 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021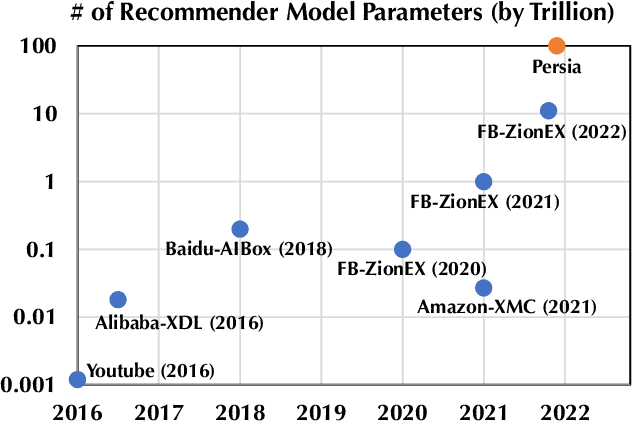
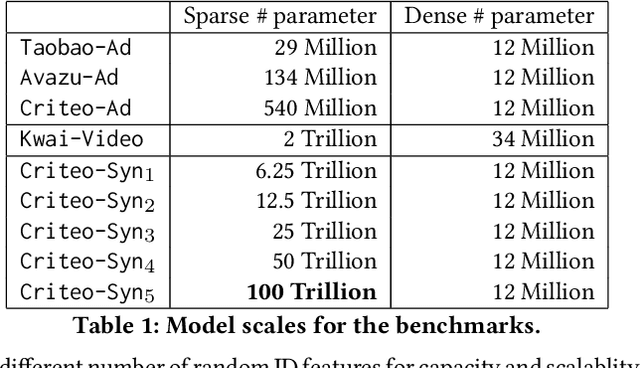
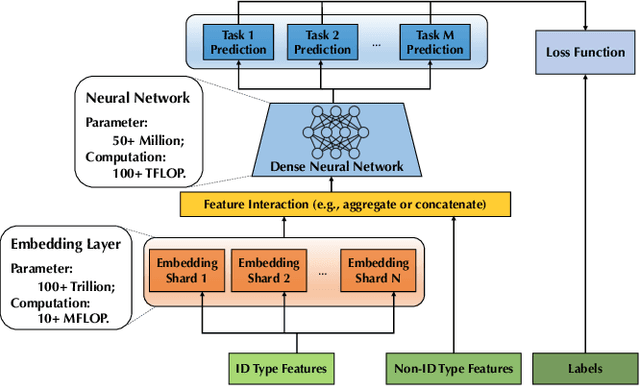
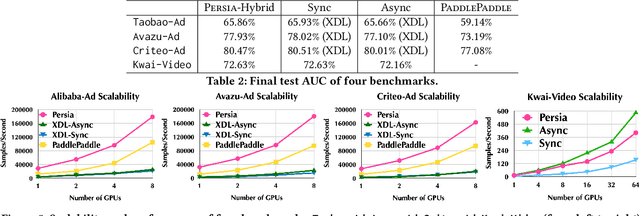
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
POSO: Personalized Cold Start Modules for Large-scale Recommender Systems
Aug 24, 2021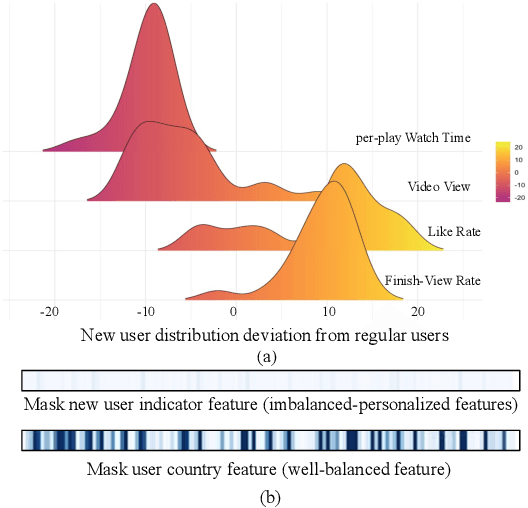
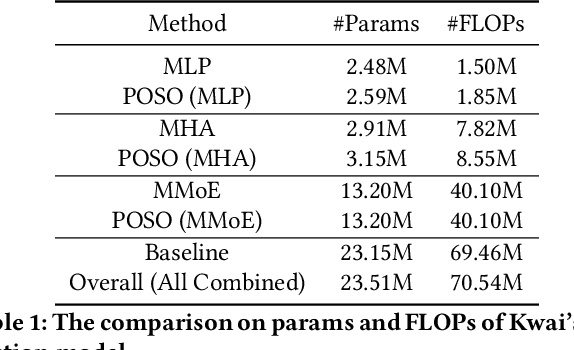
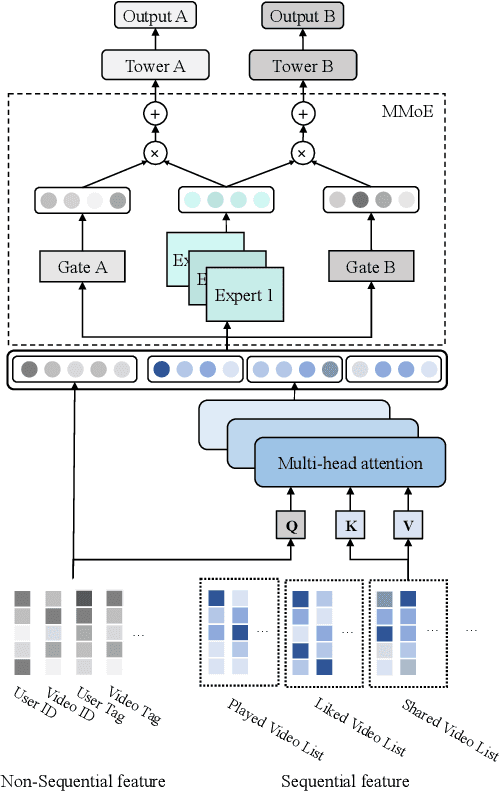
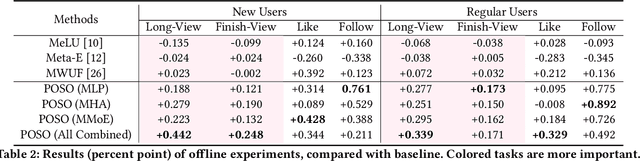
Recommendation for new users, also called user cold start, has been a well-recognized challenge for online recommender systems. Most existing methods view the crux as the lack of initial data. However, in this paper, we argue that there are neglected problems: 1) New users' behaviour follows much different distributions from regular users. 2) Although personalized features are involved, heavily imbalanced samples prevent the model from balancing new/regular user distributions, as if the personalized features are overwhelmed. We name the problem as the "submergence" of personalization. To tackle this problem, we propose a novel module: Personalized COld Start MOdules (POSO). Considering from a model architecture perspective, POSO personalizes existing modules by introducing multiple user-group-specialized sub-modules. Then, it fuses their outputs by personalized gates, resulting in comprehensive representations. In such way, POSO projects imbalanced features to even modules. POSO can be flexibly integrated into many existing modules and effectively improves their performance with negligible computational overheads. The proposed method shows remarkable advantage in industrial scenario. It has been deployed on the large-scale recommender system of Kwai, and improves new user Watch Time by a large margin (+7.75%). Moreover, POSO can be further generalized to regular users, inactive users and returning users (+2%-3% on Watch Time), as well as item cold start (+3.8% on Watch Time). Its effectiveness has also been verified on public dataset (MovieLens 20M). We believe such practical experience can be well generalized to other scenarios.
Using Query Expansion in Manifold Ranking for Query-Oriented Multi-Document Summarization
Jul 31, 2021



Manifold ranking has been successfully applied in query-oriented multi-document summarization. It not only makes use of the relationships among the sentences, but also the relationships between the given query and the sentences. However, the information of original query is often insufficient. So we present a query expansion method, which is combined in the manifold ranking to resolve this problem. Our method not only utilizes the information of the query term itself and the knowledge base WordNet to expand it by synonyms, but also uses the information of the document set itself to expand the query in various ways (mean expansion, variance expansion and TextRank expansion). Compared with the previous query expansion methods, our method combines multiple query expansion methods to better represent query information, and at the same time, it makes a useful attempt on manifold ranking. In addition, we use the degree of word overlap and the proximity between words to calculate the similarity between sentences. We performed experiments on the datasets of DUC 2006 and DUC2007, and the evaluation results show that the proposed query expansion method can significantly improve the system performance and make our system comparable to the state-of-the-art systems.
Joint Lifelong Topic Model and Manifold Ranking for Document Summarization
Jul 07, 2019



Due to the manifold ranking method has a significant effect on the ranking of unknown data based on known data by using a weighted network, many researchers use the manifold ranking method to solve the document summarization task. However, their models only consider the original features but ignore the semantic features of sentences when they construct the weighted networks for the manifold ranking method. To solve this problem, we proposed two improved models based on the manifold ranking method. One is combining the topic model and manifold ranking method (JTMMR) to solve the document summarization task. This model not only uses the original feature, but also uses the semantic feature to represent the document, which can improve the accuracy of the manifold ranking method. The other one is combining the lifelong topic model and manifold ranking method (JLTMMR). On the basis of the JTMMR, this model adds the constraint of knowledge to improve the quality of the topic. At the same time, we also add the constraint of the relationship between documents to dig out a better document semantic features. The JTMMR model can improve the effect of the manifold ranking method by using the better semantic feature. Experiments show that our models can achieve a better result than other baseline models for multi-document summarization task. At the same time, our models also have a good performance on the single document summarization task. After combining with a few basic surface features, our model significantly outperforms some model based on deep learning in recent years. After that, we also do an exploring work for lifelong machine learning by analyzing the effect of adding feedback. Experiments show that the effect of adding feedback to our model is significant.