 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Data to Insights: A Comprehensive Survey on Advanced Applications in Thyroid Cancer Research
Jan 08, 2024


Thyroid cancer, the most prevalent endocrine cancer, has gained significant global attention due to its impact on public health. Extensive research efforts have been dedicated to leveraging artificial intelligence (AI) methods for the early detection of this disease, aiming to reduce its morbidity rates. However, a comprehensive understanding of the structured organization of research applications in this particular field remains elusive. To address this knowledge gap, we conducted a systematic review and developed a comprehensive taxonomy of machine learning-based applications in thyroid cancer pathogenesis, diagnosis, and prognosis. Our primary objective was to facilitate the research community's ability to stay abreast of technological advancements and potentially lead the emerging trends in this field. This survey presents a coherent literature review framework for interpreting the advanced techniques used in thyroid cancer research. A total of 758 related studies were identified and scrutinized. To the best of our knowledge, this is the first review that provides an in-depth analysis of the various aspects of AI applications employed in the context of thyroid cancer. Furthermore, we highlight key challenges encountered in this domain and propose future research opportunities for those interested in studying the latest trends or exploring less-investigated aspects of thyroid cancer research. By presenting this comprehensive review and taxonomy, we contribute to the existing knowledge in the field, while providing valuable insights for researchers, clinicians, and stakeholders in advancing the understanding and management of this disease.
Finding the Missing-half: Graph Complementary Learning for Homophily-prone and Heterophily-prone Graphs
Jun 13, 2023



Real-world graphs generally have only one kind of tendency in their connections. These connections are either homophily-prone or heterophily-prone. While graphs with homophily-prone edges tend to connect nodes with the same class (i.e., intra-class nodes), heterophily-prone edges tend to build relationships between nodes with different classes (i.e., inter-class nodes). Existing GNNs only take the original graph during training. The problem with this approach is that it forgets to take into consideration the ``missing-half" structural information, that is, heterophily-prone topology for homophily-prone graphs and homophily-prone topology for heterophily-prone graphs. In our paper, we introduce Graph cOmplementAry Learning, namely GOAL, which consists of two components: graph complementation and complemented graph convolution. The first component finds the missing-half structural information for a given graph to complement it. The complemented graph has two sets of graphs including both homophily- and heterophily-prone topology. In the latter component, to handle complemented graphs, we design a new graph convolution from the perspective of optimisation. The experiment results show that GOAL consistently outperforms all baselines in eight real-world datasets.
Beyond Smoothing: Unsupervised Graph Representation Learning with Edge Heterophily Discriminating
Nov 25, 2022
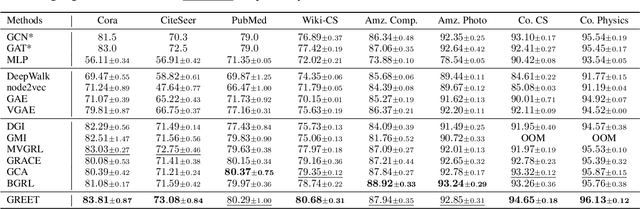
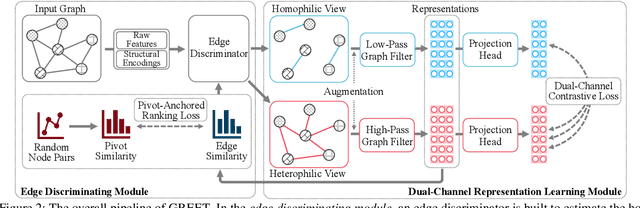
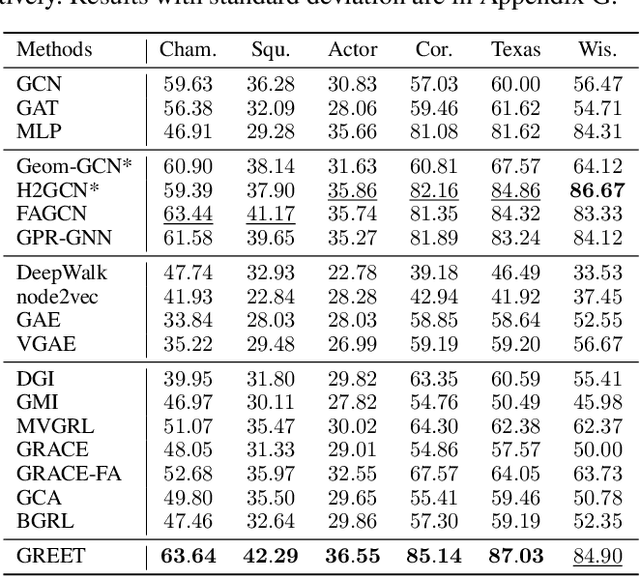
Unsupervised graph representation learning (UGRL) has drawn increasing research attention and achieved promising results in several graph analytic tasks. Relying on the homophily assumption, existing UGRL methods tend to smooth the learned node representations along all edges, ignoring the existence of heterophilic edges that connect nodes with distinct attributes. As a result, current methods are hard to generalize to heterophilic graphs where dissimilar nodes are widely connected, and also vulnerable to adversarial attacks. To address this issue, we propose a novel unsupervised Graph Representation learning method with Edge hEterophily discriminaTing (GREET) which learns representations by discriminating and leveraging homophilic edges and heterophilic edges. To distinguish two types of edges, we build an edge discriminator that infers edge homophily/heterophily from feature and structure information. We train the edge discriminator in an unsupervised way through minimizing the crafted pivot-anchored ranking loss, with randomly sampled node pairs acting as pivots. Node representations are learned through contrasting the dual-channel encodings obtained from the discriminated homophilic and heterophilic edges. With an effective interplaying scheme, edge discriminating and representation learning can mutually boost each other during the training phase. We conducted extensive experiments on 14 benchmark datasets and multiple learning scenarios to demonstrate the superiority of GREET.
Unifying Graph Contrastive Learning with Flexible Contextual Scopes
Oct 17, 2022

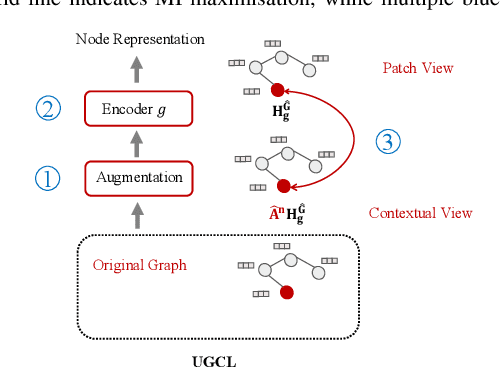
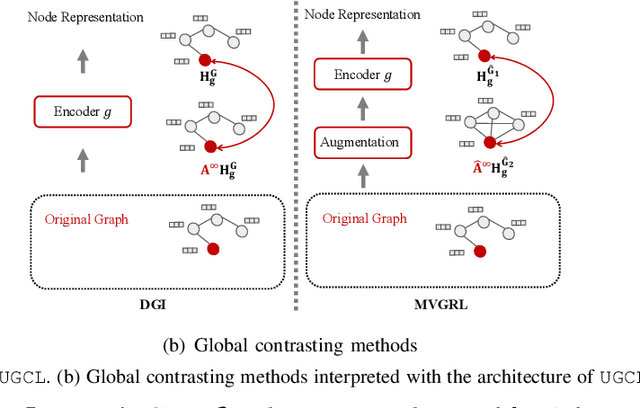
Graph contrastive learning (GCL) has recently emerged as an effective learning paradigm to alleviate the reliance on labelling information for graph representation learning. The core of GCL is to maximise the mutual information between the representation of a node and its contextual representation (i.e., the corresponding instance with similar semantic information) summarised from the contextual scope (e.g., the whole graph or 1-hop neighbourhood). This scheme distils valuable self-supervision signals for GCL training. However, existing GCL methods still suffer from limitations, such as the incapacity or inconvenience in choosing a suitable contextual scope for different datasets and building biased contrastiveness. To address aforementioned problems, we present a simple self-supervised learning method termed Unifying Graph Contrastive Learning with Flexible Contextual Scopes (UGCL for short). Our algorithm builds flexible contextual representations with tunable contextual scopes by controlling the power of an adjacency matrix. Additionally, our method ensures contrastiveness is built within connected components to reduce the bias of contextual representations. Based on representations from both local and contextual scopes, UGCL optimises a very simple contrastive loss function for graph representation learning. Essentially, the architecture of UGCL can be considered as a general framework to unify existing GCL methods. We have conducted intensive experiments and achieved new state-of-the-art performance in six out of eight benchmark datasets compared with self-supervised graph representation learning baselines. Our code has been open-sourced.
Service resource allocation problem in the IoT driven personalized healthcare information platform
Apr 05, 2022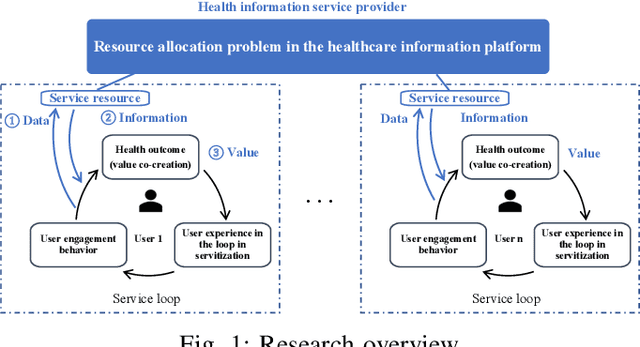
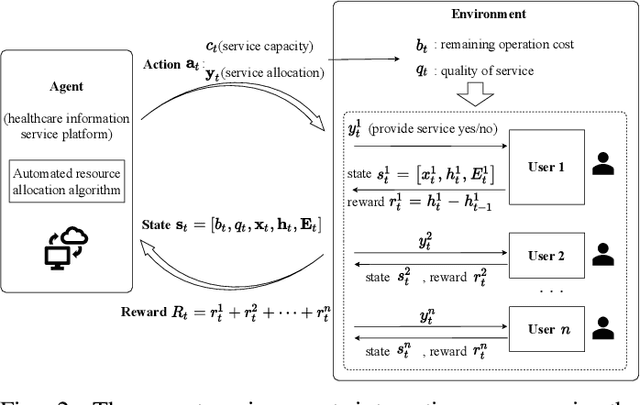
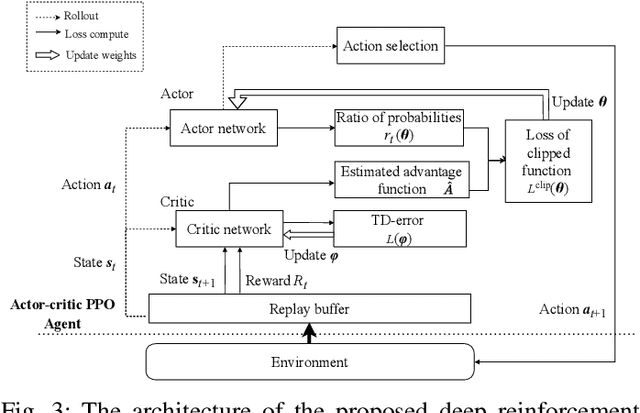
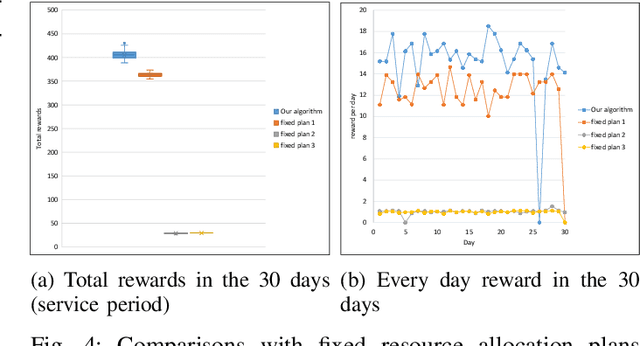
With real-time monitoring of the personalized healthcare condition, the IoT wearables collect the health data and transfer it to the healthcare information platform. The platform processes the data into healthcare recommendations and then delivers them to the users. The IoT structures in the personalized healthcare information service allows the users to engage in the loop in servitization more convenient in the COVID-19 pandemic. However, the uncertainty of the engagement behavior among the individual may result in inefficient of the service resource allocation. This paper seeks an efficient way to allocate the service resource by controlling the service capacity and pushing the service to the active users automatically. In this study, we propose a deep reinforcement learning method to solve the service resource allocation problem based on the proximal policy optimization (PPO) algorithm. Experimental results using the real world (open source) sport dataset reveal that our proposed proximal policy optimization adapts well to the users' changing behavior and with improved performance over fixed service resource policies.
Dynamic physical activity recommendation on personalised mobile health information service: A deep reinforcement learning approach
Apr 03, 2022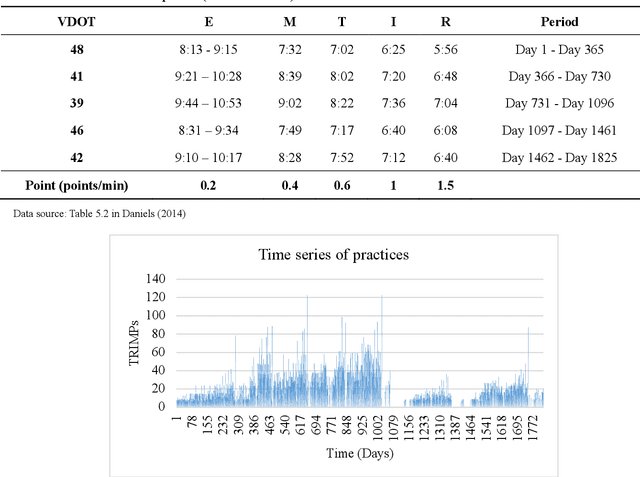
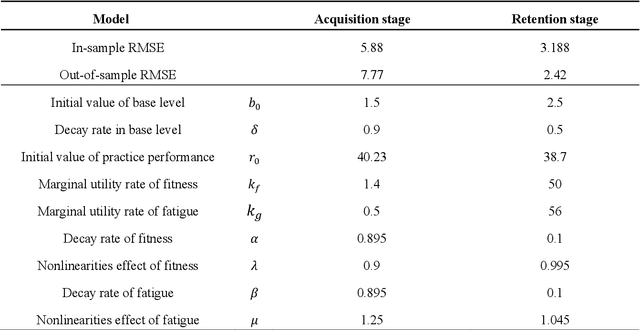


Mobile health (mHealth) information service makes healthcare management easier for users, who want to increase physical activity and improve health. However, the differences in activity preference among the individual, adherence problems, and uncertainty of future health outcomes may reduce the effect of the mHealth information service. The current health service system usually provides recommendations based on fixed exercise plans that do not satisfy the user specific needs. This paper seeks an efficient way to make physical activity recommendation decisions on physical activity promotion in personalised mHealth information service by establishing data-driven model. In this study, we propose a real-time interaction model to select the optimal exercise plan for the individual considering the time-varying characteristics in maximising the long-term health utility of the user. We construct a framework for mHealth information service system comprising a personalised AI module, which is based on the scientific knowledge about physical activity to evaluate the individual exercise performance, which may increase the awareness of the mHealth artificial intelligence system. The proposed deep reinforcement learning (DRL) methodology combining two classes of approaches to improve the learning capability for the mHealth information service system. A deep learning method is introduced to construct the hybrid neural network combing long-short term memory (LSTM) network and deep neural network (DNN) techniques to infer the individual exercise behavior from the time series data. A reinforcement learning method is applied based on the asynchronous advantage actor-critic algorithm to find the optimal policy through exploration and exploitation.
Anomaly Detection in Dynamic Graphs via Transformer
Jun 18, 2021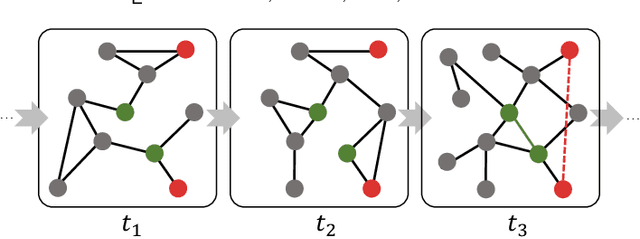
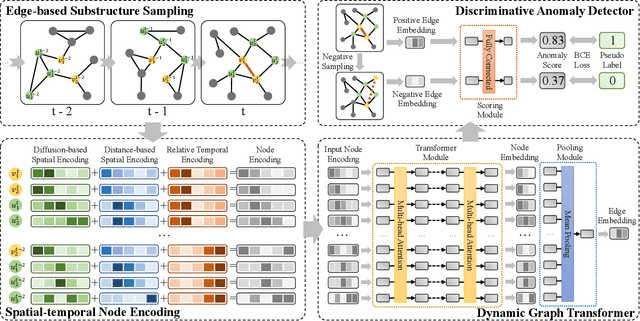

Detecting anomalies for dynamic graphs has drawn increasing attention due to their wide applications in social networks, e-commerce, and cybersecurity. The recent deep learning-based approaches have shown promising results over shallow methods. However, they fail to address two core challenges of anomaly detection in dynamic graphs: the lack of informative encoding for unattributed nodes and the difficulty of learning discriminate knowledge from coupled spatial-temporal dynamic graphs. To overcome these challenges, in this paper, we present a novel Transformer-based Anomaly Detection framework for DYnamic graph (TADDY). Our framework constructs a comprehensive node encoding strategy to better represent each node's structural and temporal roles in an evolving graphs stream. Meanwhile, TADDY captures informative representation from dynamic graphs with coupled spatial-temporal patterns via a dynamic graph transformer model. The extensive experimental results demonstrate that our proposed TADDY framework outperforms the state-of-the-art methods by a large margin on four real-world datasets.
Online Semi-Supervised Concept Drift Detection with Density Estimation
Sep 25, 2019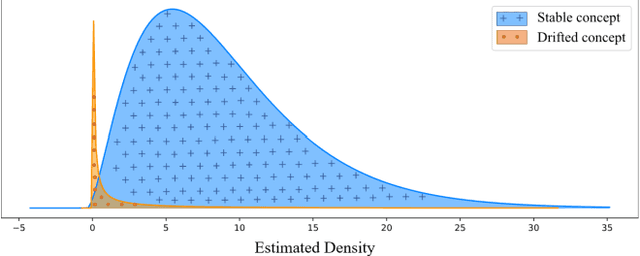
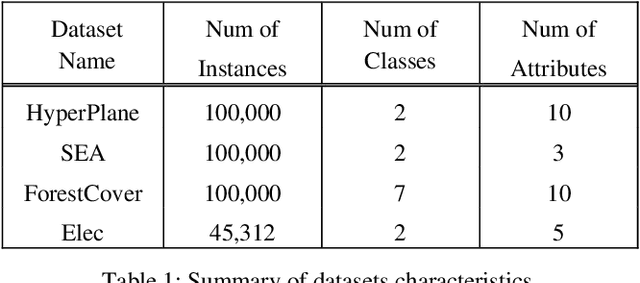
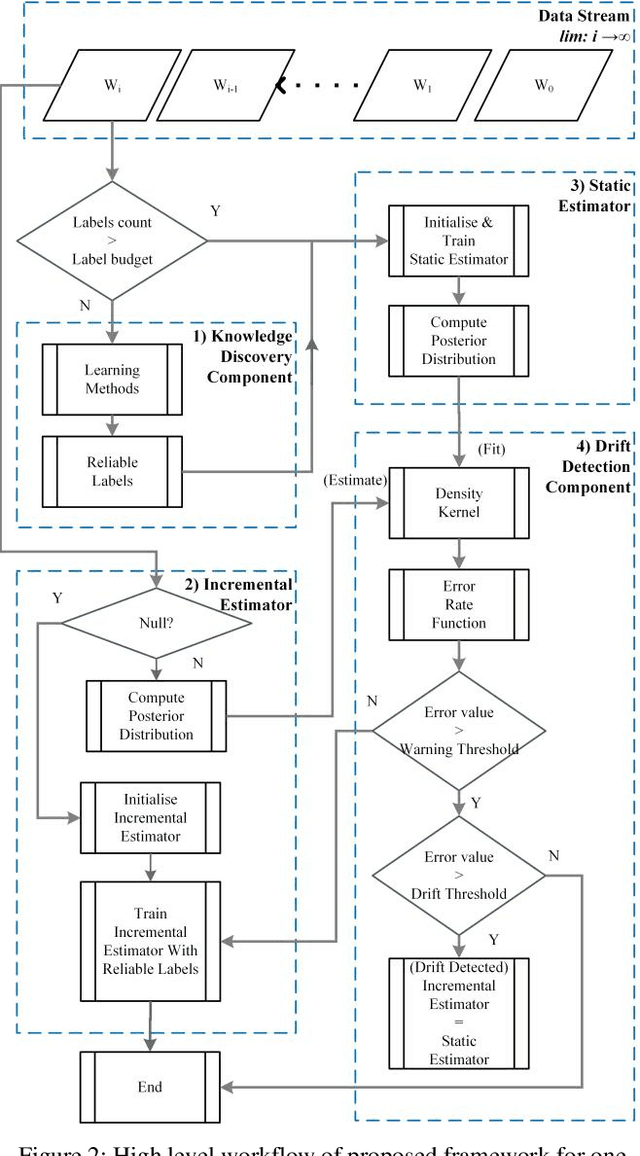

Concept drift is formally defined as the change in joint distribution of a set of input variables X and a target variable y. The two types of drift that are extensively studied are real drift and virtual drift where the former is the change in posterior probabilities p(y|X) while the latter is the change in distribution of X without affecting the posterior probabilities. Many approaches on concept drift detection either assume full availability of data labels, y or handle only the virtual drift. In a streaming environment, the assumption of full availability of data labels, y is questioned. On the other hand, approaches that deal with virtual drift failed to address real drift. Rather than improving the state-of-the-art methods, this paper presents a semi-supervised framework to deal with the challenges above. The objective of the proposed framework is to learn from streaming environment with limited data labels, y and detect real drift concurrently. This paper proposes a novel concept drift detection method utilizing the densities of posterior probabilities in partially labeled streaming environments. Experimental results on both synthetic and realworld datasets show that our proposed semi-supervised framework enables the detection of concept drift in such environment while achieving comparable prediction performance to the state-of-the-art methods.
Nearest-Neighbour-Induced Isolation Similarity and its Impact on Density-Based Clustering
Jun 30, 2019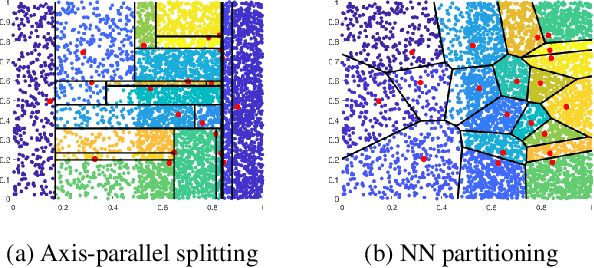
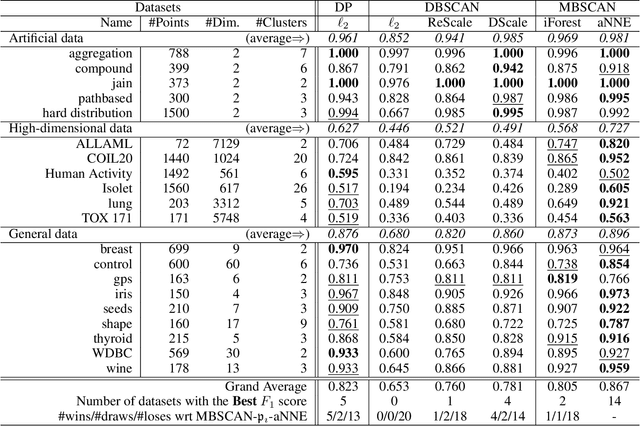
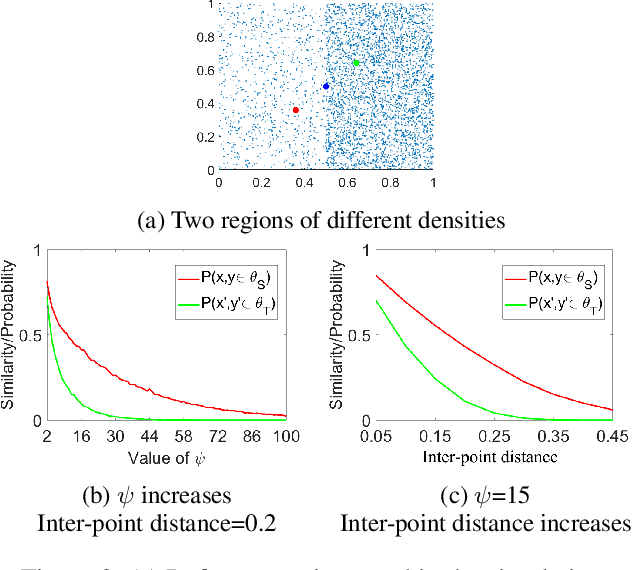

A recent proposal of data dependent similarity called Isolation Kernel/Similarity has enabled SVM to produce better classification accuracy. We identify shortcomings of using a tree method to implement Isolation Similarity; and propose a nearest neighbour method instead. We formally prove the characteristic of Isolation Similarity with the use of the proposed method. The impact of Isolation Similarity on density-based clustering is studied here. We show for the first time that the clustering performance of the classic density-based clustering algorithm DBSCAN can be significantly uplifted to surpass that of the recent density-peak clustering algorithm DP. This is achieved by simply replacing the distance measure with the proposed nearest-neighbour-induced Isolation Similarity in DBSCAN, leaving the rest of the procedure unchanged. A new type of clusters called mass-connected clusters is formally defined. We show that DBSCAN, which detects density-connected clusters, becomes one which detects mass-connected clusters, when the distance measure is replaced with the proposed similarity. We also provide the condition under which mass-connected clusters can be detected, while density-connected clusters cannot.