Customization in Single Object Tracking
Feb 25, 2025



Multi-modal tracking is essential in single-object tracking (SOT), as different sensor types contribute unique capabilities to overcome challenges caused by variations in object appearance. However, existing unified RGB-X trackers (X represents depth, event, or thermal modality) either rely on the task-specific training strategy for individual RGB-X image pairs or fail to address the critical importance of modality-adaptive perception in real-world applications. In this work, we propose UASTrack, a unified adaptive selection framework that facilitates both model and parameter unification, as well as adaptive modality discrimination across various multi-modal tracking tasks. To achieve modality-adaptive perception in joint RGB-X pairs, we design a Discriminative Auto-Selector (DAS) capable of identifying modality labels, thereby distinguishing the data distributions of auxiliary modalities. Furthermore, we propose a Task-Customized Optimization Adapter (TCOA) tailored to various modalities in the latent space. This strategy effectively filters noise redundancy and mitigates background interference based on the specific characteristics of each modality. Extensive comparisons conducted on five benchmarks including LasHeR, GTOT, RGBT234, VisEvent, and DepthTrack, covering RGB-T, RGB-E, and RGB-D tracking scenarios, demonstrate our innovative approach achieves comparative performance by introducing only additional training parameters of 1.87M and flops of 1.95G. The code will be available at https://github.com/wanghe/UASTrack.
TENet: Targetness Entanglement Incorporating with Multi-Scale Pooling and Mutually-Guided Fusion for RGB-E Object Tracking
May 08, 2024



There is currently strong interest in improving visual object tracking by augmenting the RGB modality with the output of a visual event camera that is particularly informative about the scene motion. However, existing approaches perform event feature extraction for RGB-E tracking using traditional appearance models, which have been optimised for RGB only tracking, without adapting it for the intrinsic characteristics of the event data. To address this problem, we propose an Event backbone (Pooler), designed to obtain a high-quality feature representation that is cognisant of the innate characteristics of the event data, namely its sparsity. In particular, Multi-Scale Pooling is introduced to capture all the motion feature trends within event data through the utilisation of diverse pooling kernel sizes. The association between the derived RGB and event representations is established by an innovative module performing adaptive Mutually Guided Fusion (MGF). Extensive experimental results show that our method significantly outperforms state-of-the-art trackers on two widely used RGB-E tracking datasets, including VisEvent and COESOT, where the precision and success rates on COESOT are improved by 4.9% and 5.2%, respectively. Our code will be available at https://github.com/SSSpc333/TENet.
Revisiting RGBT Tracking Benchmarks from the Perspective of Modality Validity: A New Benchmark, Problem, and Method
Apr 30, 2024RGBT tracking draws increasing attention due to its robustness in multi-modality warranting (MMW) scenarios, such as nighttime and bad weather, where relying on a single sensing modality fails to ensure stable tracking results. However, the existing benchmarks predominantly consist of videos collected in common scenarios where both RGB and thermal infrared (TIR) information are of sufficient quality. This makes the data unrepresentative of severe imaging conditions, leading to tracking failures in MMW scenarios. To bridge this gap, we present a new benchmark, MV-RGBT, captured specifically in MMW scenarios. In contrast with the existing datasets, MV-RGBT comprises more object categories and scenes, providing a diverse and challenging benchmark. Furthermore, for severe imaging conditions of MMW scenarios, a new problem is posed, namely \textit{when to fuse}, to stimulate the development of fusion strategies for such data. We propose a new method based on a mixture of experts, namely MoETrack, as a baseline fusion strategy. In MoETrack, each expert generates independent tracking results along with the corresponding confidence score, which is used to control the fusion process. Extensive experimental results demonstrate the significant potential of MV-RGBT in advancing RGBT tracking and elicit the conclusion that fusion is not always beneficial, especially in MMW scenarios. Significantly, the proposed MoETrack method achieves new state-of-the-art results not only on MV-RGBT, but also on standard benchmarks, such as RGBT234, LasHeR, and the short-term split of VTUAV (VTUAV-ST). More information of MV-RGBT and the source code of MoETrack will be released at https://github.com/Zhangyong-Tang/MoETrack.
TextFusion: Unveiling the Power of Textual Semantics for Controllable Image Fusion
Dec 21, 2023Advanced image fusion methods are devoted to generating the fusion results by aggregating the complementary information conveyed by the source images. However, the difference in the source-specific manifestation of the imaged scene content makes it difficult to design a robust and controllable fusion process. We argue that this issue can be alleviated with the help of higher-level semantics, conveyed by the text modality, which should enable us to generate fused images for different purposes, such as visualisation and downstream tasks, in a controllable way. This is achieved by exploiting a vision-and-language model to build a coarse-to-fine association mechanism between the text and image signals. With the guidance of the association maps, an affine fusion unit is embedded in the transformer network to fuse the text and vision modalities at the feature level. As another ingredient of this work, we propose the use of textual attention to adapt image quality assessment to the fusion task. To facilitate the implementation of the proposed text-guided fusion paradigm, and its adoption by the wider research community, we release a text-annotated image fusion dataset IVT. Extensive experiments demonstrate that our approach (TextFusion) consistently outperforms traditional appearance-based fusion methods. Our code and dataset will be publicly available on the project homepage.
Generative-based Fusion Mechanism for Multi-Modal Tracking
Sep 07, 2023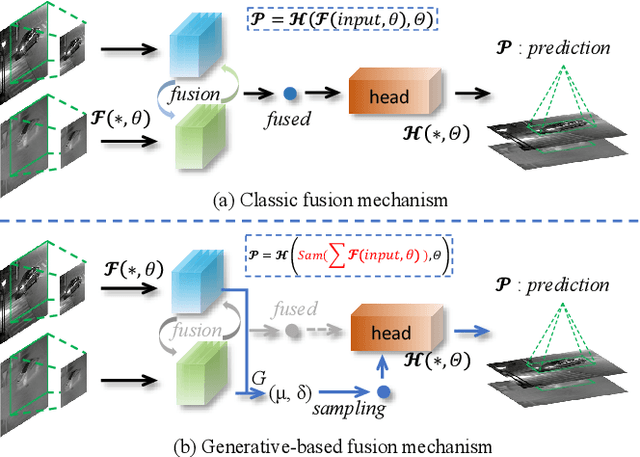

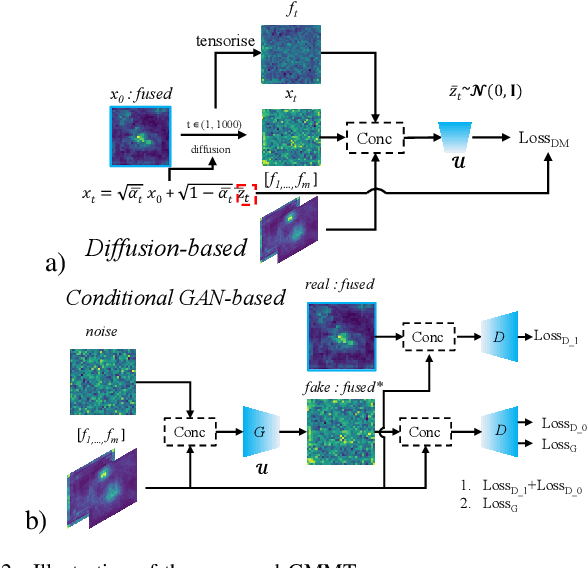

Generative models (GMs) have received increasing research interest for their remarkable capacity to achieve comprehensive understanding. However, their potential application in the domain of multi-modal tracking has remained relatively unexplored. In this context, we seek to uncover the potential of harnessing generative techniques to address the critical challenge, information fusion, in multi-modal tracking. In this paper, we delve into two prominent GM techniques, namely, Conditional Generative Adversarial Networks (CGANs) and Diffusion Models (DMs). Different from the standard fusion process where the features from each modality are directly fed into the fusion block, we condition these multi-modal features with random noise in the GM framework, effectively transforming the original training samples into harder instances. This design excels at extracting discriminative clues from the features, enhancing the ultimate tracking performance. To quantitatively gauge the effectiveness of our approach, we conduct extensive experiments across two multi-modal tracking tasks, three baseline methods, and three challenging benchmarks. The experimental results demonstrate that the proposed generative-based fusion mechanism achieves state-of-the-art performance, setting new records on LasHeR and RGBD1K.
RGBD1K: A Large-scale Dataset and Benchmark for RGB-D Object Tracking
Aug 21, 2022



RGB-D object tracking has attracted considerable attention recently, achieving promising performance thanks to the symbiosis between visual and depth channels. However, given a limited amount of annotated RGB-D tracking data, most state-of-the-art RGB-D trackers are simple extensions of high-performance RGB-only trackers, without fully exploiting the underlying potential of the depth channel in the offline training stage. To address the dataset deficiency issue, a new RGB-D dataset named RGBD1K is released in this paper. The RGBD1K contains 1,050 sequences with about 2.5M frames in total. To demonstrate the benefits of training on a larger RGB-D data set in general, and RGBD1K in particular, we develop a transformer-based RGB-D tracker, named SPT, as a baseline for future visual object tracking studies using the new dataset. The results, of extensive experiments using the SPT tracker emonstrate the potential of the RGBD1K dataset to improve the performance of RGB-D tracking, inspiring future developments of effective tracker designs. The dataset and codes will be available on the project homepage: https://will.be.available.at.this.website.
Temporal Aggregation for Adaptive RGBT Tracking
Jan 29, 2022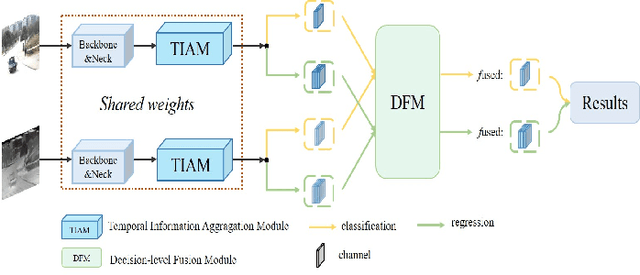
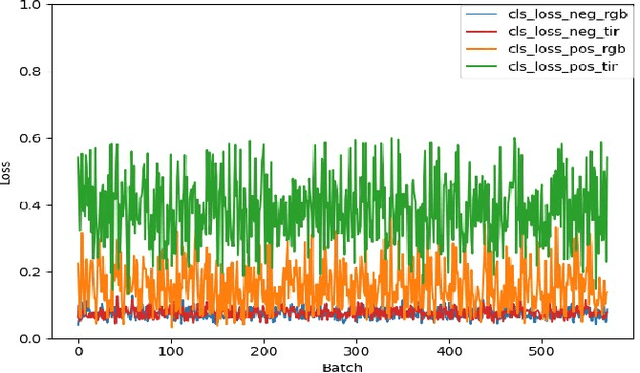
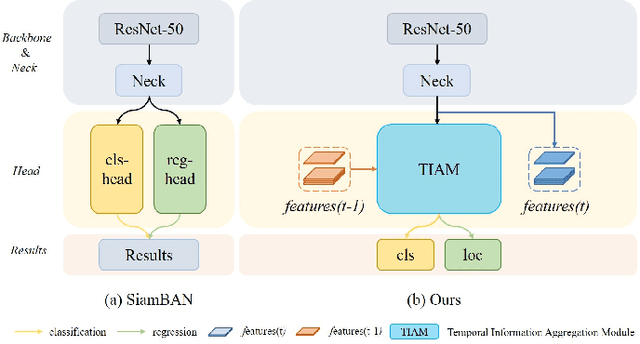
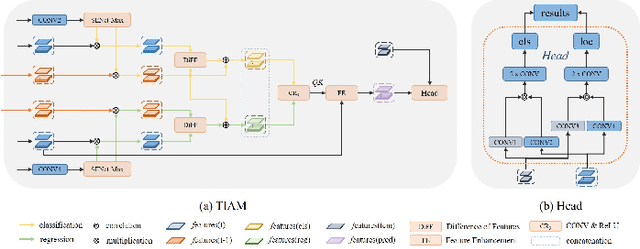
Visual object tracking with RGB and thermal infrared (TIR) spectra available, shorted in RGBT tracking, is a novel and challenging research topic which draws increasing attention nowadays. In this paper, we propose an RGBT tracker which takes spatio-temporal clues into account for robust appearance model learning, and simultaneously, constructs an adaptive fusion sub-network for cross-modal interactions. Unlike most existing RGBT trackers that implement object tracking tasks with only spatial information included, temporal information is further considered in this method. Specifically, different from traditional Siamese trackers, which only obtain one search image during the process of picking up template-search image pairs, an extra search sample adjacent to the original one is selected to predict the temporal transformation, resulting in improved robustness of tracking performance.As for multi-modal tracking, constrained to the limited RGBT datasets, the adaptive fusion sub-network is appended to our method at the decision level to reflect the complementary characteristics contained in two modalities. To design a thermal infrared assisted RGB tracker, the outputs of the classification head from the TIR modality are taken into consideration before the residual connection from the RGB modality. Extensive experimental results on three challenging datasets, i.e. VOT-RGBT2019, GTOT and RGBT210, verify the effectiveness of our method. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/TAAT}}.
A Survey for Deep RGBT Tracking
Jan 29, 2022
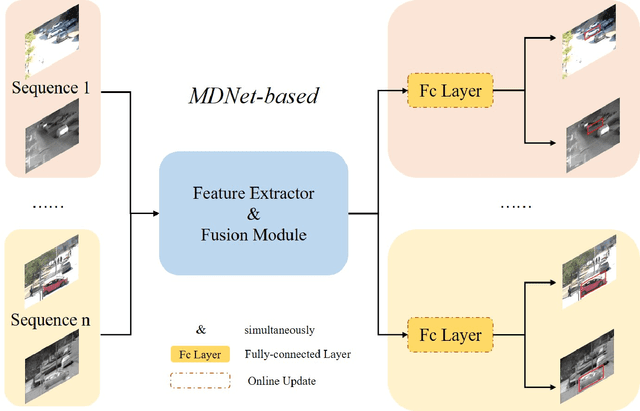
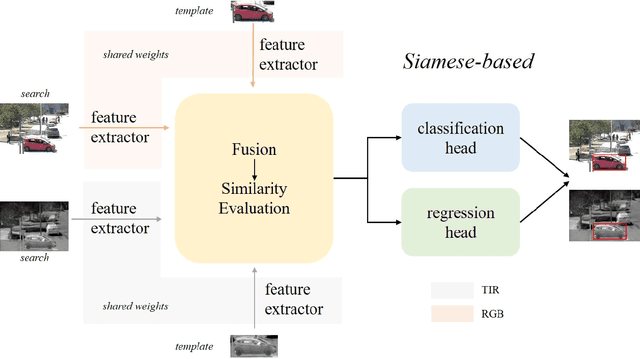
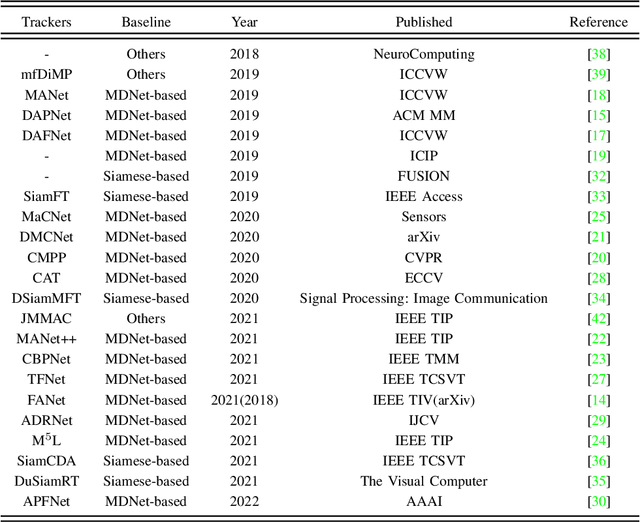
Visual object tracking with the visible (RGB) and thermal infrared (TIR) electromagnetic waves, shorted in RGBT tracking, recently draws increasing attention in the tracking community. Considering the rapid development of deep learning, a survey for the recent deep neural network based RGBT trackers is presented in this paper. Firstly, we give brief introduction for the RGBT trackers concluded into this category. Then, a comparison among the existing RGBT trackers on several challenging benchmarks is given statistically. Specifically, MDNet and Siamese architectures are the two mainstream frameworks in the RGBT community, especially the former. Trackers based on MDNet achieve higher performance while Siamese-based trackers satisfy the real-time requirement. In summary, since the large-scale dataset LasHeR is published, the integration of end-to-end framework, e.g., Siamese and Transformer, should be further considered to fulfil the real-time as well as more robust performance. Furthermore, the mathematical meaning should be more considered during designing the network. This survey can be treated as a look-up-table for researchers who are concerned about RGBT tracking.