 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Driven Reasoning Video Editing via Reinforcement Learning on Digital Twin Representations
Nov 18, 2025Text-driven video editing enables users to modify video content only using text queries. While existing methods can modify video content if explicit descriptions of editing targets with precise spatial locations and temporal boundaries are provided, these requirements become impractical when users attempt to conceptualize edits through implicit queries referencing semantic properties or object relationships. We introduce reasoning video editing, a task where video editing models must interpret implicit queries through multi-hop reasoning to infer editing targets before executing modifications, and a first model attempting to solve this complex task, RIVER (Reasoning-based Implicit Video Editor). RIVER decouples reasoning from generation through digital twin representations of video content that preserve spatial relationships, temporal trajectories, and semantic attributes. A large language model then processes this representation jointly with the implicit query, performing multi-hop reasoning to determine modifications, then outputs structured instructions that guide a diffusion-based editor to execute pixel-level changes. RIVER training uses reinforcement learning with rewards that evaluate reasoning accuracy and generation quality. Finally, we introduce RVEBenchmark, a benchmark of 100 videos with 519 implicit queries spanning three levels and categories of reasoning complexity specifically for reasoning video editing. RIVER demonstrates best performance on the proposed RVEBenchmark and also achieves state-of-the-art performance on two additional video editing benchmarks (VegGIE and FiVE), where it surpasses six baseline methods.
Reasoning Text-to-Video Retrieval via Digital Twin Video Representations and Large Language Models
Nov 15, 2025The goal of text-to-video retrieval is to search large databases for relevant videos based on text queries. Existing methods have progressed to handling explicit queries where the visual content of interest is described explicitly; however, they fail with implicit queries where identifying videos relevant to the query requires reasoning. We introduce reasoning text-to-video retrieval, a paradigm that extends traditional retrieval to process implicit queries through reasoning while providing object-level grounding masks that identify which entities satisfy the query conditions. Instead of relying on vision-language models directly, we propose representing video content as digital twins, i.e., structured scene representations that decompose salient objects through specialist vision models. This approach is beneficial because it enables large language models to reason directly over long-horizon video content without visual token compression. Specifically, our two-stage framework first performs compositional alignment between decomposed sub-queries and digital twin representations for candidate identification, then applies large language model-based reasoning with just-in-time refinement that invokes additional specialist models to address information gaps. We construct a benchmark of 447 manually created implicit queries with 135 videos (ReasonT2VBench-135) and another more challenging version of 1000 videos (ReasonT2VBench-1000). Our method achieves 81.2% R@1 on ReasonT2VBench-135, outperforming the strongest baseline by greater than 50 percentage points, and maintains 81.7% R@1 on the extended configuration while establishing state-of-the-art results in three conventional benchmarks (MSR-VTT, MSVD, and VATEX).
TwinOR: Photorealistic Digital Twins of Dynamic Operating Rooms for Embodied AI Research
Nov 10, 2025Developing embodied AI for intelligent surgical systems requires safe, controllable environments for continual learning and evaluation. However, safety regulations and operational constraints in operating rooms (ORs) limit embodied agents from freely perceiving and interacting in realistic settings. Digital twins provide high-fidelity, risk-free environments for exploration and training. How we may create photorealistic and dynamic digital representations of ORs that capture relevant spatial, visual, and behavioral complexity remains unclear. We introduce TwinOR, a framework for constructing photorealistic, dynamic digital twins of ORs for embodied AI research. The system reconstructs static geometry from pre-scan videos and continuously models human and equipment motion through multi-view perception of OR activities. The static and dynamic components are fused into an immersive 3D environment that supports controllable simulation and embodied exploration. The proposed framework reconstructs complete OR geometry with centimeter level accuracy while preserving dynamic interaction across surgical workflows, enabling realistic renderings and a virtual playground for embodied AI systems. In our experiments, TwinOR simulates stereo and monocular sensor streams for geometry understanding and visual localization tasks. Models such as FoundationStereo and ORB-SLAM3 on TwinOR-synthesized data achieve performance within their reported accuracy on real indoor datasets, demonstrating that TwinOR provides sensor-level realism sufficient for perception and localization challenges. By establishing a real-to-sim pipeline for constructing dynamic, photorealistic digital twins of OR environments, TwinOR enables the safe, scalable, and data-efficient development and benchmarking of embodied AI, ultimately accelerating the deployment of embodied AI from sim-to-real.
Temporally-Constrained Video Reasoning Segmentation and Automated Benchmark Construction
Jul 22, 2025Conventional approaches to video segmentation are confined to predefined object categories and cannot identify out-of-vocabulary objects, let alone objects that are not identified explicitly but only referred to implicitly in complex text queries. This shortcoming limits the utility for video segmentation in complex and variable scenarios, where a closed set of object categories is difficult to define and where users may not know the exact object category that will appear in the video. Such scenarios can arise in operating room video analysis, where different health systems may use different workflows and instrumentation, requiring flexible solutions for video analysis. Reasoning segmentation (RS) now offers promise towards such a solution, enabling natural language text queries as interaction for identifying object to segment. However, existing video RS formulation assume that target objects remain contextually relevant throughout entire video sequences. This assumption is inadequate for real-world scenarios in which objects of interest appear, disappear or change relevance dynamically based on temporal context, such as surgical instruments that become relevant only during specific procedural phases or anatomical structures that gain importance at particular moments during surgery. Our first contribution is the introduction of temporally-constrained video reasoning segmentation, a novel task formulation that requires models to implicitly infer when target objects become contextually relevant based on text queries that incorporate temporal reasoning. Since manual annotation of temporally-constrained video RS datasets would be expensive and limit scalability, our second contribution is an innovative automated benchmark construction method. Finally, we present TCVideoRSBenchmark, a temporally-constrained video RS dataset containing 52 samples using the videos from the MVOR dataset.
Reasoning Segmentation for Images and Videos: A Survey
May 24, 2025Reasoning Segmentation (RS) aims to delineate objects based on implicit text queries, the interpretation of which requires reasoning and knowledge integration. Unlike the traditional formulation of segmentation problems that relies on fixed semantic categories or explicit prompting, RS bridges the gap between visual perception and human-like reasoning capabilities, facilitating more intuitive human-AI interaction through natural language. Our work presents the first comprehensive survey of RS for image and video processing, examining 26 state-of-the-art methods together with a review of the corresponding evaluation metrics, as well as 29 datasets and benchmarks. We also explore existing applications of RS across diverse domains and identify their potential extensions. Finally, we identify current research gaps and highlight promising future directions.
RVTBench: A Benchmark for Visual Reasoning Tasks
May 17, 2025Visual reasoning, the capability to interpret visual input in response to implicit text query through multi-step reasoning, remains a challenge for deep learning models due to the lack of relevant benchmarks. Previous work in visual reasoning has primarily focused on reasoning segmentation, where models aim to segment objects based on implicit text queries. This paper introduces reasoning visual tasks (RVTs), a unified formulation that extends beyond traditional video reasoning segmentation to a diverse family of visual language reasoning problems, which can therefore accommodate multiple output formats including bounding boxes, natural language descriptions, and question-answer pairs. Correspondingly, we identify the limitations in current benchmark construction methods that rely solely on large language models (LLMs), which inadequately capture complex spatial-temporal relationships and multi-step reasoning chains in video due to their reliance on token representation, resulting in benchmarks with artificially limited reasoning complexity. To address this limitation, we propose a novel automated RVT benchmark construction pipeline that leverages digital twin (DT) representations as structured intermediaries between perception and the generation of implicit text queries. Based on this method, we construct RVTBench, a RVT benchmark containing 3,896 queries of over 1.2 million tokens across four types of RVT (segmentation, grounding, VQA and summary), three reasoning categories (semantic, spatial, and temporal), and four increasing difficulty levels, derived from 200 video sequences. Finally, we propose RVTagent, an agent framework for RVT that allows for zero-shot generalization across various types of RVT without task-specific fine-tuning.
Online Reasoning Video Segmentation with Just-in-Time Digital Twins
Mar 27, 2025Reasoning segmentation (RS) aims to identify and segment objects of interest based on implicit text queries. As such, RS is a catalyst for embodied AI agents, enabling them to interpret high-level commands without requiring explicit step-by-step guidance. However, current RS approaches rely heavily on the visual perception capabilities of multimodal large language models (LLMs), leading to several major limitations. First, they struggle with queries that require multiple steps of reasoning or those that involve complex spatial/temporal relationships. Second, they necessitate LLM fine-tuning, which may require frequent updates to maintain compatibility with contemporary LLMs and may increase risks of catastrophic forgetting during fine-tuning. Finally, being primarily designed for static images or offline video processing, they scale poorly to online video data. To address these limitations, we propose an agent framework that disentangles perception and reasoning for online video RS without LLM fine-tuning. Our innovation is the introduction of a just-in-time digital twin concept, where -- given an implicit query -- a LLM plans the construction of a low-level scene representation from high-level video using specialist vision models. We refer to this approach to creating a digital twin as "just-in-time" because the LLM planner will anticipate the need for specific information and only request this limited subset instead of always evaluating every specialist model. The LLM then performs reasoning on this digital twin representation to identify target objects. To evaluate our approach, we introduce a new comprehensive video reasoning segmentation benchmark comprising 200 videos with 895 implicit text queries. The benchmark spans three reasoning categories (semantic, spatial, and temporal) with three different reasoning chain complexity.
Operating Room Workflow Analysis via Reasoning Segmentation over Digital Twins
Mar 26, 2025Analyzing operating room (OR) workflows to derive quantitative insights into OR efficiency is important for hospitals to maximize patient care and financial sustainability. Prior work on OR-level workflow analysis has relied on end-to-end deep neural networks. While these approaches work well in constrained settings, they are limited to the conditions specified at development time and do not offer the flexibility necessary to accommodate the OR workflow analysis needs of various OR scenarios (e.g., large academic center vs. rural provider) without data collection, annotation, and retraining. Reasoning segmentation (RS) based on foundation models offers this flexibility by enabling automated analysis of OR workflows from OR video feeds given only an implicit text query related to the objects of interest. Due to the reliance on large language model (LLM) fine-tuning, current RS approaches struggle with reasoning about semantic/spatial relationships and show limited generalization to OR video due to variations in visual characteristics and domain-specific terminology. To address these limitations, we first propose a novel digital twin (DT) representation that preserves both semantic and spatial relationships between the various OR components. Then, building on this foundation, we propose ORDiRS (Operating Room Digital twin representation for Reasoning Segmentation), an LLM-tuning-free RS framework that reformulates RS into a "reason-retrieval-synthesize" paradigm. Finally, we present ORDiRS-Agent, an LLM-based agent that decomposes OR workflow analysis queries into manageable RS sub-queries and generates responses by combining detailed textual explanations with supporting visual evidence from RS. Experimental results on both an in-house and a public OR dataset demonstrate that our ORDiRS achieves a cIoU improvement of 6.12%-9.74% compared to the existing state-of-the-arts.
Ultralow complexity long short-term memory network for fiber nonlinearity mitigation in coherent optical communication systems
Aug 12, 2021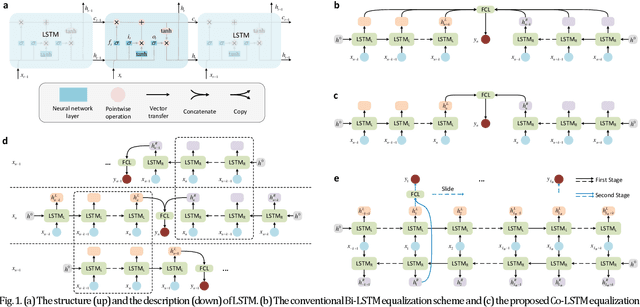

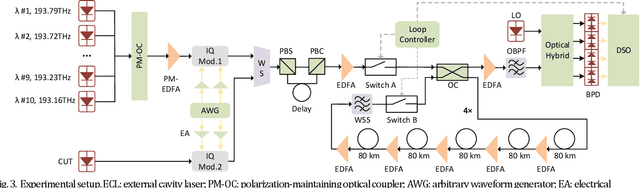
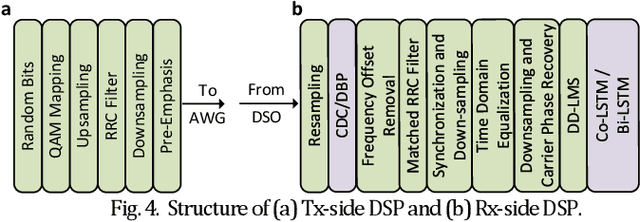
Fiber Kerr nonlinearity is a fundamental limitation to the achievable capacity of long-distance optical fiber communication. Digital back-propagation (DBP) is a primary methodology to mitigate both linear and nonlinear impairments by solving the inverse-propagating nonlinear Schr\"odinger equation (NLSE), which requires detailed link information. Recently, the paradigms based on neural network (NN) were proposed to mitigate nonlinear transmission impairments in optical communication systems. However, almost all neural network-based equalization schemes yield high computation complexity, which prevents the practical implementation in commercial transmission systems. In this paper, we propose a center-oriented long short-term memory network (Co-LSTM) incorporating a simplified mode with a recycling mechanism in the equalization operation, which can mitigate fiber nonlinearity in coherent optical communication systems with ultralow complexity. To validate the proposed methodology, we carry out an experiment of ten-channel wavelength division multiplexing (WDM) transmission with 64 Gbaud polarization-division-multiplexed 16-ary quadrature amplitude modulation (16-QAM) signals. Co-LSTM and DBP achieve a comparable performance of nonlinear mitigation. However, the complexity of Co-LSTM with a simplified mode is almost independent of the transmission distance, which is much lower than that of the DBP. The proposed Co-LSTM methodology presents an attractive approach for low complexity nonlinearity mitigation with neural networks.