 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Holistic Framework for Multimodal Large Language Models in Three-dimensional Brain CT Report Generation
Jul 02, 2024Multi-modal large language models (MLLMs) have been given free rein to explore exciting medical applications with a primary focus on radiology report generation. Nevertheless, the preliminary success in 2D radiology captioning is incompetent to reflect the real-world diagnostic challenge in the volumetric 3D anatomy. To mitigate three crucial limitation aspects in the existing literature, including (1) data complexity, (2) model capacity, and (3) evaluation metric fidelity, we collected an 18,885 text-scan pairs 3D-BrainCT dataset and applied clinical visual instruction tuning (CVIT) to train BrainGPT models to generate radiology-adherent 3D brain CT reports. Statistically, our BrainGPT scored BLEU-1 = 44.35, BLEU-4 = 20.38, METEOR = 30.13, ROUGE-L = 47.6, and CIDEr-R = 211.77 during internal testing and demonstrated an accuracy of 0.91 in captioning midline shifts on the external validation CQ500 dataset. By further inspecting the captioned report, we reported that the traditional metrics appeared to measure only the surface text similarity and failed to gauge the information density of the diagnostic purpose. To close this gap, we proposed a novel Feature-Oriented Radiology Task Evaluation (FORTE) to estimate the report's clinical relevance (lesion feature and landmarks). Notably, the BrainGPT model scored an average FORTE F1-score of 0.71 (degree=0.661; landmark=0.706; feature=0.693; impression=0.779). To demonstrate that BrainGPT models possess objective readiness to generate human-like radiology reports, we conducted a Turing test that enrolled 11 physician evaluators, and around 74% of the BrainGPT-generated captions were indistinguishable from those written by humans. Our work embodies a holistic framework that showcased the first-hand experience of curating a 3D brain CT dataset, fine-tuning anatomy-sensible language models, and proposing robust radiology evaluation metrics.
Revisiting 3D Context Modeling with Supervised Pre-training for Universal Lesion Detection in CT Slices
Dec 16, 2020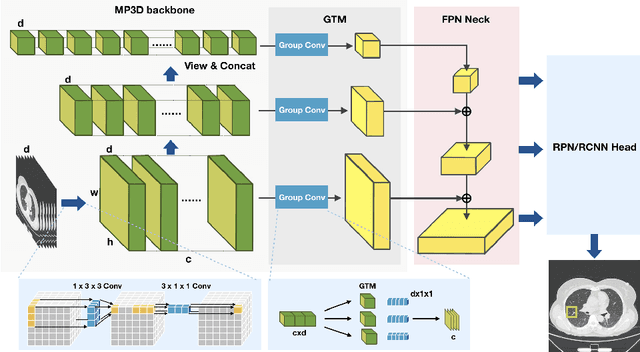
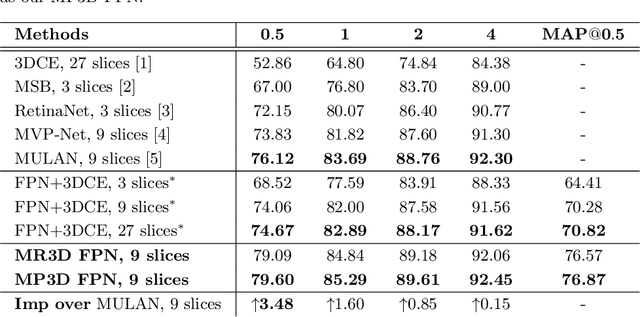
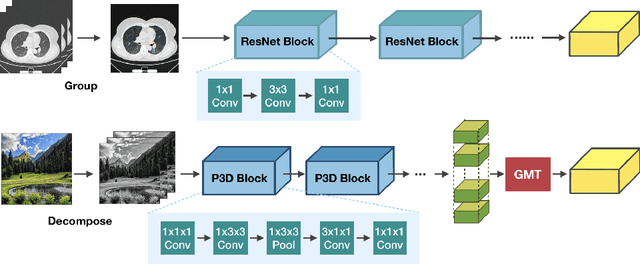

Universal lesion detection from computed tomography (CT) slices is important for comprehensive disease screening. Since each lesion can locate in multiple adjacent slices, 3D context modeling is of great significance for developing automated lesion detection algorithms. In this work, we propose a Modified Pseudo-3D Feature Pyramid Network (MP3D FPN) that leverages depthwise separable convolutional filters and a group transform module (GTM) to efficiently extract 3D context enhanced 2D features for universal lesion detection in CT slices. To facilitate faster convergence, a novel 3D network pre-training method is derived using solely large-scale 2D object detection dataset in the natural image domain. We demonstrate that with the novel pre-training method, the proposed MP3D FPN achieves state-of-the-art detection performance on the DeepLesion dataset (3.48% absolute improvement in the sensitivity of FPs@0.5), significantly surpassing the baseline method by up to 6.06% (in MAP@0.5) which adopts 2D convolution for 3D context modeling. Moreover, the proposed 3D pre-trained weights can potentially be used to boost the performance of other 3D medical image analysis tasks.