 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Weather Image Restoration via Histogram-Based Transformer Feature Enhancement
Sep 10, 2024



Currently, the mainstream restoration tasks under adverse weather conditions have predominantly focused on single-weather scenarios. However, in reality, multiple weather conditions always coexist and their degree of mixing is usually unknown. Under such complex and diverse weather conditions, single-weather restoration models struggle to meet practical demands. This is particularly critical in fields such as autonomous driving, where there is an urgent need for a model capable of effectively handling mixed weather conditions and enhancing image quality in an automated manner. In this paper, we propose a Task Sequence Generator module that, in conjunction with the Task Intra-patch Block, effectively extracts task-specific features embedded in degraded images. The Task Intra-patch Block introduces an external learnable sequence that aids the network in capturing task-specific information. Additionally, we employ a histogram-based transformer module as the backbone of our network, enabling the capture of both global and local dynamic range features. Our proposed model achieves state-of-the-art performance on public datasets.
Multiple weather images restoration using the task transformer and adaptive mixup strategy
Sep 05, 2024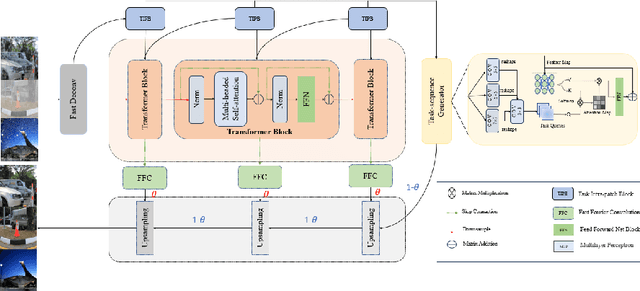

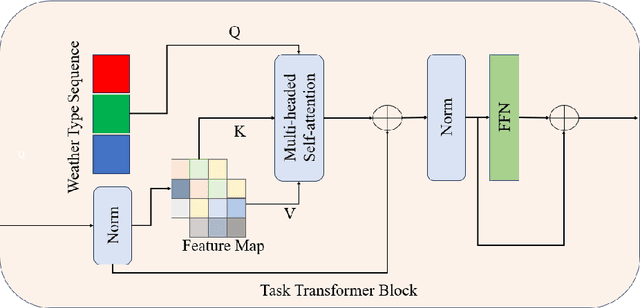

The current state-of-the-art in severe weather removal predominantly focuses on single-task applications, such as rain removal, haze removal, and snow removal. However, real-world weather conditions often consist of a mixture of several weather types, and the degree of weather mixing in autonomous driving scenarios remains unknown. In the presence of complex and diverse weather conditions, a single weather removal model often encounters challenges in producing clear images from severe weather images. Therefore, there is a need for the development of multi-task severe weather removal models that can effectively handle mixed weather conditions and improve image quality in autonomous driving scenarios. In this paper, we introduce a novel multi-task severe weather removal model that can effectively handle complex weather conditions in an adaptive manner. Our model incorporates a weather task sequence generator, enabling the self-attention mechanism to selectively focus on features specific to different weather types. To tackle the challenge of repairing large areas of weather degradation, we introduce Fast Fourier Convolution (FFC) to increase the receptive field. Additionally, we propose an adaptive upsampling technique that effectively processes both the weather task information and underlying image features by selectively retaining relevant information. Our proposed model has achieved state-of-the-art performance on the publicly available dataset.
Hierarchical Complementary Learning for Weakly Supervised Object Localization
Nov 16, 2020
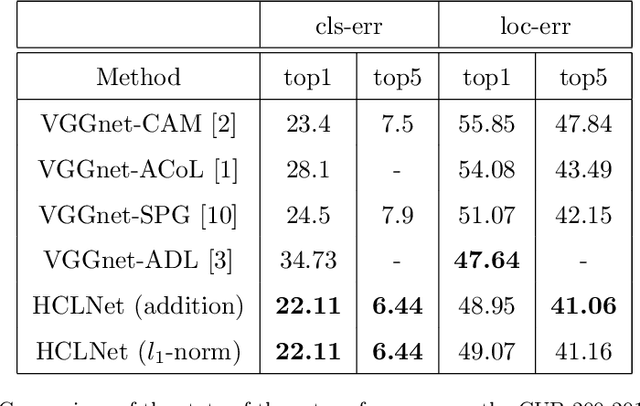

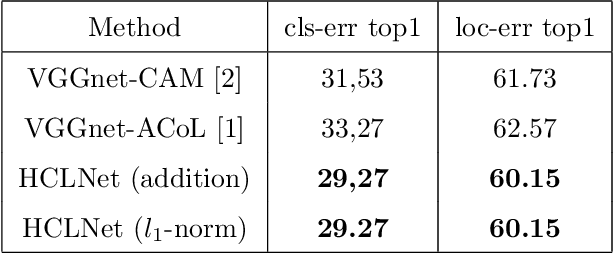
Weakly supervised object localization (WSOL) is a challenging problem which aims to localize objects with only image-level labels. Due to the lack of ground truth bounding boxes, class labels are mainly employed to train the model. This model generates a class activation map (CAM) which activates the most discriminate features. However, the main drawback of CAM is the ability to detect just a part of the object. To solve this problem, some researchers have removed parts from the detected object \cite{b1, b2, b4}, or the image \cite{b3}. The aim of removing parts from image or detected parts of the object is to force the model to detect the other features. However, these methods require one or many hyper-parameters to erase the appropriate pixels on the image, which could involve a loss of information. In contrast, this paper proposes a Hierarchical Complementary Learning Network method (HCLNet) that helps the CNN to perform better classification and localization of objects on the images. HCLNet uses a complementary map to force the network to detect the other parts of the object. Unlike previous works, this method does not need any extras hyper-parameters to generate different CAMs, as well as does not introduce a big loss of information. In order to fuse these different maps, two different fusion strategies known as the addition strategy and the l1-norm strategy have been used. These strategies allowed to detect the whole object while excluding the background. Extensive experiments show that HCLNet obtains better performance than state-of-the-art methods.
Entropy Guided Adversarial Model for Weakly Supervised Object Localization
Aug 04, 2020
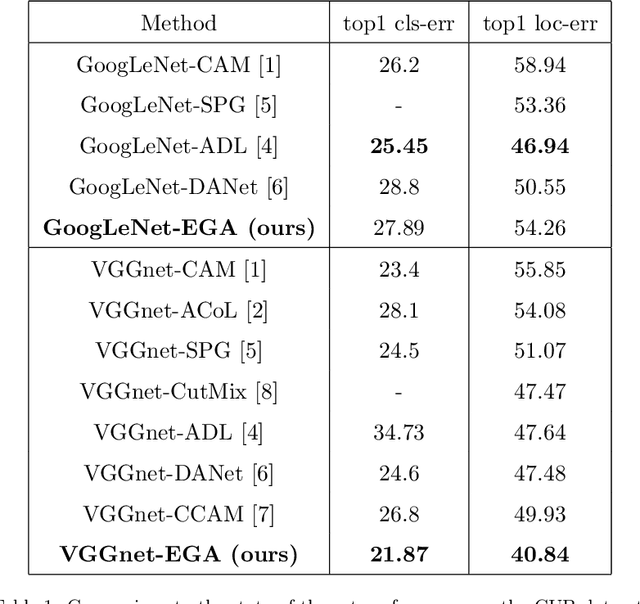

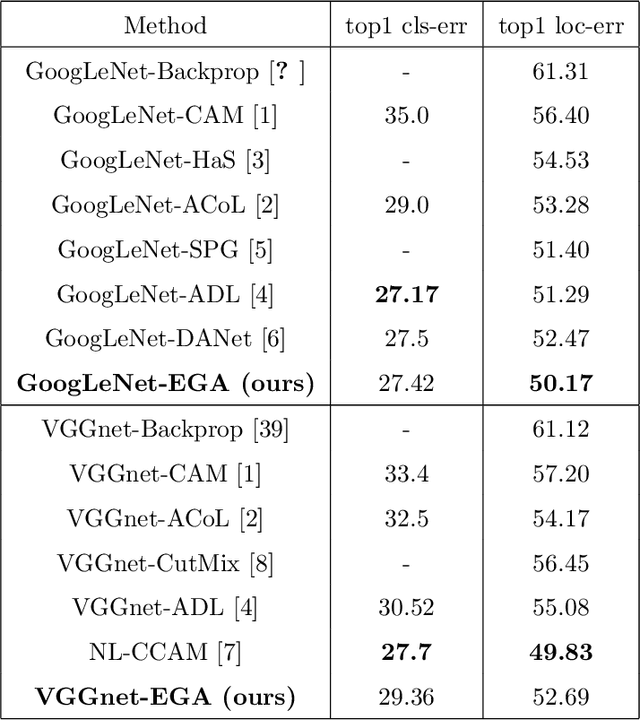
Weakly Supervised Object Localization is challenging because of the lack of bounding box annotations. Previous works tend to generate a class activation map i.e CAM to localize the object. Unfortunately, the network activates only the features that discriminate the object and does not activate the whole object. Some methods tend to remove some parts of the object to force the CNN to detect other features, whereas, others change the network structure to generate multiple CAMs from different levels of the model. In this present article, we propose to take advantage of the generalization ability of the network and train the model using clean examples and adversarial examples to localize the whole object. Adversarial examples are typically used to train robust models and are images where a perturbation is added. To get a good classification accuracy, the CNN trained with adversarial examples is forced to detect more features that discriminate the object. We futher propose to apply the shannon entropy on the CAMs generated by the network to guide it during training. Our method does not erase any part of the image neither does it change the network architecure and extensive experiments show that our Entropy Guided Adversarial model (EGA model) improved performance on state of the arts benchmarks for both localization and classification accuracy.
Single Image Super-Resolution with Dilated Convolution based Multi-Scale Information Learning Inception Module
Jul 22, 2017
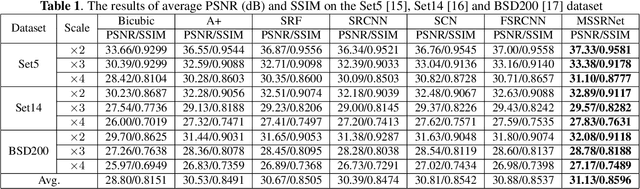


Traditional works have shown that patches in a natural image tend to redundantly recur many times inside the image, both within the same scale, as well as across different scales. Make full use of these multi-scale information can improve the image restoration performance. However, the current proposed deep learning based restoration methods do not take the multi-scale information into account. In this paper, we propose a dilated convolution based inception module to learn multi-scale information and design a deep network for single image super-resolution. Different dilated convolution learns different scale feature, then the inception module concatenates all these features to fuse multi-scale information. In order to increase the reception field of our network to catch more contextual information, we cascade multiple inception modules to constitute a deep network to conduct single image super-resolution. With the novel dilated convolution based inception module, the proposed end-to-end single image super-resolution network can take advantage of multi-scale information to improve image super-resolution performance. Experimental results show that our proposed method outperforms many state-of-the-art single image super-resolution methods.
Deep Networks for Compressed Image Sensing
Jul 22, 2017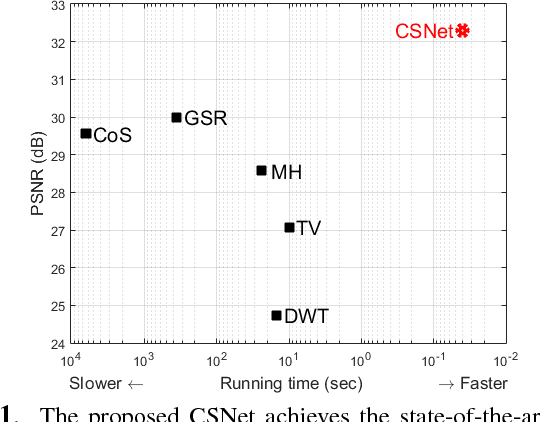
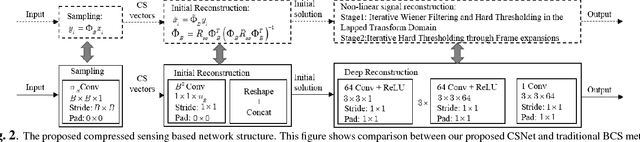

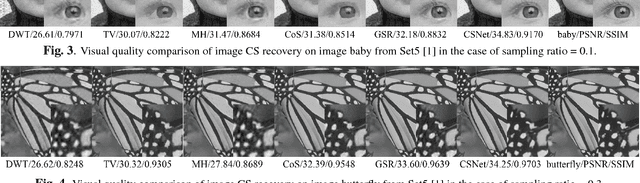
The compressed sensing (CS) theory has been successfully applied to image compression in the past few years as most image signals are sparse in a certain domain. Several CS reconstruction models have been recently proposed and obtained superior performance. However, there still exist two important challenges within the CS theory. The first one is how to design a sampling mechanism to achieve an optimal sampling efficiency, and the second one is how to perform the reconstruction to get the highest quality to achieve an optimal signal recovery. In this paper, we try to deal with these two problems with a deep network. First of all, we train a sampling matrix via the network training instead of using a traditional manually designed one, which is much appropriate for our deep network based reconstruct process. Then, we propose a deep network to recover the image, which imitates traditional compressed sensing reconstruction processes. Experimental results demonstrate that our deep networks based CS reconstruction method offers a very significant quality improvement compared against state of the art ones.