 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALT: When More Rollouts Don't Help in Group-Based Policy Optimization and How to Make Them Matter
Jun 04, 2026Reinforcement learning with verifiable rewards (RLVR) often adopts GRPO-style group-relative updates, sampling multiple rollouts per prompt to construct normalized learning signals. However, merely increasing the number of rollouts does not reliably strengthen learning: under GRPO-style group normalization, per-rollout policy-gradient features can concentrate into a low-rank, signed geometry, causing substantial cancellation during aggregation and weakening the effective update. We address this failure mode with SALT, a Subspace-Adaptive geometry pLug-in componenT that uses sample-wise gradient geometry to reweight the coefficients of group-relative updates. SALT estimates a dominant shared subspace from the mini-batch Gram geometry, decomposes group-relative coefficients into shared and residual channels, and adaptively amplifies the residual channel when signed cancellation is severe. Across diverse reasoning-oriented RLVR benchmarks and model scales, SALT improves effective update geometry and performance without modifying the reward model or the rollout sampling procedure
DiffusionDialog: A Diffusion Model for Diverse Dialog Generation with Latent Space
Apr 10, 2024



In real-life conversations, the content is diverse, and there exists the one-to-many problem that requires diverse generation. Previous studies attempted to introduce discrete or Gaussian-based continuous latent variables to address the one-to-many problem, but the diversity is limited. Recently, diffusion models have made breakthroughs in computer vision, and some attempts have been made in natural language processing. In this paper, we propose DiffusionDialog, a novel approach to enhance the diversity of dialogue generation with the help of diffusion model. In our approach, we introduce continuous latent variables into the diffusion model. The problem of using latent variables in the dialog task is how to build both an effective prior of the latent space and an inferring process to obtain the proper latent given the context. By combining the encoder and latent-based diffusion model, we encode the response's latent representation in a continuous space as the prior, instead of fixed Gaussian distribution or simply discrete ones. We then infer the latent by denoising step by step with the diffusion model. The experimental results show that our model greatly enhances the diversity of dialog responses while maintaining coherence. Furthermore, in further analysis, we find that our diffusion model achieves high inference efficiency, which is the main challenge of applying diffusion models in natural language processing.
Controllable and Diverse Data Augmentation with Large Language Model for Low-Resource Open-Domain Dialogue Generation
Mar 30, 2024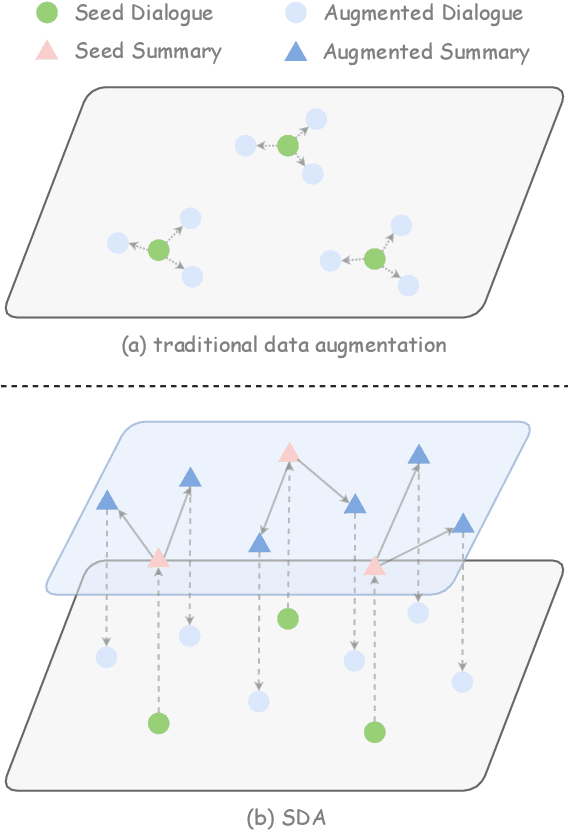



Data augmentation (DA) is crucial to mitigate model training instability and over-fitting problems in low-resource open-domain dialogue generation. However, traditional DA methods often neglect semantic data diversity, restricting the overall quality. Recently, large language models (LLM) have been used for DA to generate diversified dialogues. However, they have limited controllability and tend to generate dialogues with a distribution shift compared to the seed dialogues. To maximize the augmentation diversity and address the controllability problem, we propose \textbf{S}ummary-based \textbf{D}ialogue \textbf{A}ugmentation with LLM (SDA). Our approach enhances the controllability of LLM by using dialogue summaries as a planning tool. Based on summaries, SDA can generate high-quality and diverse dialogue data even with a small seed dataset. To evaluate the efficacy of data augmentation methods for open-domain dialogue, we designed a clustering-based metric to characterize the semantic diversity of the augmented dialogue data. The experimental results show that SDA can augment high-quality and semantically diverse dialogues given a small seed dataset and an LLM, and the augmented data can boost the performance of open-domain dialogue models.