 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable and Diverse Data Augmentation with Large Language Model for Low-Resource Open-Domain Dialogue Generation
Paper and Code
Mar 30, 2024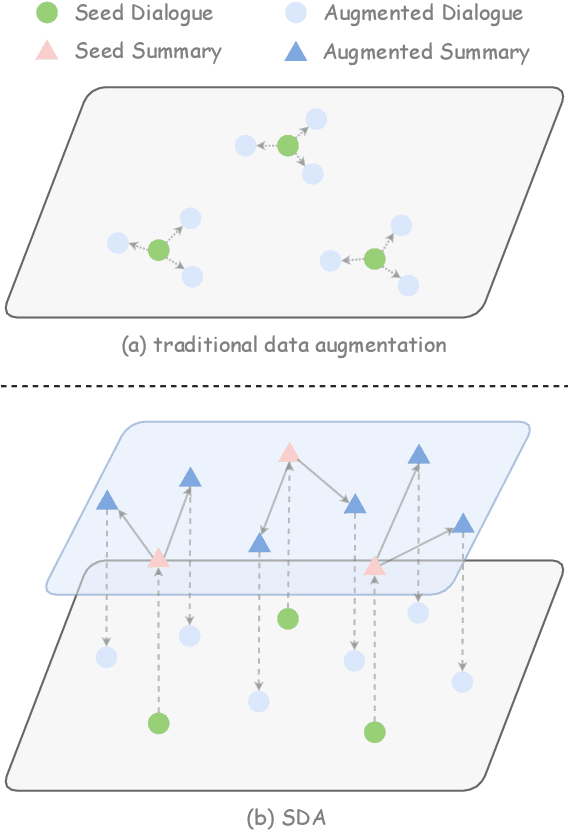



Data augmentation (DA) is crucial to mitigate model training instability and over-fitting problems in low-resource open-domain dialogue generation. However, traditional DA methods often neglect semantic data diversity, restricting the overall quality. Recently, large language models (LLM) have been used for DA to generate diversified dialogues. However, they have limited controllability and tend to generate dialogues with a distribution shift compared to the seed dialogues. To maximize the augmentation diversity and address the controllability problem, we propose \textbf{S}ummary-based \textbf{D}ialogue \textbf{A}ugmentation with LLM (SDA). Our approach enhances the controllability of LLM by using dialogue summaries as a planning tool. Based on summaries, SDA can generate high-quality and diverse dialogue data even with a small seed dataset. To evaluate the efficacy of data augmentation methods for open-domain dialogue, we designed a clustering-based metric to characterize the semantic diversity of the augmented dialogue data. The experimental results show that SDA can augment high-quality and semantically diverse dialogues given a small seed dataset and an LLM, and the augmented data can boost the performance of open-domain dialogue models.