 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Semantic-constrained Adversarial Example with Instruction Uncertainty Reduction
Oct 27, 2025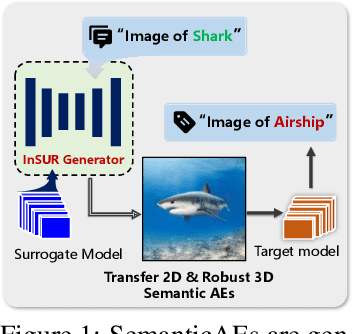
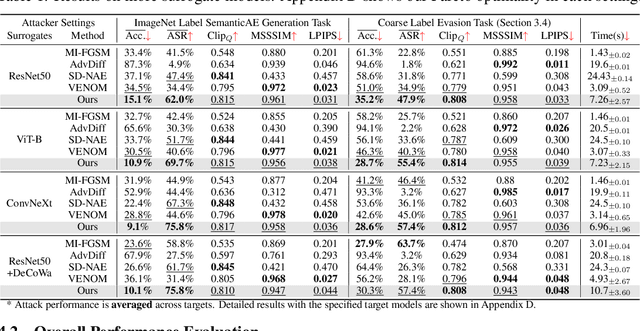
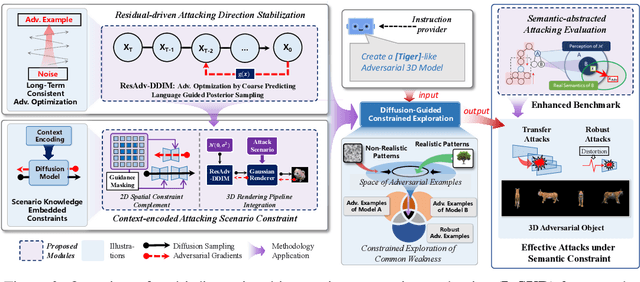

Recently, semantically constrained adversarial examples (SemanticAE), which are directly generated from natural language instructions, have become a promising avenue for future research due to their flexible attacking forms. To generate SemanticAEs, current methods fall short of satisfactory attacking ability as the key underlying factors of semantic uncertainty in human instructions, such as referring diversity, descriptive incompleteness, and boundary ambiguity, have not been fully investigated. To tackle the issues, this paper develops a multi-dimensional instruction uncertainty reduction (InSUR) framework to generate more satisfactory SemanticAE, i.e., transferable, adaptive, and effective. Specifically, in the dimension of the sampling method, we propose the residual-driven attacking direction stabilization to alleviate the unstable adversarial optimization caused by the diversity of language references. By coarsely predicting the language-guided sampling process, the optimization process will be stabilized by the designed ResAdv-DDIM sampler, therefore releasing the transferable and robust adversarial capability of multi-step diffusion models. In task modeling, we propose the context-encoded attacking scenario constraint to supplement the missing knowledge from incomplete human instructions. Guidance masking and renderer integration are proposed to regulate the constraints of 2D/3D SemanticAE, activating stronger scenario-adapted attacks. Moreover, in the dimension of generator evaluation, we propose the semantic-abstracted attacking evaluation enhancement by clarifying the evaluation boundary, facilitating the development of more effective SemanticAE generators. Extensive experiments demonstrate the superiority of the transfer attack performance of InSUR. Moreover, we realize the reference-free generation of semantically constrained 3D adversarial examples for the first time.
MoPE: Mixture of Prefix Experts for Zero-Shot Dialogue State Tracking
Apr 12, 2024



Zero-shot dialogue state tracking (DST) transfers knowledge to unseen domains, reducing the cost of annotating new datasets. Previous zero-shot DST models mainly suffer from domain transferring and partial prediction problems. To address these challenges, we propose Mixture of Prefix Experts (MoPE) to establish connections between similar slots in different domains, which strengthens the model transfer performance in unseen domains. Empirical results demonstrate that MoPE-DST achieves the joint goal accuracy of 57.13% on MultiWOZ2.1 and 55.40% on SGD.
DiffusionDialog: A Diffusion Model for Diverse Dialog Generation with Latent Space
Apr 10, 2024



In real-life conversations, the content is diverse, and there exists the one-to-many problem that requires diverse generation. Previous studies attempted to introduce discrete or Gaussian-based continuous latent variables to address the one-to-many problem, but the diversity is limited. Recently, diffusion models have made breakthroughs in computer vision, and some attempts have been made in natural language processing. In this paper, we propose DiffusionDialog, a novel approach to enhance the diversity of dialogue generation with the help of diffusion model. In our approach, we introduce continuous latent variables into the diffusion model. The problem of using latent variables in the dialog task is how to build both an effective prior of the latent space and an inferring process to obtain the proper latent given the context. By combining the encoder and latent-based diffusion model, we encode the response's latent representation in a continuous space as the prior, instead of fixed Gaussian distribution or simply discrete ones. We then infer the latent by denoising step by step with the diffusion model. The experimental results show that our model greatly enhances the diversity of dialog responses while maintaining coherence. Furthermore, in further analysis, we find that our diffusion model achieves high inference efficiency, which is the main challenge of applying diffusion models in natural language processing.
RGBD1K: A Large-scale Dataset and Benchmark for RGB-D Object Tracking
Aug 21, 2022



RGB-D object tracking has attracted considerable attention recently, achieving promising performance thanks to the symbiosis between visual and depth channels. However, given a limited amount of annotated RGB-D tracking data, most state-of-the-art RGB-D trackers are simple extensions of high-performance RGB-only trackers, without fully exploiting the underlying potential of the depth channel in the offline training stage. To address the dataset deficiency issue, a new RGB-D dataset named RGBD1K is released in this paper. The RGBD1K contains 1,050 sequences with about 2.5M frames in total. To demonstrate the benefits of training on a larger RGB-D data set in general, and RGBD1K in particular, we develop a transformer-based RGB-D tracker, named SPT, as a baseline for future visual object tracking studies using the new dataset. The results, of extensive experiments using the SPT tracker emonstrate the potential of the RGBD1K dataset to improve the performance of RGB-D tracking, inspiring future developments of effective tracker designs. The dataset and codes will be available on the project homepage: https://will.be.available.at.this.website.
NeuSE: A Neural Snapshot Ensemble Method for Collaborative Filtering
Apr 15, 2021

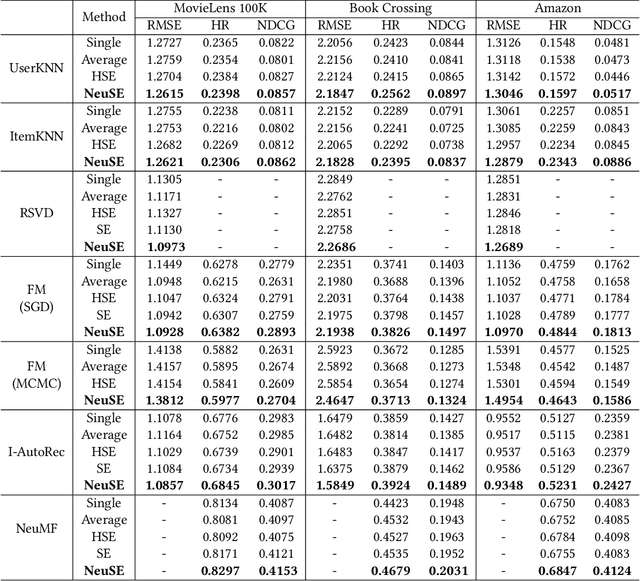

In collaborative filtering (CF) algorithms, the optimal models are usually learned by globally minimizing the empirical risks averaged over all the observed data. However, the global models are often obtained via a performance tradeoff among users/items, i.e., not all users/items are perfectly fitted by the global models due to the hard non-convex optimization problems in CF algorithms. Ensemble learning can address this issue by learning multiple diverse models but usually suffer from efficiency issue on large datasets or complex algorithms. In this paper, we keep the intermediate models obtained during global model learning as the snapshot models, and then adaptively combine the snapshot models for individual user-item pairs using a memory network-based method. Empirical studies on three real-world datasets show that the proposed method can extensively and significantly improve the accuracy (up to 15.9% relatively) when applied to a variety of existing collaborative filtering methods.