 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting False Alarms from Unseen: Adapting Graph Anomaly Detectors at Test Time
Nov 10, 2025Graph anomaly detection (GAD), which aims to detect outliers in graph-structured data, has received increasing research attention recently. However, existing GAD methods assume identical training and testing distributions, which is rarely valid in practice. In real-world scenarios, unseen but normal samples may emerge during deployment, leading to a normality shift that degrades the performance of GAD models trained on the original data. Through empirical analysis, we reveal that the degradation arises from (1) semantic confusion, where unseen normal samples are misinterpreted as anomalies due to their novel patterns, and (2) aggregation contamination, where the representations of seen normal nodes are distorted by unseen normals through message aggregation. While retraining or fine-tuning GAD models could be a potential solution to the above challenges, the high cost of model retraining and the difficulty of obtaining labeled data often render this approach impractical in real-world applications. To bridge the gap, we proposed a lightweight and plug-and-play Test-time adaptation framework for correcting Unseen Normal pattErns (TUNE) in GAD. To address semantic confusion, a graph aligner is employed to align the shifted data to the original one at the graph attribute level. Moreover, we utilize the minimization of representation-level shift as a supervision signal to train the aligner, which leverages the estimated aggregation contamination as a key indicator of normality shift. Extensive experiments on 10 real-world datasets demonstrate that TUNE significantly enhances the generalizability of pre-trained GAD models to both synthetic and real unseen normal patterns.
Reasoning Segmentation for Images and Videos: A Survey
May 24, 2025Reasoning Segmentation (RS) aims to delineate objects based on implicit text queries, the interpretation of which requires reasoning and knowledge integration. Unlike the traditional formulation of segmentation problems that relies on fixed semantic categories or explicit prompting, RS bridges the gap between visual perception and human-like reasoning capabilities, facilitating more intuitive human-AI interaction through natural language. Our work presents the first comprehensive survey of RS for image and video processing, examining 26 state-of-the-art methods together with a review of the corresponding evaluation metrics, as well as 29 datasets and benchmarks. We also explore existing applications of RS across diverse domains and identify their potential extensions. Finally, we identify current research gaps and highlight promising future directions.
Unleashing the Potential of Two-Tower Models: Diffusion-Based Cross-Interaction for Large-Scale Matching
Feb 28, 2025Two-tower models are widely adopted in the industrial-scale matching stage across a broad range of application domains, such as content recommendations, advertisement systems, and search engines. This model efficiently handles large-scale candidate item screening by separating user and item representations. However, the decoupling network also leads to a neglect of potential information interaction between the user and item representations. Current state-of-the-art (SOTA) approaches include adding a shallow fully connected layer(i.e., COLD), which is limited by performance and can only be used in the ranking stage. For performance considerations, another approach attempts to capture historical positive interaction information from the other tower by regarding them as the input features(i.e., DAT). Later research showed that the gains achieved by this method are still limited because of lacking the guidance on the next user intent. To address the aforementioned challenges, we propose a "cross-interaction decoupling architecture" within our matching paradigm. This user-tower architecture leverages a diffusion module to reconstruct the next positive intention representation and employs a mixed-attention module to facilitate comprehensive cross-interaction. During the next positive intention generation, we further enhance the accuracy of its reconstruction by explicitly extracting the temporal drift within user behavior sequences. Experiments on two real-world datasets and one industrial dataset demonstrate that our method outperforms the SOTA two-tower models significantly, and our diffusion approach outperforms other generative models in reconstructing item representations.
Butterfly: Multiple Reference Frames Feature Propagation Mechanism for Neural Video Compression
Mar 06, 2023



Using more reference frames can significantly improve the compression efficiency in neural video compression. However, in low-latency scenarios, most existing neural video compression frameworks usually use the previous one frame as reference. Or a few frameworks which use the previous multiple frames as reference only adopt a simple multi-reference frames propagation mechanism. In this paper, we present a more reasonable multi-reference frames propagation mechanism for neural video compression, called butterfly multi-reference frame propagation mechanism (Butterfly), which allows a more effective feature fusion of multi-reference frames. By this, we can generate more accurate temporal context conditional prior for Contextual Coding Module. Besides, when the number of decoded frames does not meet the required number of reference frames, we duplicate the nearest reference frame to achieve the requirement, which is better than duplicating the furthest one. Experiment results show that our method can significantly outperform the previous state-of-the-art (SOTA), and our neural codec can achieve -7.6% bitrate save on HEVC Class D dataset when compares with our base single-reference frame model with the same compression configuration.
Spatial-Temporal Deep Intention Destination Networks for Online Travel Planning
Aug 09, 2021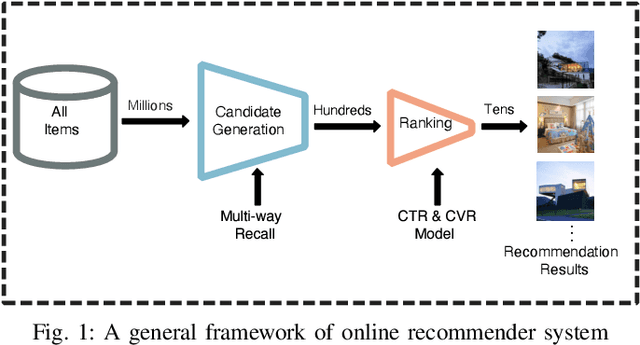
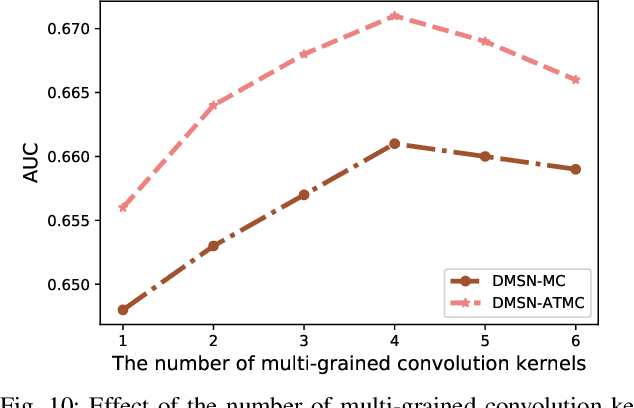
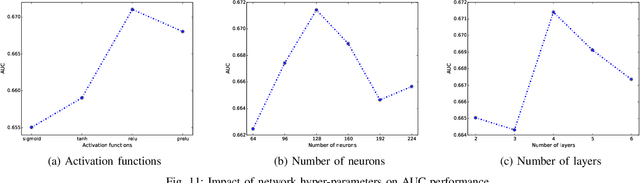
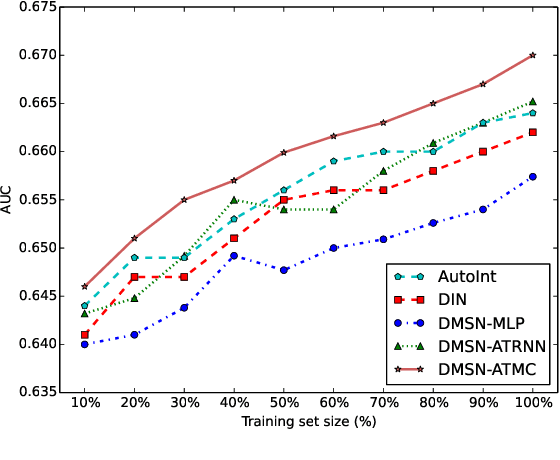
Nowadays, artificial neural networks are widely used for users' online travel planning. Personalized travel planning has many real applications and is affected by various factors, such as transportation type, intention destination estimation, budget limit and crowdness prediction. Among those factors, users' intention destination prediction is an essential task in online travel platforms. The reason is that, the user may be interested in the travel plan only when the plan matches his real intention destination. Therefore, in this paper, we focus on predicting users' intention destinations in online travel platforms. In detail, we act as online travel platforms (such as Fliggy and Airbnb) to recommend travel plans for users, and the plan consists of various vacation items including hotel package, scenic packages and so on. Predicting the actual intention destination in travel planning is challenging. Firstly, users' intention destination is highly related to their travel status (e.g., planning for a trip or finishing a trip). Secondly, users' actions (e.g. clicking, searching) over different product types (e.g. train tickets, visa application) have different indications in destination prediction. Thirdly, users may mostly visit the travel platforms just before public holidays, and thus user behaviors in online travel platforms are more sparse, low-frequency and long-period. Therefore, we propose a Deep Multi-Sequences fused neural Networks (DMSN) to predict intention destinations from fused multi-behavior sequences. Real datasets are used to evaluate the performance of our proposed DMSN models. Experimental results indicate that the proposed DMSN models can achieve high intention destination prediction accuracy.
Anomaly Detection in Dynamic Graphs via Transformer
Jun 18, 2021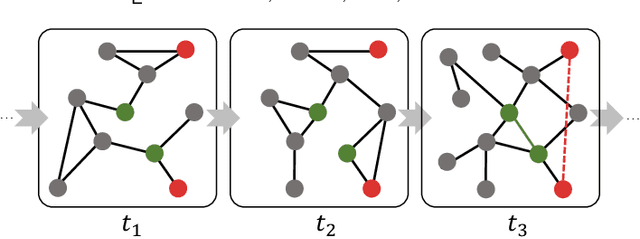
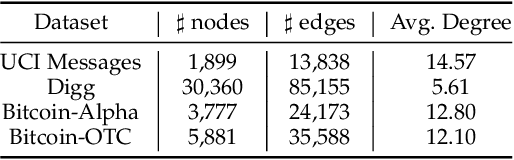
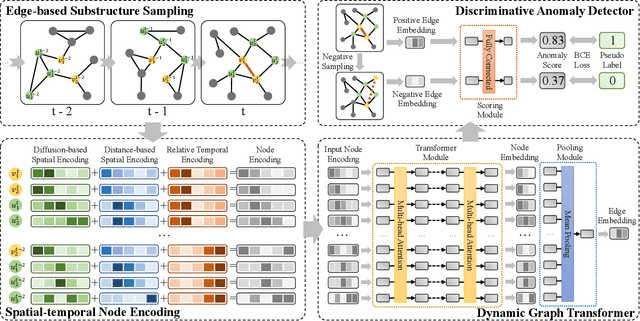

Detecting anomalies for dynamic graphs has drawn increasing attention due to their wide applications in social networks, e-commerce, and cybersecurity. The recent deep learning-based approaches have shown promising results over shallow methods. However, they fail to address two core challenges of anomaly detection in dynamic graphs: the lack of informative encoding for unattributed nodes and the difficulty of learning discriminate knowledge from coupled spatial-temporal dynamic graphs. To overcome these challenges, in this paper, we present a novel Transformer-based Anomaly Detection framework for DYnamic graph (TADDY). Our framework constructs a comprehensive node encoding strategy to better represent each node's structural and temporal roles in an evolving graphs stream. Meanwhile, TADDY captures informative representation from dynamic graphs with coupled spatial-temporal patterns via a dynamic graph transformer model. The extensive experimental results demonstrate that our proposed TADDY framework outperforms the state-of-the-art methods by a large margin on four real-world datasets.
MoNet: Moments Embedding Network
Mar 29, 2018



Bilinear pooling has been recently proposed as a feature encoding layer, which can be used after the convolutional layers of a deep network, to improve performance in multiple vision tasks. Different from conventional global average pooling or fully connected layer, bilinear pooling gathers 2nd order information in a translation invariant fashion. However, a serious drawback of this family of pooling layers is their dimensionality explosion. Approximate pooling methods with compact properties have been explored towards resolving this weakness. Additionally, recent results have shown that significant performance gains can be achieved by adding 1st order information and applying matrix normalization to regularize unstable higher order information. However, combining compact pooling with matrix normalization and other order information has not been explored until now. In this paper, we unify bilinear pooling and the global Gaussian embedding layers through the empirical moment matrix. In addition, we propose a novel sub-matrix square-root layer, which can be used to normalize the output of the convolution layer directly and mitigate the dimensionality problem with off-the-shelf compact pooling methods. Our experiments on three widely used fine-grained classification datasets illustrate that our proposed architecture, MoNet, can achieve similar or better performance than with the state-of-art G2DeNet. Furthermore, when combined with compact pooling technique, MoNet obtains comparable performance with encoded features with 96% less dimensions.