 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRank: Unified List-wise Reranking via Confidence-Ordered Denoising
May 11, 2026List-wise reranking arranges a request-specific pool of candidate items into an ordered slate that maximizes user satisfaction. Existing generative rerankers fall into two paradigms: Autoregressive (AR) rerankers construct the slate left to right and capture inter-item dependencies in the exposure list, but they suffer from error propagation because early mistakes affect subsequent slots. Non-autoregressive (NAR) rerankers predict all slots in parallel and avoid error propagation, but they weaken inter-item interaction modeling under a slot independence assumption. This raises a central question: is there a unified architecture that combines the strengths of both paradigms and delivers stronger reranking performance? We answer this question with UniRank, a unified list-wise reranking framework whose inference time variants recover AR and NAR rerankers as special cases. UniRank integrates bidirectional slate modeling into an iterative denoising process and fills the most confident slot at each step. To instantiate this framework for reranking, we introduce the Task Grounded Diffusion Interface (TGD), which performs denoising at the item level and restricts prediction to the request-specific candidate pool. TGD aggregates each item's semantic tokens into a single item embedding and scores each slot directly against the candidate pool. Experiments on Amazon Books, MovieLens-1M, and an industrial short video dataset show that UniRank consistently outperforms state-of-the-art baselines. Online A/B tests on a real-world industrial platform further validate its effectiveness, yielding significant improvements of +0.159% in user average app-time and +1.016% in share-rate.
From Local Indices to Global Identifiers: Generative Reranking for Recommender Systems via Global Action Space
Apr 28, 2026In modern recommender systems, list-wise reranking serves as a critical phase within the multi-stage pipeline, finalizing the exposed item sequence and directly impacting user satisfaction by modeling complex intra-list item dependencies. Existing methods typically formulate this task as selecting indices from the local input list. However, this approach suffers from a semantically inconsistent action space: the same output neuron (logits) represents different items across different samples, preventing the model from establishing a stable, intrinsic understanding of the items. To address this, we propose GloRank (Global Action Space Ranker), a generative framework that shifts reranking from selecting local indices to generating global identifiers. Specifically, we represent items as sequences of discrete tokens and reformulate reranking as a token generation task. This design effectively decouples the scoring mechanism from the variable input order, ensuring that items are evaluated against a consistent global standard. We further enhance this with a two-stage optimization pipeline: a supervised pre-training phase to initialize the model with high-quality demonstrations, followed by a reinforcement learning-based post-training phase to directly maximize list-wise utility. Extensive experiments on two public benchmarks and a large-scale industrial dataset, coupled with online A/B tests, demonstrate that GloRank consistently outperforms state-of-the-art baselines and achieves superior robustness in cold-start scenarios.
FlashEvaluator: Expanding Search Space with Parallel Evaluation
Mar 03, 2026The Generator-Evaluator (G-E) framework, i.e., evaluating K sequences from a generator and selecting the top-ranked one according to evaluator scores, is a foundational paradigm in tasks such as Recommender Systems (RecSys) and Natural Language Processing (NLP). Traditional evaluators process sequences independently, suffering from two major limitations: (1) lack of explicit cross-sequence comparison, leading to suboptimal accuracy; (2) poor parallelization with linear complexity of O(K), resulting in inefficient resource utilization and negative impact on both throughput and latency. To address these challenges, we propose FlashEvaluator, which enables cross-sequence token information sharing and processes all sequences in a single forward pass. This yields sublinear computational complexity that improves the system's efficiency and supports direct inter-sequence comparisons that improve selection accuracy. The paper also provides theoretical proofs and extensive experiments on recommendation and NLP tasks, demonstrating clear advantages over conventional methods. Notably, FlashEvaluator has been deployed in online recommender system of Kuaishou, delivering substantial and sustained revenue gains in practice.
SOLAR: SVD-Optimized Lifelong Attention for Recommendation
Mar 03, 2026Attention mechanism remains the defining operator in Transformers since it provides expressive global credit assignment, yet its $O(N^2 d)$ time and memory cost in sequence length $N$ makes long-context modeling expensive and often forces truncation or other heuristics. Linear attention reduces complexity to $O(N d^2)$ by reordering computation through kernel feature maps, but this reformulation drops the softmax mechanism and shifts the attention score distribution. In recommender systems, low-rank structure in matrices is not a rare case, but rather the default inductive bias in its representation learning, particularly explicit in the user behavior sequence modeling. Leveraging this structure, we introduce SVD-Attention, which is theoretically lossless on low-rank matrices and preserves softmax while reducing attention complexity from $O(N^2 d)$ to $O(Ndr)$. With SVD-Attention, we propose SOLAR, SVD-Optimized Lifelong Attention for Recommendation, a sequence modeling framework that supports behavior sequences of ten-thousand scale and candidate sets of several thousand items in cascading process without any filtering. In Kuaishou's online recommendation scenario, SOLAR delivers a 0.68\% Video Views gain together with additional business metrics improvements.
Towards End-to-End Alignment of User Satisfaction via Questionnaire in Video Recommendation
Jan 28, 2026Short-video recommender systems typically optimize ranking models using dense user behavioral signals, such as clicks and watch time. However, these signals are only indirect proxies of user satisfaction and often suffer from noise and bias. Recently, explicit satisfaction feedback collected through questionnaires has emerged as a high-quality direct alignment supervision, but is extremely sparse and easily overwhelmed by abundant behavioral data, making it difficult to incorporate into online recommendation models. To address these challenges, we propose a novel framework which is towards End-to-End Alignment of user Satisfaction via Questionaire, named EASQ, to enable real-time alignment of ranking models with true user satisfaction. Specifically, we first construct an independent parameter pathway for sparse questionnaire signals by combining a multi-task architecture and a lightweight LoRA module. The multi-task design separates sparse satisfaction supervision from dense behavioral signals, preventing the former from being overwhelmed. The LoRA module pre-inject these preferences in a parameter-isolated manner, ensuring stability in the backbone while optimizing user satisfaction. Furthermore, we employ a DPO-based optimization objective tailored for online learning, which aligns the main model outputs with sparse satisfaction signals in real time. This design enables end-to-end online learning, allowing the model to continuously adapt to new questionnaire feedback while maintaining the stability and effectiveness of the backbone. Extensive offline experiments and large-scale online A/B tests demonstrate that EASQ consistently improves user satisfaction metrics across multiple scenarios. EASQ has been successfully deployed in a production short-video recommendation system, delivering significant and stable business gains.
S$^2$GR: Stepwise Semantic-Guided Reasoning in Latent Space for Generative Recommendation
Jan 26, 2026Generative Recommendation (GR) has emerged as a transformative paradigm with its end-to-end generation advantages. However, existing GR methods primarily focus on direct Semantic ID (SID) generation from interaction sequences, failing to activate deeper reasoning capabilities analogous to those in large language models and thus limiting performance potential. We identify two critical limitations in current reasoning-enhanced GR approaches: (1) Strict sequential separation between reasoning and generation steps creates imbalanced computational focus across hierarchical SID codes, degrading quality for SID codes; (2) Generated reasoning vectors lack interpretable semantics, while reasoning paths suffer from unverifiable supervision. In this paper, we propose stepwise semantic-guided reasoning in latent space (S$^2$GR), a novel reasoning enhanced GR framework. First, we establish a robust semantic foundation via codebook optimization, integrating item co-occurrence relationship to capture behavioral patterns, and load balancing and uniformity objectives that maximize codebook utilization while reinforcing coarse-to-fine semantic hierarchies. Our core innovation introduces the stepwise reasoning mechanism inserting thinking tokens before each SID generation step, where each token explicitly represents coarse-grained semantics supervised via contrastive learning against ground-truth codebook cluster distributions ensuring physically grounded reasoning paths and balanced computational focus across all SID codes. Extensive experiments demonstrate the superiority of S$^2$GR, and online A/B test confirms efficacy on large-scale industrial short video platform.
PushGen: Push Notifications Generation with LLM
Dec 16, 2025
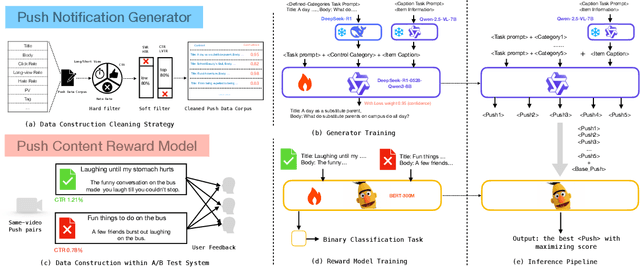

We present PushGen, an automated framework for generating high-quality push notifications comparable to human-crafted content. With the rise of generative models, there is growing interest in leveraging LLMs for push content generation. Although LLMs make content generation straightforward and cost-effective, maintaining stylistic control and reliable quality assessment remains challenging, as both directly impact user engagement. To address these issues, PushGen combines two key components: (1) a controllable category prompt technique to guide LLM outputs toward desired styles, and (2) a reward model that ranks and selects generated candidates. Extensive offline and online experiments demonstrate its effectiveness, which has been deployed in large-scale industrial applications, serving hundreds of millions of users daily.
xMTF: A Formula-Free Model for Reinforcement-Learning-Based Multi-Task Fusion in Recommender Systems
Apr 08, 2025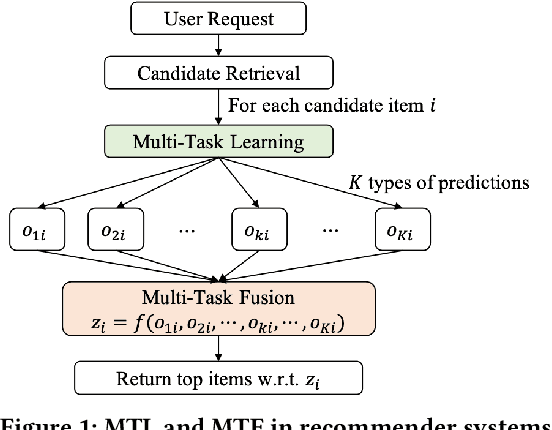

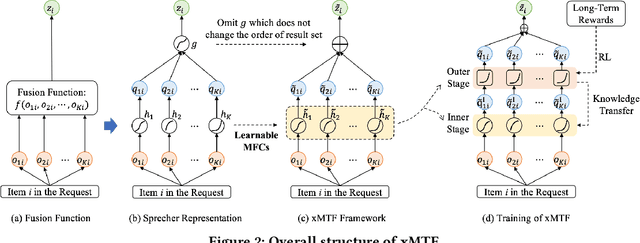
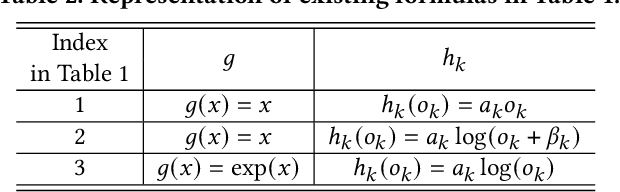
Recommender systems need to optimize various types of user feedback, e.g., clicks, likes, and shares. A typical recommender system handling multiple types of feedback has two components: a multi-task learning (MTL) module, predicting feedback such as click-through rate and like rate; and a multi-task fusion (MTF) module, integrating these predictions into a single score for item ranking. MTF is essential for ensuring user satisfaction, as it directly influences recommendation outcomes. Recently, reinforcement learning (RL) has been applied to MTF tasks to improve long-term user satisfaction. However, existing RL-based MTF methods are formula-based methods, which only adjust limited coefficients within pre-defined formulas. The pre-defined formulas restrict the RL search space and become a bottleneck for MTF. To overcome this, we propose a formula-free MTF framework. We demonstrate that any suitable fusion function can be expressed as a composition of single-variable monotonic functions, as per the Sprecher Representation Theorem. Leveraging this, we introduce a novel learnable monotonic fusion cell (MFC) to replace pre-defined formulas. We call this new MFC-based model eXtreme MTF (xMTF). Furthermore, we employ a two-stage hybrid (TSH) learning strategy to train xMTF effectively. By expanding the MTF search space, xMTF outperforms existing methods in extensive offline and online experiments.
Unleashing the Potential of Two-Tower Models: Diffusion-Based Cross-Interaction for Large-Scale Matching
Feb 28, 2025Two-tower models are widely adopted in the industrial-scale matching stage across a broad range of application domains, such as content recommendations, advertisement systems, and search engines. This model efficiently handles large-scale candidate item screening by separating user and item representations. However, the decoupling network also leads to a neglect of potential information interaction between the user and item representations. Current state-of-the-art (SOTA) approaches include adding a shallow fully connected layer(i.e., COLD), which is limited by performance and can only be used in the ranking stage. For performance considerations, another approach attempts to capture historical positive interaction information from the other tower by regarding them as the input features(i.e., DAT). Later research showed that the gains achieved by this method are still limited because of lacking the guidance on the next user intent. To address the aforementioned challenges, we propose a "cross-interaction decoupling architecture" within our matching paradigm. This user-tower architecture leverages a diffusion module to reconstruct the next positive intention representation and employs a mixed-attention module to facilitate comprehensive cross-interaction. During the next positive intention generation, we further enhance the accuracy of its reconstruction by explicitly extracting the temporal drift within user behavior sequences. Experiments on two real-world datasets and one industrial dataset demonstrate that our method outperforms the SOTA two-tower models significantly, and our diffusion approach outperforms other generative models in reconstructing item representations.
Creator-Side Recommender System: Challenges, Designs, and Applications
Feb 25, 2025Users and creators are two crucial components of recommender systems. Typical recommender systems focus on the user side, providing the most suitable items based on each user's request. In such scenarios, a few items receive a majority of exposures, while many items receive very few. This imbalance leads to poorer experiences and decreased activity among the creators receiving less feedback, harming the recommender system in the long term. To this end, we develop a creator-side recommender system, called DualRec, to answer the following question: how to find the most suitable users for each item to enhance the creators' experience? We show that typical user-side recommendation algorithms, such as retrieval and ranking algorithms, can be adapted into the creator-side versions with just a few modifications. This greatly simplifies algorithm design in DualRec. Moreover, we discuss a unique challenge in DualRec: the user availability issue, which is not present in user-side recommender systems. To tackle this issue, we incorporate a user availability calculation (UAC) module to effectively enhance DualRec's performance. DualRec has already been implemented in Kwai, a short video recommendation system with over 100 millions user and over 10 million creators, significantly improving the experience for creators.