 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multitask framework for automated interpretation of multi-frame right upper quadrant ultrasound in clinical decision support
Jan 17, 2026Ultrasound is a cornerstone of emergency and hepatobiliary imaging, yet its interpretation remains highly operator-dependent and time-sensitive. Here, we present a multitask vision-language agent (VLM) developed to assist with comprehensive right upper quadrant (RUQ) ultrasound interpretation across the full diagnostic workflow. The system was trained on a large, multi-center dataset comprising a primary cohort from Johns Hopkins Medical Institutions (9,189 cases, 594,099 images) and externally validated on cohorts from Stanford University (108 cases, 3,240 images) and a major Chinese medical center (257 cases, 3,178 images). Built on the Qwen2.5-VL-7B architecture, the agent integrates frame-level visual understanding with report-grounded language reasoning to perform three tasks: (i) classification of 18 hepatobiliary and gallbladder conditions, (ii) generation of clinically coherent diagnostic reports, and (iii) surgical decision support based on ultrasound findings and clinical data. The model achieved high diagnostic accuracy across all tasks, generated reports that were indistinguishable from expert-written versions in blinded evaluations, and demonstrated superior factual accuracy and information density on content-based metrics. The agent further identified patients requiring cholecystectomy with high precision, supporting real-time decision-making. These results highlight the potential of generalist vision-language models to improve diagnostic consistency, reporting efficiency, and surgical triage in real-world ultrasound practice.
Dataset and Benchmark for Enhancing Critical Retained Foreign Object Detection
Jul 09, 2025Critical retained foreign objects (RFOs), including surgical instruments like sponges and needles, pose serious patient safety risks and carry significant financial and legal implications for healthcare institutions. Detecting critical RFOs using artificial intelligence remains challenging due to their rarity and the limited availability of chest X-ray datasets that specifically feature critical RFOs cases. Existing datasets only contain non-critical RFOs, like necklace or zipper, further limiting their utility for developing clinically impactful detection algorithms. To address these limitations, we introduce "Hopkins RFOs Bench", the first and largest dataset of its kind, containing 144 chest X-ray images of critical RFO cases collected over 18 years from the Johns Hopkins Health System. Using this dataset, we benchmark several state-of-the-art object detection models, highlighting the need for enhanced detection methodologies for critical RFO cases. Recognizing data scarcity challenges, we further explore image synthetic methods to bridge this gap. We evaluate two advanced synthetic image methods, DeepDRR-RFO, a physics-based method, and RoentGen-RFO, a diffusion-based method, for creating realistic radiographs featuring critical RFOs. Our comprehensive analysis identifies the strengths and limitations of each synthetic method, providing insights into effectively utilizing synthetic data to enhance model training. The Hopkins RFOs Bench and our findings significantly advance the development of reliable, generalizable AI-driven solutions for detecting critical RFOs in clinical chest X-rays.
Operating Room Workflow Analysis via Reasoning Segmentation over Digital Twins
Mar 26, 2025


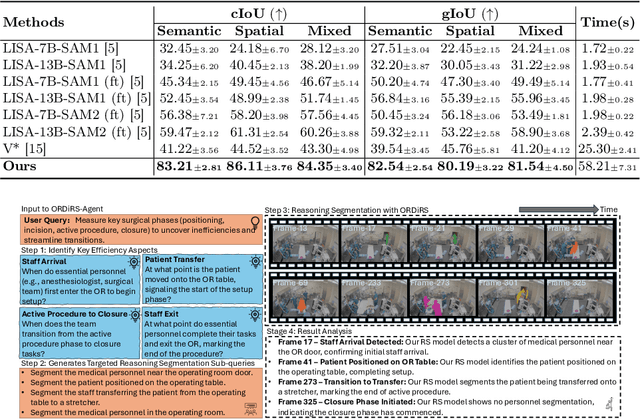
Analyzing operating room (OR) workflows to derive quantitative insights into OR efficiency is important for hospitals to maximize patient care and financial sustainability. Prior work on OR-level workflow analysis has relied on end-to-end deep neural networks. While these approaches work well in constrained settings, they are limited to the conditions specified at development time and do not offer the flexibility necessary to accommodate the OR workflow analysis needs of various OR scenarios (e.g., large academic center vs. rural provider) without data collection, annotation, and retraining. Reasoning segmentation (RS) based on foundation models offers this flexibility by enabling automated analysis of OR workflows from OR video feeds given only an implicit text query related to the objects of interest. Due to the reliance on large language model (LLM) fine-tuning, current RS approaches struggle with reasoning about semantic/spatial relationships and show limited generalization to OR video due to variations in visual characteristics and domain-specific terminology. To address these limitations, we first propose a novel digital twin (DT) representation that preserves both semantic and spatial relationships between the various OR components. Then, building on this foundation, we propose ORDiRS (Operating Room Digital twin representation for Reasoning Segmentation), an LLM-tuning-free RS framework that reformulates RS into a "reason-retrieval-synthesize" paradigm. Finally, we present ORDiRS-Agent, an LLM-based agent that decomposes OR workflow analysis queries into manageable RS sub-queries and generates responses by combining detailed textual explanations with supporting visual evidence from RS. Experimental results on both an in-house and a public OR dataset demonstrate that our ORDiRS achieves a cIoU improvement of 6.12%-9.74% compared to the existing state-of-the-arts.
Towards a Holistic Framework for Multimodal Large Language Models in Three-dimensional Brain CT Report Generation
Jul 02, 2024Multi-modal large language models (MLLMs) have been given free rein to explore exciting medical applications with a primary focus on radiology report generation. Nevertheless, the preliminary success in 2D radiology captioning is incompetent to reflect the real-world diagnostic challenge in the volumetric 3D anatomy. To mitigate three crucial limitation aspects in the existing literature, including (1) data complexity, (2) model capacity, and (3) evaluation metric fidelity, we collected an 18,885 text-scan pairs 3D-BrainCT dataset and applied clinical visual instruction tuning (CVIT) to train BrainGPT models to generate radiology-adherent 3D brain CT reports. Statistically, our BrainGPT scored BLEU-1 = 44.35, BLEU-4 = 20.38, METEOR = 30.13, ROUGE-L = 47.6, and CIDEr-R = 211.77 during internal testing and demonstrated an accuracy of 0.91 in captioning midline shifts on the external validation CQ500 dataset. By further inspecting the captioned report, we reported that the traditional metrics appeared to measure only the surface text similarity and failed to gauge the information density of the diagnostic purpose. To close this gap, we proposed a novel Feature-Oriented Radiology Task Evaluation (FORTE) to estimate the report's clinical relevance (lesion feature and landmarks). Notably, the BrainGPT model scored an average FORTE F1-score of 0.71 (degree=0.661; landmark=0.706; feature=0.693; impression=0.779). To demonstrate that BrainGPT models possess objective readiness to generate human-like radiology reports, we conducted a Turing test that enrolled 11 physician evaluators, and around 74% of the BrainGPT-generated captions were indistinguishable from those written by humans. Our work embodies a holistic framework that showcased the first-hand experience of curating a 3D brain CT dataset, fine-tuning anatomy-sensible language models, and proposing robust radiology evaluation metrics.
Asclepius: A Spectrum Evaluation Benchmark for Medical Multi-Modal Large Language Models
Feb 17, 2024



The significant breakthroughs of Medical Multi-Modal Large Language Models (Med-MLLMs) renovate modern healthcare with robust information synthesis and medical decision support. However, these models are often evaluated on benchmarks that are unsuitable for the Med-MLLMs due to the intricate nature of the real-world diagnostic frameworks, which encompass diverse medical specialties and involve complex clinical decisions. Moreover, these benchmarks are susceptible to data leakage, since Med-MLLMs are trained on large assemblies of publicly available data. Thus, an isolated and clinically representative benchmark is highly desirable for credible Med-MLLMs evaluation. To this end, we introduce Asclepius, a novel Med-MLLM benchmark that rigorously and comprehensively assesses model capability in terms of: distinct medical specialties (cardiovascular, gastroenterology, etc.) and different diagnostic capacities (perception, disease analysis, etc.). Grounded in 3 proposed core principles, Asclepius ensures a comprehensive evaluation by encompassing 15 medical specialties, stratifying into 3 main categories and 8 sub-categories of clinical tasks, and exempting from train-validate contamination. We further provide an in-depth analysis of 6 Med-MLLMs and compare them with 5 human specialists, providing insights into their competencies and limitations in various medical contexts. Our work not only advances the understanding of Med-MLLMs' capabilities but also sets a precedent for future evaluations and the safe deployment of these models in clinical environments. We launch and maintain a leaderboard for community assessment of Med-MLLM capabilities (https://asclepius-med.github.io/).