 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMA: Complementary Masking and Hierarchical Dynamic Multi-Window Self-Attention in a Unified Pre-training Framework
Nov 08, 2025Masked Autoencoders (MAE) achieve self-supervised learning of image representations by randomly removing a portion of visual tokens and reconstructing the original image as a pretext task, thereby significantly enhancing pretraining efficiency and yielding excellent adaptability across downstream tasks. However, MAE and other MAE-style paradigms that adopt random masking generally require more pre-training epochs to maintain adaptability. Meanwhile, ViT in MAE suffers from inefficient parameter use due to fixed spatial resolution across layers. To overcome these limitations, we propose the Complementary Masked Autoencoders (CoMA), which employ a complementary masking strategy to ensure uniform sampling across all pixels, thereby improving effective learning of all features and enhancing the model's adaptability. Furthermore, we introduce DyViT, a hierarchical vision transformer that employs a Dynamic Multi-Window Self-Attention (DM-MSA), significantly reducing the parameters and FLOPs while improving fine-grained feature learning. Pre-trained on ImageNet-1K with CoMA, DyViT matches the downstream performance of MAE using only 12% of the pre-training epochs, demonstrating more effective learning. It also attains a 10% reduction in pre-training time per epoch, further underscoring its superior pre-training efficiency.
CFFormer: Cross CNN-Transformer Channel Attention and Spatial Feature Fusion for Improved Segmentation of Low Quality Medical Images
Jan 07, 2025Hybrid CNN-Transformer models are designed to combine the advantages of Convolutional Neural Networks (CNNs) and Transformers to efficiently model both local information and long-range dependencies. However, most research tends to focus on integrating the spatial features of CNNs and Transformers, while overlooking the critical importance of channel features. This is particularly significant for model performance in low-quality medical image segmentation. Effective channel feature extraction can significantly enhance the model's ability to capture contextual information and improve its representation capabilities. To address this issue, we propose a hybrid CNN-Transformer model, CFFormer, and introduce two modules: the Cross Feature Channel Attention (CFCA) module and the X-Spatial Feature Fusion (XFF) module. The model incorporates dual encoders, with the CNN encoder focusing on capturing local features and the Transformer encoder modeling global features. The CFCA module filters and facilitates interactions between the channel features from the two encoders, while the XFF module effectively reduces the significant semantic information differences in spatial features, enabling a smooth and cohesive spatial feature fusion. We evaluate our model across eight datasets covering five modalities to test its generalization capability. Experimental results demonstrate that our model outperforms current state-of-the-art (SOTA) methods, with particularly superior performance on datasets characterized by blurry boundaries and low contrast.
Label Distribution Learning using the Squared Neural Family on the Probability Simplex
Dec 10, 2024
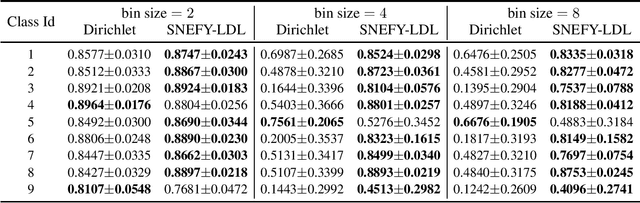
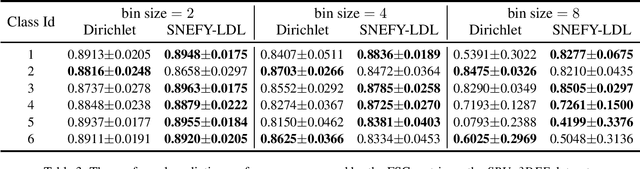
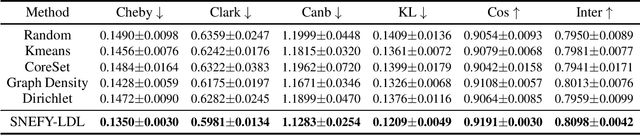
Label distribution learning (LDL) provides a framework wherein a distribution over categories rather than a single category is predicted, with the aim of addressing ambiguity in labeled data. Existing research on LDL mainly focuses on the task of point estimation, i.e., pinpointing an optimal distribution in the probability simplex conditioned on the input sample. In this paper, we estimate a probability distribution of all possible label distributions over the simplex, by unleashing the expressive power of the recently introduced Squared Neural Family (SNEFY). With the modeled distribution, label distribution prediction can be achieved by performing the expectation operation to estimate the mean of the distribution of label distributions. Moreover, more information about the label distribution can be inferred, such as the prediction reliability and uncertainties. We conduct extensive experiments on the label distribution prediction task, showing that our distribution modeling based method can achieve very competitive label distribution prediction performance compared with the state-of-the-art baselines. Additional experiments on active learning and ensemble learning demonstrate that our probabilistic approach can effectively boost the performance in these settings, by accurately estimating the prediction reliability and uncertainties.
Combating Confirmation Bias: A Unified Pseudo-Labeling Framework for Entity Alignment
Jul 05, 2023Entity alignment (EA) aims at identifying equivalent entity pairs across different knowledge graphs (KGs) that refer to the same real-world identity. To systematically combat confirmation bias for pseudo-labeling-based entity alignment, we propose a Unified Pseudo-Labeling framework for Entity Alignment (UPL-EA) that explicitly eliminates pseudo-labeling errors to boost the accuracy of entity alignment. UPL-EA consists of two complementary components: (1) The Optimal Transport (OT)-based pseudo-labeling uses discrete OT modeling as an effective means to enable more accurate determination of entity correspondences across two KGs and to mitigate the adverse impact of erroneous matches. A simple but highly effective criterion is further devised to derive pseudo-labeled entity pairs that satisfy one-to-one correspondences at each iteration. (2) The cross-iteration pseudo-label calibration operates across multiple consecutive iterations to further improve the pseudo-labeling precision rate by reducing the local pseudo-label selection variability with a theoretical guarantee. The two components are respectively designed to eliminate Type I and Type II pseudo-labeling errors identified through our analyse. The calibrated pseudo-labels are thereafter used to augment prior alignment seeds to reinforce subsequent model training for alignment inference. The effectiveness of UPL-EA in eliminating pseudo-labeling errors is both theoretically supported and experimentally validated. The experimental results show that our approach achieves competitive performance with limited prior alignment seeds.
Towards Complex Dynamic Physics System Simulation with Graph Neural ODEs
May 25, 2023



The great learning ability of deep learning models facilitates us to comprehend the real physical world, making learning to simulate complicated particle systems a promising endeavour. However, the complex laws of the physical world pose significant challenges to the learning based simulations, such as the varying spatial dependencies between interacting particles and varying temporal dependencies between particle system states in different time stamps, which dominate particles' interacting behaviour and the physical systems' evolution patterns. Existing learning based simulation methods fail to fully account for the complexities, making them unable to yield satisfactory simulations. To better comprehend the complex physical laws, this paper proposes a novel learning based simulation model- Graph Networks with Spatial-Temporal neural Ordinary Equations (GNSTODE)- that characterizes the varying spatial and temporal dependencies in particle systems using a united end-to-end framework. Through training with real-world particle-particle interaction observations, GNSTODE is able to simulate any possible particle systems with high precisions. We empirically evaluate GNSTODE's simulation performance on two real-world particle systems, Gravity and Coulomb, with varying levels of spatial and temporal dependencies. The results show that the proposed GNSTODE yields significantly better simulations than state-of-the-art learning based simulation methods, which proves that GNSTODE can serve as an effective solution to particle simulations in real-world application.
Beyond Smoothing: Unsupervised Graph Representation Learning with Edge Heterophily Discriminating
Nov 25, 2022
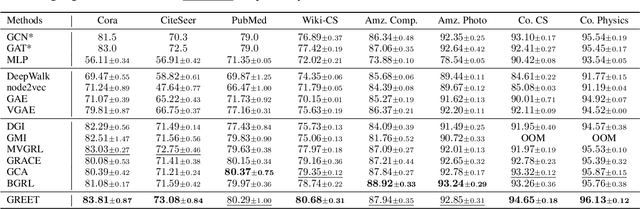
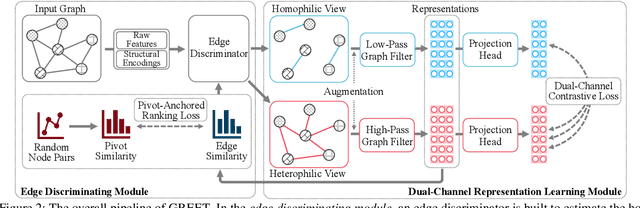
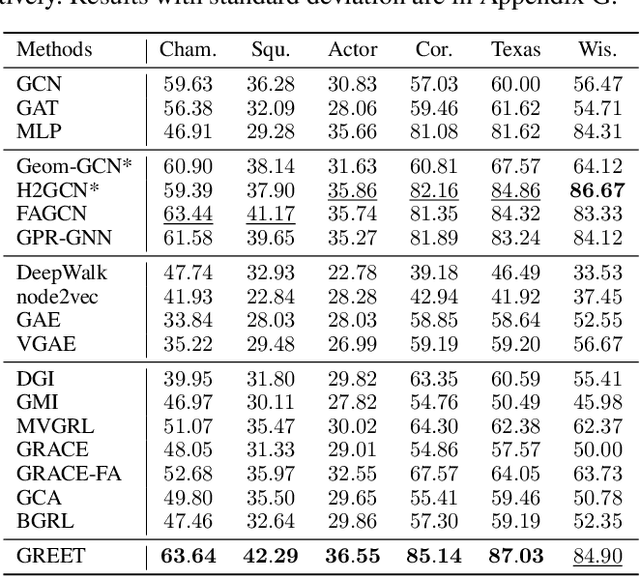
Unsupervised graph representation learning (UGRL) has drawn increasing research attention and achieved promising results in several graph analytic tasks. Relying on the homophily assumption, existing UGRL methods tend to smooth the learned node representations along all edges, ignoring the existence of heterophilic edges that connect nodes with distinct attributes. As a result, current methods are hard to generalize to heterophilic graphs where dissimilar nodes are widely connected, and also vulnerable to adversarial attacks. To address this issue, we propose a novel unsupervised Graph Representation learning method with Edge hEterophily discriminaTing (GREET) which learns representations by discriminating and leveraging homophilic edges and heterophilic edges. To distinguish two types of edges, we build an edge discriminator that infers edge homophily/heterophily from feature and structure information. We train the edge discriminator in an unsupervised way through minimizing the crafted pivot-anchored ranking loss, with randomly sampled node pairs acting as pivots. Node representations are learned through contrasting the dual-channel encodings obtained from the discriminated homophilic and heterophilic edges. With an effective interplaying scheme, edge discriminating and representation learning can mutually boost each other during the training phase. We conducted extensive experiments on 14 benchmark datasets and multiple learning scenarios to demonstrate the superiority of GREET.
Conflict-Aware Pseudo Labeling via Optimal Transport for Entity Alignment
Sep 05, 2022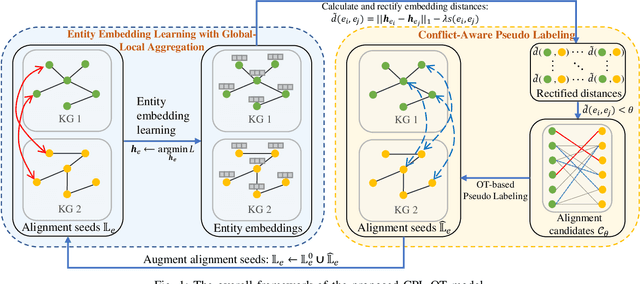
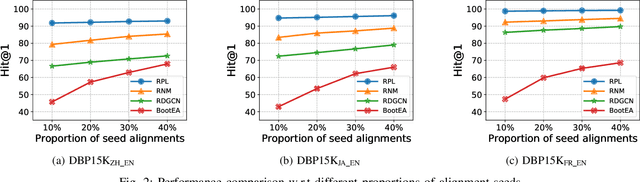
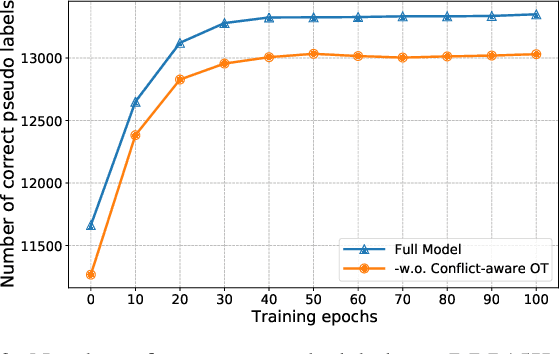
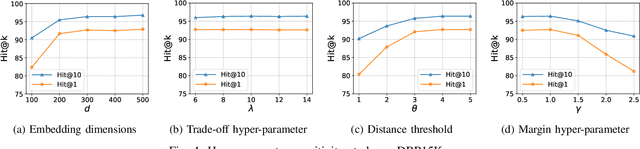
Entity alignment aims to discover unique equivalent entity pairs with the same meaning across different knowledge graphs (KG). It has been a compelling but challenging task for knowledge integration or fusion. Existing models have primarily focused on projecting KGs into a latent embedding space to capture inherent semantics between entities for entity alignment. However, the adverse impacts of alignment conflicts have been largely overlooked during training, thus limiting the entity alignment performance. To address this issue, we propose a novel Conflict-aware Pseudo Labeling via Optimal Transport model (CPL-OT) for entity alignment. The key idea of CPL-OT is to iteratively pseudo-label alignment pairs empowered with conflict-aware Optimal Transport modeling to boost the precision of entity alignment. CPL-OT is composed of two key components-entity embedding learning with global-local aggregation and iterative conflict-aware pseudo labeling-that mutually reinforce each other. To mitigate alignment conflicts during pseudo labeling, we propose to use optimal transport (OT) as an effective means to warrant one-to-one entity alignment between two KGs with the minimal overall transport cost. The transport cost is calculated as the rectified distance between entity embeddings obtained via graph convolution augmented with global-level semantics. Extensive experiments on benchmark datasets show that CPL-OT can markedly outperform state-of-the-art baselines under both settings with and without prior alignment seeds.
Link Prediction with Contextualized Self-Supervision
Jan 25, 2022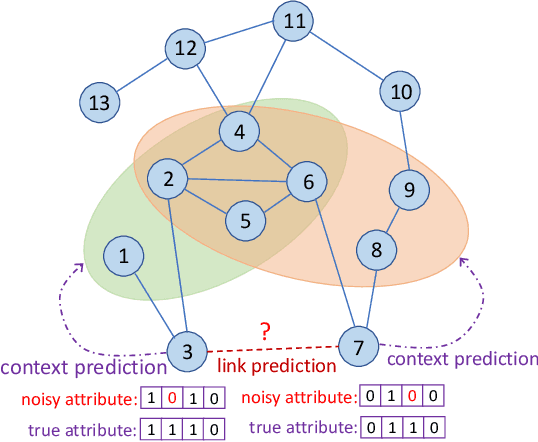


Link prediction aims to infer the existence of a link between two nodes in a network. Despite their wide application, the success of traditional link prediction algorithms is hindered by three major challenges -- link sparsity, node attribute noise and network dynamics -- that are faced by real-world networks. To overcome these challenges, we propose a Contextualized Self-Supervised Learning (CSSL) framework that fully exploits structural context prediction for link prediction. The proposed CSSL framework forms edge embeddings through aggregating pairs of node embeddings constructed via a transformation on node attributes, which are used to predict the link existence probability. To generate node embeddings tailored for link prediction, structural context prediction is leveraged as a self-supervised learning task to boost link prediction. Two types of structural contexts are investigated, i.e., context nodes collected from random walks vs. context subgraphs. The CSSL framework can be trained in an end-to-end manner, with the learning of node and edge embeddings supervised by link prediction and the self-supervised learning task. The proposed CSSL is a generic and flexible framework in the sense that it can handle both transductive and inductive link prediction settings, and both attributed and non-attributed networks. Extensive experiments and ablation studies on seven real-world benchmark graph datasets demonstrate the superior performance of the proposed self-supervision based link prediction algorithm over state-of-the-art baselines on different types of networks under both transductive and inductive settings. The proposed CSSL also yields competitive performance in terms of its robustness to node attribute noise and scalability over large-scale networks.
Towards Unsupervised Deep Graph Structure Learning
Jan 17, 2022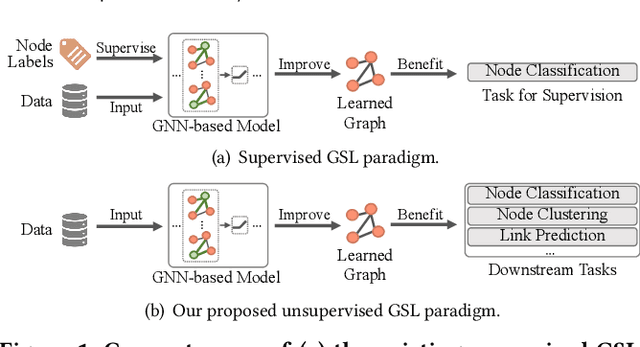
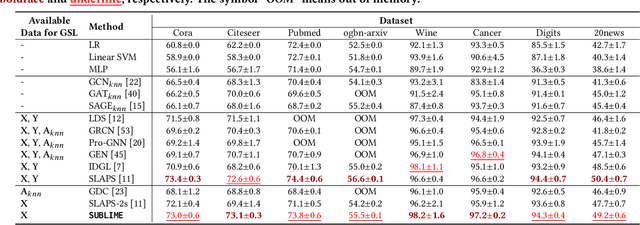
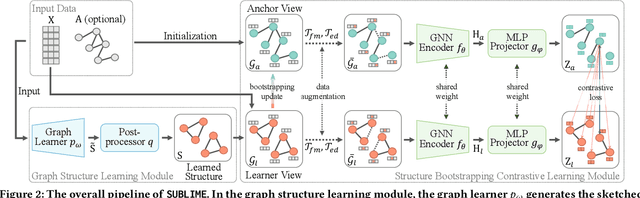
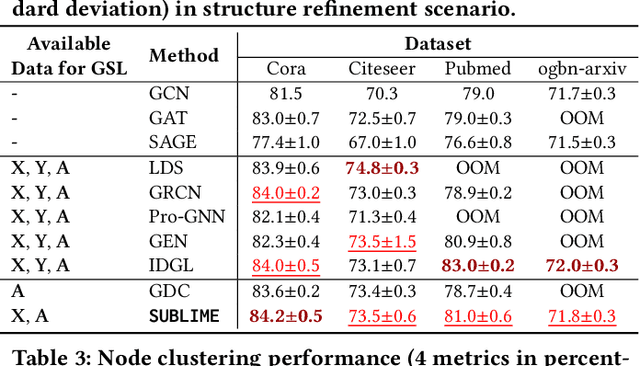
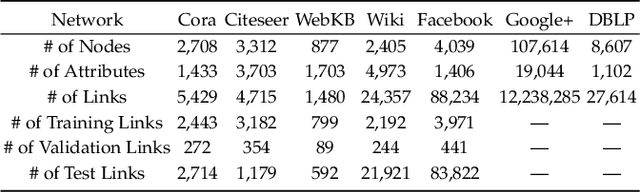
In recent years, graph neural networks (GNNs) have emerged as a successful tool in a variety of graph-related applications. However, the performance of GNNs can be deteriorated when noisy connections occur in the original graph structures; besides, the dependence on explicit structures prevents GNNs from being applied to general unstructured scenarios. To address these issues, recently emerged deep graph structure learning (GSL) methods propose to jointly optimize the graph structure along with GNN under the supervision of a node classification task. Nonetheless, these methods focus on a supervised learning scenario, which leads to several problems, i.e., the reliance on labels, the bias of edge distribution, and the limitation on application tasks. In this paper, we propose a more practical GSL paradigm, unsupervised graph structure learning, where the learned graph topology is optimized by data itself without any external guidance (i.e., labels). To solve the unsupervised GSL problem, we propose a novel StrUcture Bootstrapping contrastive LearnIng fraMEwork (SUBLIME for abbreviation) with the aid of self-supervised contrastive learning. Specifically, we generate a learning target from the original data as an "anchor graph", and use a contrastive loss to maximize the agreement between the anchor graph and the learned graph. To provide persistent guidance, we design a novel bootstrapping mechanism that upgrades the anchor graph with learned structures during model learning. We also design a series of graph learners and post-processing schemes to model the structures to learn. Extensive experiments on eight benchmark datasets demonstrate the significant effectiveness of our proposed SUBLIME and high quality of the optimized graphs.
Search Efficient Binary Network Embedding
Jan 14, 2019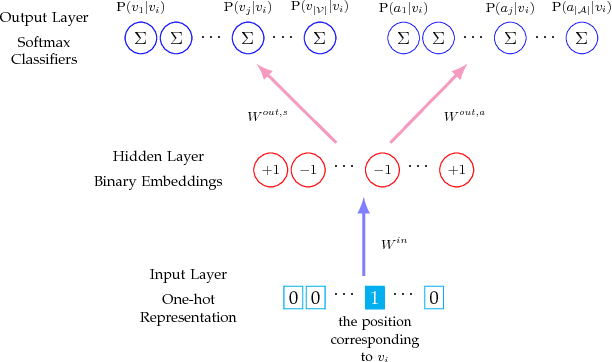

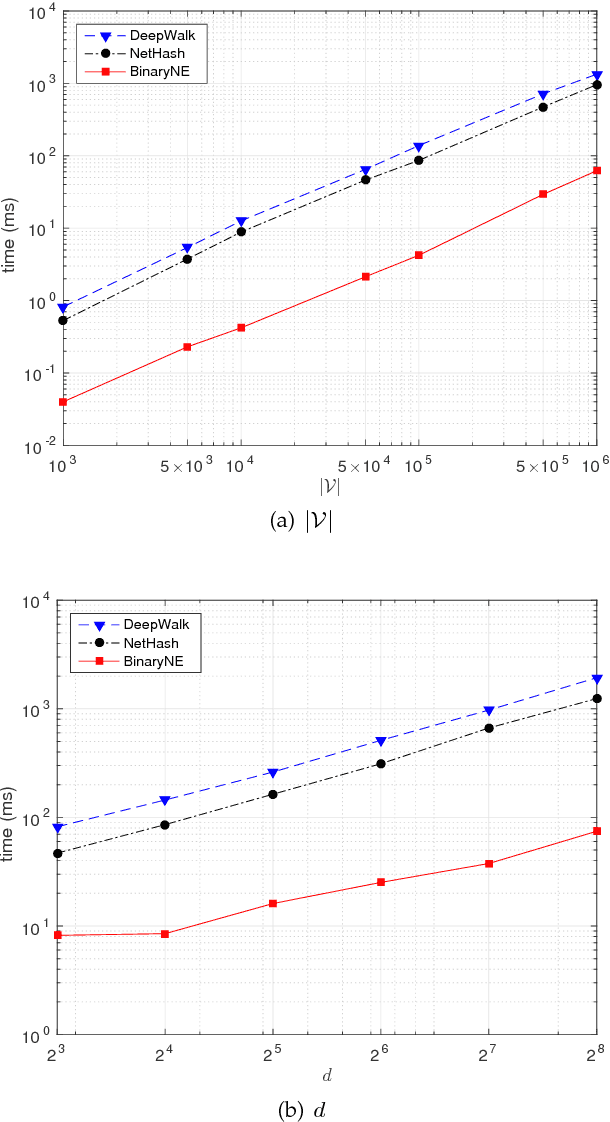
Traditional network embedding primarily focuses on learning a dense vector representation for each node, which encodes network structure and/or node content information, such that off-the-shelf machine learning algorithms can be easily applied to the vector-format node representations for network analysis. However, the learned dense vector representations are inefficient for large-scale similarity search, which requires to find the nearest neighbor measured by Euclidean distance in a continuous vector space. In this paper, we propose a search efficient binary network embedding algorithm called BinaryNE to learn a sparse binary code for each node, by simultaneously modeling node context relations and node attribute relations through a three-layer neural network. BinaryNE learns binary node representations efficiently through a stochastic gradient descent based online learning algorithm. The learned binary encoding not only reduces memory usage to represent each node, but also allows fast bit-wise comparisons to support much quicker network node search compared to Euclidean distance or other distance measures. Our experiments and comparisons show that BinaryNE not only delivers more than 23 times faster search speed, but also provides comparable or better search quality than traditional continuous vector based network embedding methods.