 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Complementary Learning for Weakly Supervised Object Localization
Nov 16, 2020
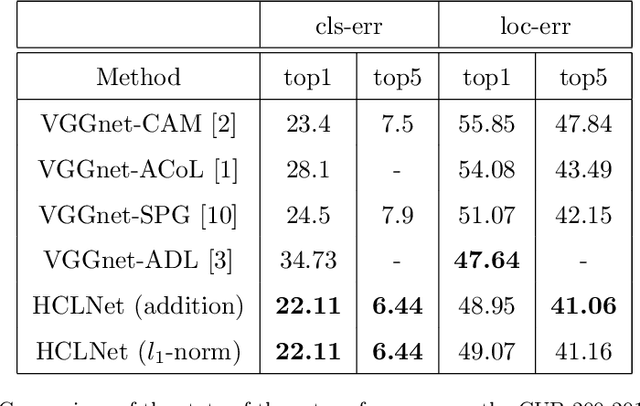

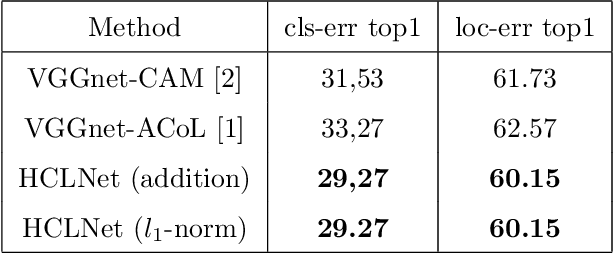
Weakly supervised object localization (WSOL) is a challenging problem which aims to localize objects with only image-level labels. Due to the lack of ground truth bounding boxes, class labels are mainly employed to train the model. This model generates a class activation map (CAM) which activates the most discriminate features. However, the main drawback of CAM is the ability to detect just a part of the object. To solve this problem, some researchers have removed parts from the detected object \cite{b1, b2, b4}, or the image \cite{b3}. The aim of removing parts from image or detected parts of the object is to force the model to detect the other features. However, these methods require one or many hyper-parameters to erase the appropriate pixels on the image, which could involve a loss of information. In contrast, this paper proposes a Hierarchical Complementary Learning Network method (HCLNet) that helps the CNN to perform better classification and localization of objects on the images. HCLNet uses a complementary map to force the network to detect the other parts of the object. Unlike previous works, this method does not need any extras hyper-parameters to generate different CAMs, as well as does not introduce a big loss of information. In order to fuse these different maps, two different fusion strategies known as the addition strategy and the l1-norm strategy have been used. These strategies allowed to detect the whole object while excluding the background. Extensive experiments show that HCLNet obtains better performance than state-of-the-art methods.
Entropy Guided Adversarial Model for Weakly Supervised Object Localization
Aug 04, 2020
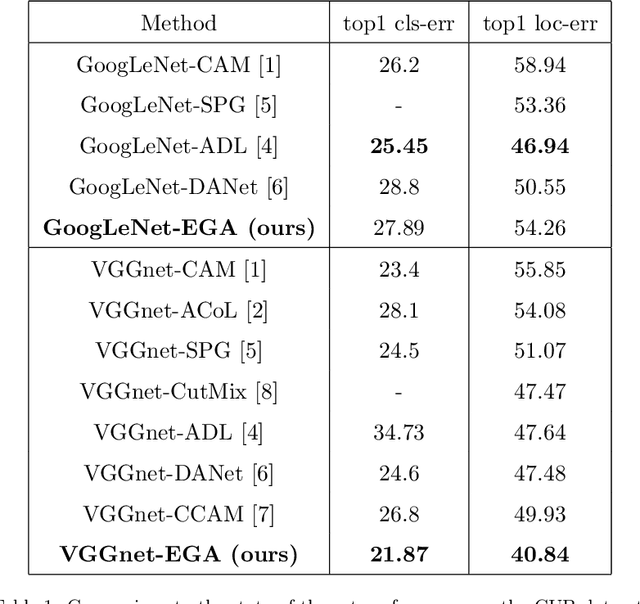

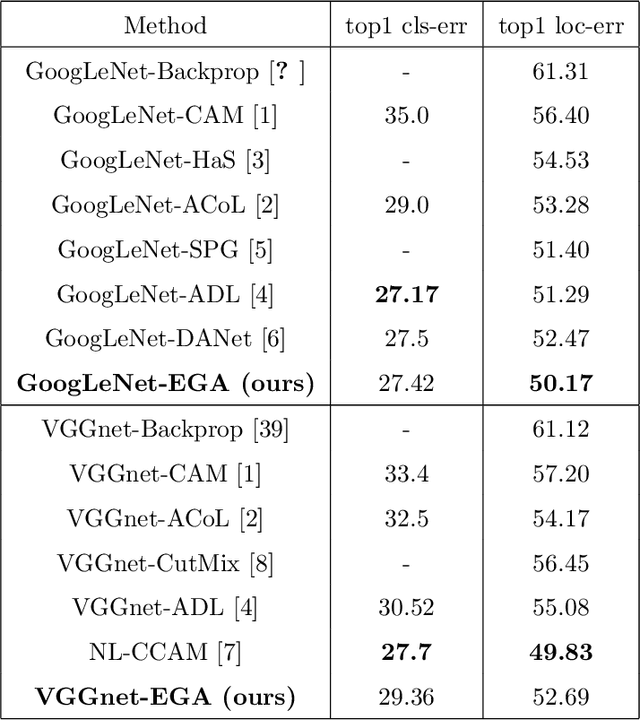
Weakly Supervised Object Localization is challenging because of the lack of bounding box annotations. Previous works tend to generate a class activation map i.e CAM to localize the object. Unfortunately, the network activates only the features that discriminate the object and does not activate the whole object. Some methods tend to remove some parts of the object to force the CNN to detect other features, whereas, others change the network structure to generate multiple CAMs from different levels of the model. In this present article, we propose to take advantage of the generalization ability of the network and train the model using clean examples and adversarial examples to localize the whole object. Adversarial examples are typically used to train robust models and are images where a perturbation is added. To get a good classification accuracy, the CNN trained with adversarial examples is forced to detect more features that discriminate the object. We futher propose to apply the shannon entropy on the CAMs generated by the network to guide it during training. Our method does not erase any part of the image neither does it change the network architecure and extensive experiments show that our Entropy Guided Adversarial model (EGA model) improved performance on state of the arts benchmarks for both localization and classification accuracy.