 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaNet: Towards More Efficient and Consistent Infrared and Visible Image Fusion Assessment
Apr 03, 2026Evaluation is essential in image fusion research, yet most existing metrics are directly borrowed from other vision tasks without proper adaptation. These traditional metrics, often based on complex image transformations, not only fail to capture the true quality of the fusion results but also are computationally demanding. To address these issues, we propose a unified evaluation framework specifically tailored for image fusion. At its core is a lightweight network designed efficiently to approximate widely used metrics, following a divide-and-conquer strategy. Unlike conventional approaches that directly assess similarity between fused and source images, we first decompose the fusion result into infrared and visible components. The evaluation model is then used to measure the degree of information preservation in these separated components, effectively disentangling the fusion evaluation process. During training, we incorporate a contrastive learning strategy and inform our evaluation model by perceptual scene assessment provided by a large language model. Last, we propose the first consistency evaluation framework, which measures the alignment between image fusion metrics and human visual perception, using both independent no-reference scores and downstream tasks performance as objective references. Extensive experiments show that our learning-based evaluation paradigm delivers both superior efficiency (up to 1,000 times faster) and greater consistency across a range of standard image fusion benchmarks. Our code will be publicly available at https://github.com/AWCXV/EvaNet.
Beyond Strict Pairing: Arbitrarily Paired Training for High-Performance Infrared and Visible Image Fusion
Mar 23, 2026Infrared and visible image fusion(IVIF) combines complementary modalities while preserving natural textures and salient thermal signatures. Existing solutions predominantly rely on extensive sets of rigidly aligned image pairs for training. However, acquiring such data is often impractical due to the costly and labour-intensive alignment process. Besides, maintaining a rigid pairing setting during training restricts the volume of cross-modal relationships, thereby limiting generalisation performance. To this end, this work challenges the necessity of Strictly Paired Training Paradigm (SPTP) by systematically investigating UnPaired and Arbitrarily Paired Training Paradigms (UPTP and APTP) for high-performance IVIF. We establish a theoretical objective of APTP, reflecting the complementary nature between UPTP and SPTP. More importantly, we develop a practical framework capable of significantly enriching cross-modal relationships even with severely limited and unaligned training data. To validate our propositions, three end-to-end lightweight baselines, alongside a set of innovative loss functions, are designed to cover three classic frameworks (CNN, Transformer, GAN). Comprehensive experiments demonstrate that the proposed APTP and UPTP are feasible and capable of training models on a severely limited and content-inconsistent infrared and visible dataset, achieving performance comparable to that of a dataset 100$\times$ larger in SPTP. This finding fundamentally alleviates the cost and difficulty of data collection while enhancing model robustness from the data perspective, delivering a feasible solution for IVIF studies. The code is available at \href{https://github.com/yanglinDeng/IVIF_unpair}{\textcolor{blue}{https://github.com/yanglinDeng/IVIF\_unpair}}.
GrFormer: A Novel Transformer on Grassmann Manifold for Infrared and Visible Image Fusion
Jun 17, 2025


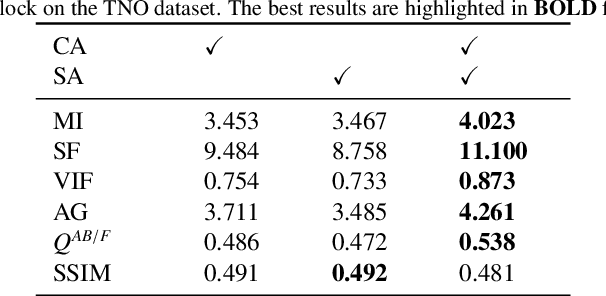
In the field of image fusion, promising progress has been made by modeling data from different modalities as linear subspaces. However, in practice, the source images are often located in a non-Euclidean space, where the Euclidean methods usually cannot encapsulate the intrinsic topological structure. Typically, the inner product performed in the Euclidean space calculates the algebraic similarity rather than the semantic similarity, which results in undesired attention output and a decrease in fusion performance. While the balance of low-level details and high-level semantics should be considered in infrared and visible image fusion task. To address this issue, in this paper, we propose a novel attention mechanism based on Grassmann manifold for infrared and visible image fusion (GrFormer). Specifically, our method constructs a low-rank subspace mapping through projection constraints on the Grassmann manifold, compressing attention features into subspaces of varying rank levels. This forces the features to decouple into high-frequency details (local low-rank) and low-frequency semantics (global low-rank), thereby achieving multi-scale semantic fusion. Additionally, to effectively integrate the significant information, we develop a cross-modal fusion strategy (CMS) based on a covariance mask to maximise the complementary properties between different modalities and to suppress the features with high correlation, which are deemed redundant. The experimental results demonstrate that our network outperforms SOTA methods both qualitatively and quantitatively on multiple image fusion benchmarks. The codes are available at https://github.com/Shaoyun2023.
Learning a Unified Degradation-aware Representation Model for Multi-modal Image Fusion
Mar 10, 2025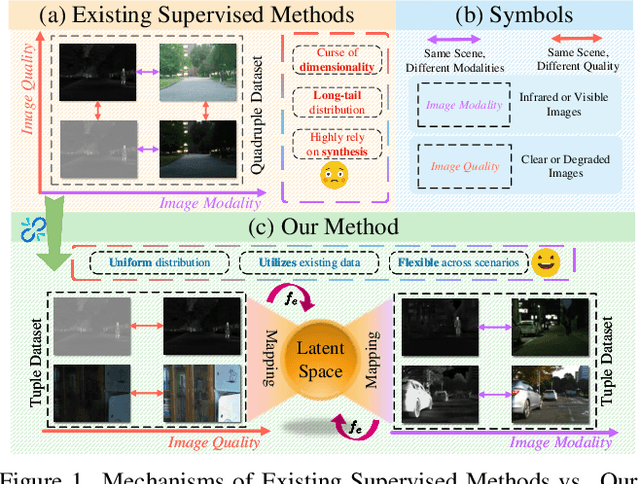
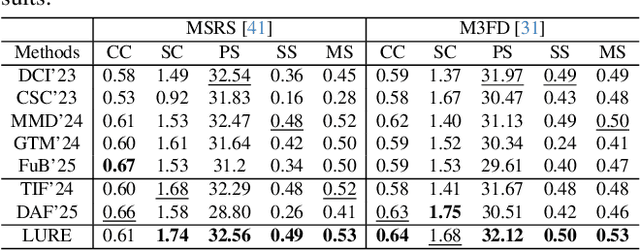
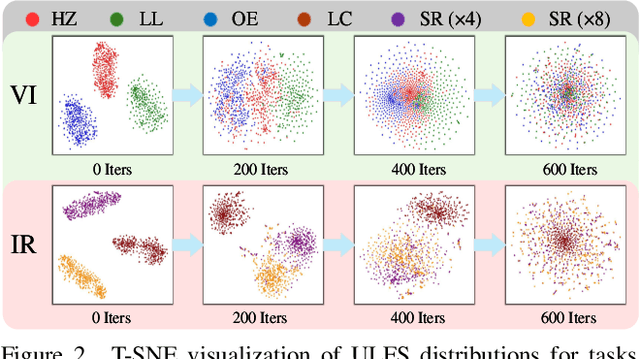
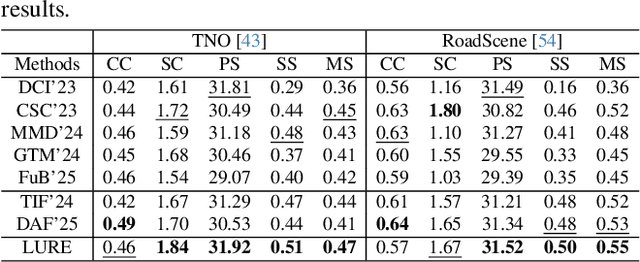
All-in-One Degradation-Aware Fusion Models (ADFMs), a class of multi-modal image fusion models, address complex scenes by mitigating degradations from source images and generating high-quality fused images. Mainstream ADFMs often rely on highly synthetic multi-modal multi-quality images for supervision, limiting their effectiveness in cross-modal and rare degradation scenarios. The inherent relationship among these multi-modal, multi-quality images of the same scene provides explicit supervision for training, but also raises above problems. To address these limitations, we present LURE, a Learning-driven Unified Representation model for infrared and visible Image Fusion, which is degradation-aware. LURE decouples multi-modal multi-quality data at the data level and recouples this relationship in a unified latent feature space (ULFS) by proposing a novel unified loss. This decoupling circumvents data-level limitations of prior models and allows leveraging real-world restoration datasets for training high-quality degradation-aware models, sidestepping above issues. To enhance text-image interaction, we refine image-text interaction and residual structures via Text-Guided Attention (TGA) and an inner residual structure. These enhances text's spatial perception of images and preserve more visual details. Experiments show our method outperforms state-of-the-art (SOTA) methods across general fusion, degradation-aware fusion, and downstream tasks. The code will be publicly available.
One Model for ALL: Low-Level Task Interaction Is a Key to Task-Agnostic Image Fusion
Feb 27, 2025Advanced image fusion methods mostly prioritise high-level missions, where task interaction struggles with semantic gaps, requiring complex bridging mechanisms. In contrast, we propose to leverage low-level vision tasks from digital photography fusion, allowing for effective feature interaction through pixel-level supervision. This new paradigm provides strong guidance for unsupervised multimodal fusion without relying on abstract semantics, enhancing task-shared feature learning for broader applicability. Owning to the hybrid image features and enhanced universal representations, the proposed GIFNet supports diverse fusion tasks, achieving high performance across both seen and unseen scenarios with a single model. Uniquely, experimental results reveal that our framework also supports single-modality enhancement, offering superior flexibility for practical applications. Our code will be available at https://github.com/AWCXV/GIFNet.
MMDRFuse: Distilled Mini-Model with Dynamic Refresh for Multi-Modality Image Fusion
Aug 28, 2024In recent years, Multi-Modality Image Fusion (MMIF) has been applied to many fields, which has attracted many scholars to endeavour to improve the fusion performance. However, the prevailing focus has predominantly been on the architecture design, rather than the training strategies. As a low-level vision task, image fusion is supposed to quickly deliver output images for observation and supporting downstream tasks. Thus, superfluous computational and storage overheads should be avoided. In this work, a lightweight Distilled Mini-Model with a Dynamic Refresh strategy (MMDRFuse) is proposed to achieve this objective. To pursue model parsimony, an extremely small convolutional network with a total of 113 trainable parameters (0.44 KB) is obtained by three carefully designed supervisions. First, digestible distillation is constructed by emphasising external spatial feature consistency, delivering soft supervision with balanced details and saliency for the target network. Second, we develop a comprehensive loss to balance the pixel, gradient, and perception clues from the source images. Third, an innovative dynamic refresh training strategy is used to collaborate history parameters and current supervision during training, together with an adaptive adjust function to optimise the fusion network. Extensive experiments on several public datasets demonstrate that our method exhibits promising advantages in terms of model efficiency and complexity, with superior performance in multiple image fusion tasks and downstream pedestrian detection application. The code of this work is publicly available at https://github.com/yanglinDeng/MMDRFuse.
* 10 pages, 8 figures, accpeted by ACM International Conference on Multimedia 2024(Oral)
CDeFuse: Continuous Decomposition for Infrared and Visible Image Fusion
Jun 07, 2024As a common image processing technique, image decomposition is often used to extract complementary information between modalities. In current decomposition-based image fusion methods, typically, source images are decomposed into three parts at single scale (i.e., visible-exclusive part, infrared-exclusive part, and common part) and lacking interaction between modalities during the decomposition process. These results in the inability of fusion images to effectively focus on finer complementary information between modalities at various scales. To address the above issue, a novel decomposition mechanism, Continuous Decomposition Fusion (CDeFuse), is proposed. Firstly, CDeFuse extends the original three-part decomposition to a more general K-part decomposition at each scale through similarity constraints to fuse multi-scale information and achieve a finer representation of decomposition features. Secondly, a Continuous Decomposition Module (CDM) is introduced to assist K-part decomposition. Its core component, State Transformer (ST), efficiently captures complementary information between modalities by utilizing multi-head self-attention mechanism. Finally, a novel decomposition loss function and the corresponding computational optimization strategy are utilized to ensure the smooth progress of the decomposition process while maintaining linear growth in time complexity with the number of decomposition results K. Extensive experiments demonstrate that our CDeFuse achieves comparable performance compared to previous methods. The code will be publicly available.
S4Fusion: Saliency-aware Selective State Space Model for Infrared Visible Image Fusion
Jun 03, 2024As one of the tasks in Image Fusion, Infrared and Visible Image Fusion aims to integrate complementary information captured by sensors of different modalities into a single image. The Selective State Space Model (SSSM), known for its ability to capture long-range dependencies, has demonstrated its potential in the field of computer vision. However, in image fusion, current methods underestimate the potential of SSSM in capturing the global spatial information of both modalities. This limitation prevents the simultaneous consideration of the global spatial information from both modalities during interaction, leading to a lack of comprehensive perception of salient targets. Consequently, the fusion results tend to bias towards one modality instead of adaptively preserving salient targets. To address this issue, we propose the Saliency-aware Selective State Space Fusion Model (S4Fusion). In our S4Fusion, the designed Cross-Modal Spatial Awareness Module (CMSA) can simultaneously focus on global spatial information from both modalities while facilitating their interaction, thereby comprehensively capturing complementary information. Additionally, S4Fusion leverages a pre-trained network to perceive uncertainty in the fused images. By minimizing this uncertainty, S4Fusion adaptively highlights salient targets from both images. Extensive experiments demonstrate that our approach produces high-quality images and enhances performance in downstream tasks.
Revisiting RGBT Tracking Benchmarks from the Perspective of Modality Validity: A New Benchmark, Problem, and Method
Apr 30, 2024RGBT tracking draws increasing attention due to its robustness in multi-modality warranting (MMW) scenarios, such as nighttime and bad weather, where relying on a single sensing modality fails to ensure stable tracking results. However, the existing benchmarks predominantly consist of videos collected in common scenarios where both RGB and thermal infrared (TIR) information are of sufficient quality. This makes the data unrepresentative of severe imaging conditions, leading to tracking failures in MMW scenarios. To bridge this gap, we present a new benchmark, MV-RGBT, captured specifically in MMW scenarios. In contrast with the existing datasets, MV-RGBT comprises more object categories and scenes, providing a diverse and challenging benchmark. Furthermore, for severe imaging conditions of MMW scenarios, a new problem is posed, namely \textit{when to fuse}, to stimulate the development of fusion strategies for such data. We propose a new method based on a mixture of experts, namely MoETrack, as a baseline fusion strategy. In MoETrack, each expert generates independent tracking results along with the corresponding confidence score, which is used to control the fusion process. Extensive experimental results demonstrate the significant potential of MV-RGBT in advancing RGBT tracking and elicit the conclusion that fusion is not always beneficial, especially in MMW scenarios. Significantly, the proposed MoETrack method achieves new state-of-the-art results not only on MV-RGBT, but also on standard benchmarks, such as RGBT234, LasHeR, and the short-term split of VTUAV (VTUAV-ST). More information of MV-RGBT and the source code of MoETrack will be released at https://github.com/Zhangyong-Tang/MoETrack.
TextFusion: Unveiling the Power of Textual Semantics for Controllable Image Fusion
Dec 21, 2023Advanced image fusion methods are devoted to generating the fusion results by aggregating the complementary information conveyed by the source images. However, the difference in the source-specific manifestation of the imaged scene content makes it difficult to design a robust and controllable fusion process. We argue that this issue can be alleviated with the help of higher-level semantics, conveyed by the text modality, which should enable us to generate fused images for different purposes, such as visualisation and downstream tasks, in a controllable way. This is achieved by exploiting a vision-and-language model to build a coarse-to-fine association mechanism between the text and image signals. With the guidance of the association maps, an affine fusion unit is embedded in the transformer network to fuse the text and vision modalities at the feature level. As another ingredient of this work, we propose the use of textual attention to adapt image quality assessment to the fusion task. To facilitate the implementation of the proposed text-guided fusion paradigm, and its adoption by the wider research community, we release a text-annotated image fusion dataset IVT. Extensive experiments demonstrate that our approach (TextFusion) consistently outperforms traditional appearance-based fusion methods. Our code and dataset will be publicly available on the project homepage.