 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Miner: A Deep and Multi-branch Network which Mines Rich and Diverse Features for Person Re-identification
Feb 18, 2021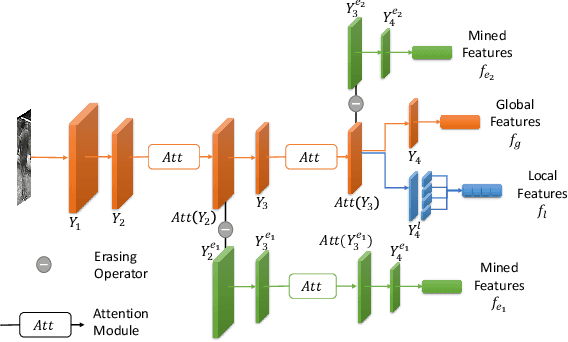
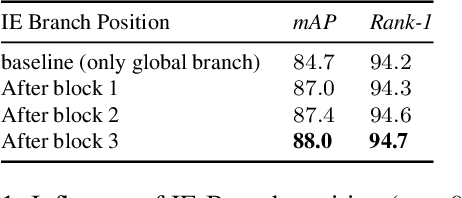

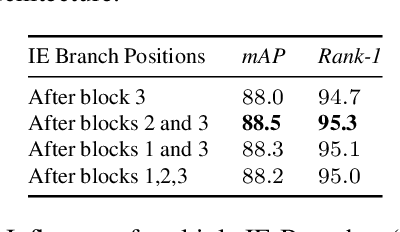
Most recent person re-identification approaches are based on the use of deep convolutional neural networks (CNNs). These networks, although effective in multiple tasks such as classification or object detection, tend to focus on the most discriminative part of an object rather than retrieving all its relevant features. This behavior penalizes the performance of a CNN for the re-identification task, since it should identify diverse and fine grained features. It is then essential to make the network learn a wide variety of finer characteristics in order to make the re-identification process of people effective and robust to finer changes. In this article, we introduce Deep Miner, a method that allows CNNs to "mine" richer and more diverse features about people for their re-identification. Deep Miner is specifically composed of three types of branches: a Global branch (G-branch), a Local branch (L-branch) and an Input-Erased branch (IE-branch). G-branch corresponds to the initial backbone which predicts global characteristics, while L-branch retrieves part level resolution features. The IE-branch for its part, receives partially suppressed feature maps as input thereby allowing the network to "mine" new features (those ignored by G-branch) as output. For this special purpose, a dedicated suppression procedure for identifying and removing features within a given CNN is introduced. This suppression procedure has the major benefit of being simple, while it produces a model that significantly outperforms state-of-the-art (SOTA) re-identification methods. Specifically, we conduct experiments on four standard person re-identification benchmarks and witness an absolute performance gain up to 6.5% mAP compared to SOTA.
PandaNet : Anchor-Based Single-Shot Multi-Person 3D Pose Estimation
Jan 07, 2021



Recently, several deep learning models have been proposed for 3D human pose estimation. Nevertheless, most of these approaches only focus on the single-person case or estimate 3D pose of a few people at high resolution. Furthermore, many applications such as autonomous driving or crowd analysis require pose estimation of a large number of people possibly at low-resolution. In this work, we present PandaNet (Pose estimAtioN and Dectection Anchor-based Network), a new single-shot, anchor-based and multi-person 3D pose estimation approach. The proposed model performs bounding box detection and, for each detected person, 2D and 3D pose regression into a single forward pass. It does not need any post-processing to regroup joints since the network predicts a full 3D pose for each bounding box and allows the pose estimation of a possibly large number of people at low resolution. To manage people overlapping, we introduce a Pose-Aware Anchor Selection strategy. Moreover, as imbalance exists between different people sizes in the image, and joints coordinates have different uncertainties depending on these sizes, we propose a method to automatically optimize weights associated to different people scales and joints for efficient training. PandaNet surpasses previous single-shot methods on several challenging datasets: a multi-person urban virtual but very realistic dataset (JTA Dataset), and two real world 3D multi-person datasets (CMU Panoptic and MuPoTS-3D).
Hierarchical Complementary Learning for Weakly Supervised Object Localization
Nov 16, 2020
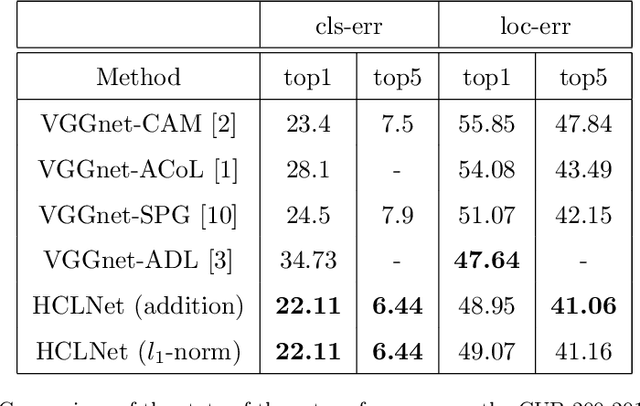

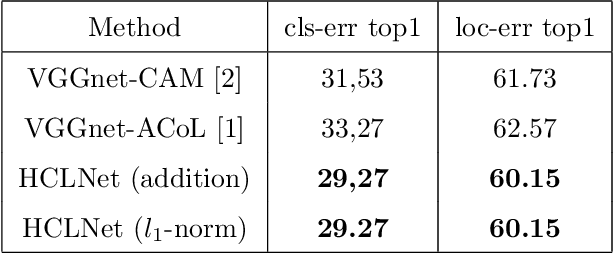
Weakly supervised object localization (WSOL) is a challenging problem which aims to localize objects with only image-level labels. Due to the lack of ground truth bounding boxes, class labels are mainly employed to train the model. This model generates a class activation map (CAM) which activates the most discriminate features. However, the main drawback of CAM is the ability to detect just a part of the object. To solve this problem, some researchers have removed parts from the detected object \cite{b1, b2, b4}, or the image \cite{b3}. The aim of removing parts from image or detected parts of the object is to force the model to detect the other features. However, these methods require one or many hyper-parameters to erase the appropriate pixels on the image, which could involve a loss of information. In contrast, this paper proposes a Hierarchical Complementary Learning Network method (HCLNet) that helps the CNN to perform better classification and localization of objects on the images. HCLNet uses a complementary map to force the network to detect the other parts of the object. Unlike previous works, this method does not need any extras hyper-parameters to generate different CAMs, as well as does not introduce a big loss of information. In order to fuse these different maps, two different fusion strategies known as the addition strategy and the l1-norm strategy have been used. These strategies allowed to detect the whole object while excluding the background. Extensive experiments show that HCLNet obtains better performance than state-of-the-art methods.
Deep, robust and single shot 3D multi-person human pose estimation in complex images
Nov 08, 2019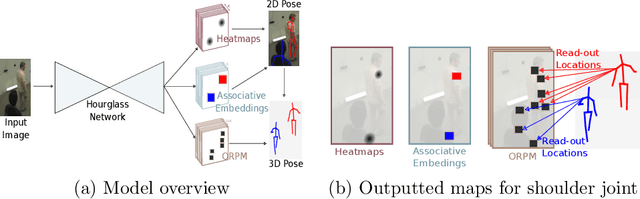
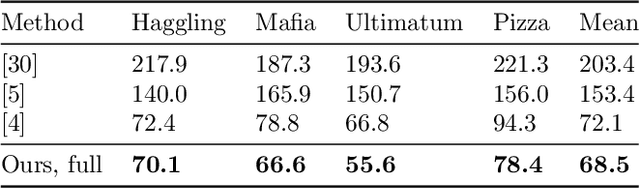

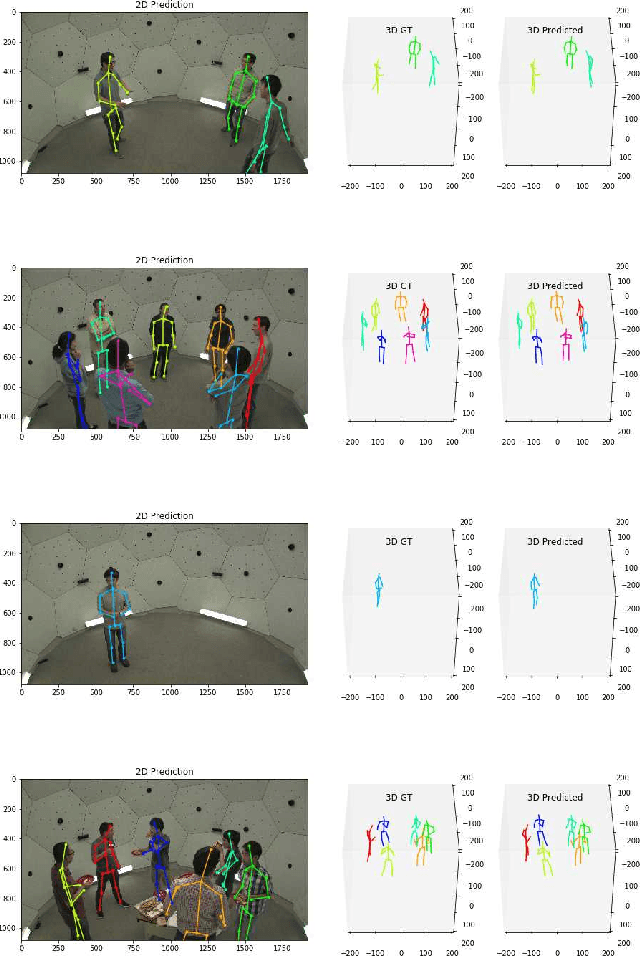
In this paper, we propose a new single shot method for multi-person 3D human pose estimation in complex images. The model jointly learns to locate the human joints in the image, to estimate their 3D coordinates and to group these predictions into full human skeletons. The proposed method deals with a variable number of people and does not need bounding boxes to estimate the 3D poses. It leverages and extends the Stacked Hourglass Network and its multi-scale feature learning to manage multi-person situations. Thus, we exploit a robust 3D human pose formulation to fully describe several 3D human poses even in case of strong occlusions or crops. Then, joint grouping and human pose estimation for an arbitrary number of people are performed using the associative embedding method. Our approach significantly outperforms the state of the art on the challenging CMU Panoptic. Furthermore, it leads to good results on the complex and synthetic images from the newly proposed JTA Dataset.