 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrade-off in Estimating the Number of Byzantine Clients in Federated Learning
Oct 06, 2025

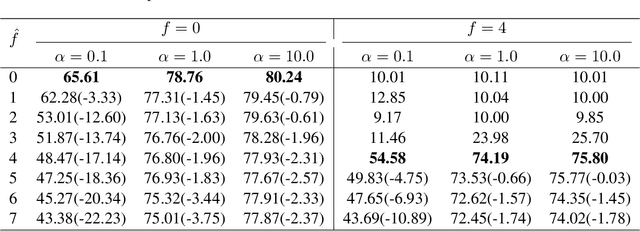

Federated learning has attracted increasing attention at recent large-scale optimization and machine learning research and applications, but is also vulnerable to Byzantine clients that can send any erroneous signals. Robust aggregators are commonly used to resist Byzantine clients. This usually requires to estimate the unknown number $f$ of Byzantine clients, and thus accordingly select the aggregators with proper degree of robustness (i.e., the maximum number $\hat{f}$ of Byzantine clients allowed by the aggregator). Such an estimation should have important effect on the performance, which has not been systematically studied to our knowledge. This work will fill in the gap by theoretically analyzing the worst-case error of aggregators as well as its induced federated learning algorithm for any cases of $\hat{f}$ and $f$. Specifically, we will show that underestimation ($\hat{f}<f$) can lead to arbitrarily poor performance for both aggregators and federated learning. For non-underestimation ($\hat{f}\ge f$), we have proved optimal lower and upper bounds of the same order on the errors of both aggregators and federated learning. All these optimal bounds are proportional to $\hat{f}/(n-f-\hat{f})$ with $n$ clients, which monotonically increases with larger $\hat{f}$. This indicates a fundamental trade-off: while an aggregator with a larger robustness degree $\hat{f}$ can solve federated learning problems of wider range $f\in [0,\hat{f}]$, the performance can deteriorate when there are actually fewer or even no Byzantine clients (i.e., $f\in [0,\hat{f})$).
RubikSQL: Lifelong Learning Agentic Knowledge Base as an Industrial NL2SQL System
Aug 25, 2025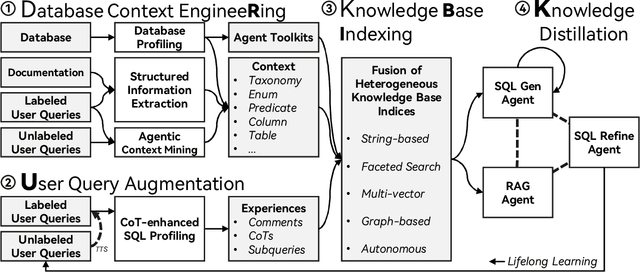
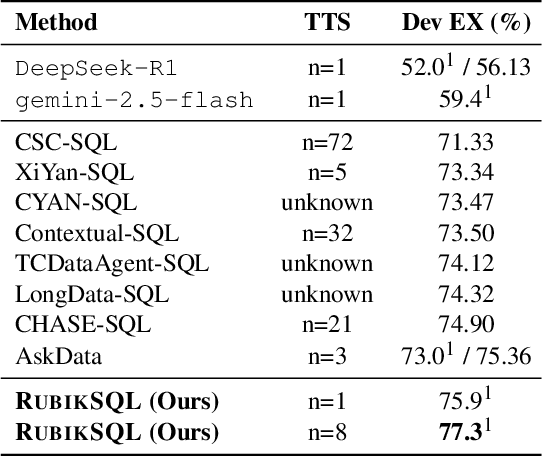
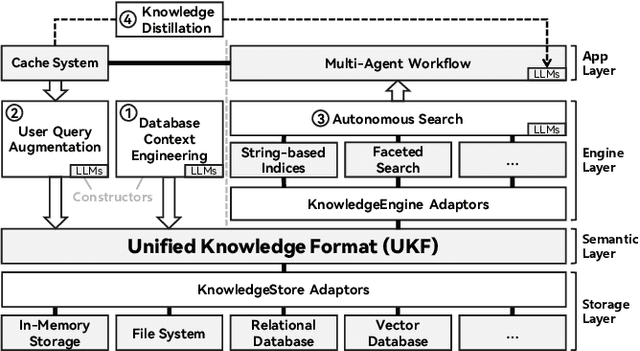
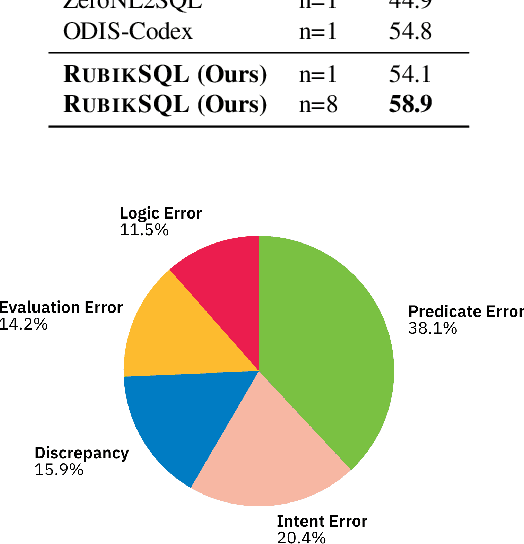
We present RubikSQL, a novel NL2SQL system designed to address key challenges in real-world enterprise-level NL2SQL, such as implicit intents and domain-specific terminology. RubikSQL frames NL2SQL as a lifelong learning task, demanding both Knowledge Base (KB) maintenance and SQL generation. RubikSQL systematically builds and refines its KB through techniques including database profiling, structured information extraction, agentic rule mining, and Chain-of-Thought (CoT)-enhanced SQL profiling. RubikSQL then employs a multi-agent workflow to leverage this curated KB, generating accurate SQLs. RubikSQL achieves SOTA performance on both the KaggleDBQA and BIRD Mini-Dev datasets. Finally, we release the RubikBench benchmark, a new benchmark specifically designed to capture vital traits of industrial NL2SQL scenarios, providing a valuable resource for future research.
FlamePINN-1D: Physics-informed neural networks to solve forward and inverse problems of 1D laminar flames
Jun 07, 2024Given the existence of various forward and inverse problems in combustion studies and applications that necessitate distinct methods for resolution, a framework to solve them in a unified way is critically needed. A promising approach is the integration of machine learning methods with governing equations of combustion systems, which exhibits superior generality and few-shot learning ability compared to purely data-driven methods. In this work, the FlamePINN-1D framework is proposed to solve the forward and inverse problems of 1D laminar flames based on physics-informed neural networks. Three cases with increasing complexity have been tested: Case 1 are freely-propagating premixed (FPP) flames with simplified physical models, while Case 2 and Case 3 are FPP and counterflow premixed (CFP) flames with detailed models, respectively. For forward problems, FlamePINN-1D aims to solve the flame fields and infer the unknown eigenvalues (such as laminar flame speeds) under the constraints of governing equations and boundary conditions. For inverse problems, FlamePINN-1D aims to reconstruct the continuous fields and infer the unknown parameters (such as transport and chemical kinetics parameters) from noisy sparse observations of the flame. Our results strongly validate these capabilities of FlamePINN-1D across various flames and working conditions. Compared to traditional methods, FlamePINN-1D is differentiable and mesh-free, exhibits no discretization errors, and is easier to implement for inverse problems. The inverse problem results also indicate the possibility of optimizing chemical mechanisms from measurements of laboratory 1D flames. Furthermore, some proposed strategies, such as hard constraints and thin-layer normalization, are proven to be essential for the robust learning of FlamePINN-1D. The code for this paper is partially available at https://github.com/CAME-THU/FlamePINN-1D.
MASA-TCN: Multi-anchor Space-aware Temporal Convolutional Neural Networks for Continuous and Discrete EEG Emotion Recognition
Aug 30, 2023
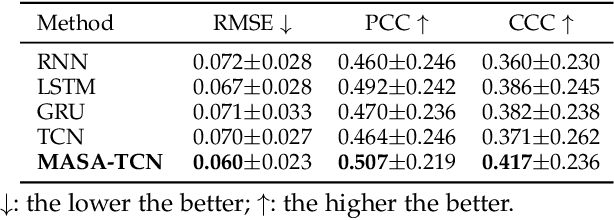

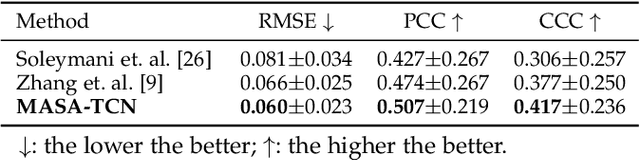
Emotion recognition using electroencephalogram (EEG) mainly has two scenarios: classification of the discrete labels and regression of the continuously tagged labels. Although many algorithms were proposed for classification tasks, there are only a few methods for regression tasks. For emotion regression, the label is continuous in time. A natural method is to learn the temporal dynamic patterns. In previous studies, long short-term memory (LSTM) and temporal convolutional neural networks (TCN) were utilized to learn the temporal contextual information from feature vectors of EEG. However, the spatial patterns of EEG were not effectively extracted. To enable the spatial learning ability of TCN towards better regression and classification performances, we propose a novel unified model, named MASA-TCN, for EEG emotion regression and classification tasks. The space-aware temporal layer enables TCN to additionally learn from spatial relations among EEG electrodes. Besides, a novel multi-anchor block with attentive fusion is proposed to learn dynamic temporal dependencies. Experiments on two publicly available datasets show MASA-TCN achieves higher results than the state-of-the-art methods for both EEG emotion regression and classification tasks. The code is available at https://github.com/yi-ding-cs/MASA-TCN.
Multimodal Continuous Emotion Recognition: A Technical Report for ABAW5
Mar 18, 2023


We used two multimodal models for continuous valence-arousal recognition using visual, audio, and linguistic information. The first model is the same as we used in ABAW2 and ABAW3, which employs the leader-follower attention. The second model has the same architecture for spatial and temporal encoding. As for the fusion block, it employs a compact and straightforward channel attention, borrowed from the End2You toolkit. Unlike our previous attempts that use Vggish feature directly as the audio feature, this time we feed the pre-trained VGG model using logmel-spectrogram and finetune it during the training. To make full use of the data and alleviate over-fitting, cross-validation is carried out. The fold with the highest concordance correlation coefficient is selected for submission. The code is to be available at https://github.com/sucv/ABAW5.
Continuous Emotion Recognition using Visual-audio-linguistic information: A Technical Report for ABAW3
Mar 30, 2022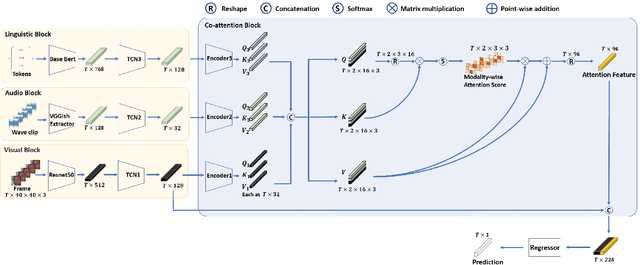
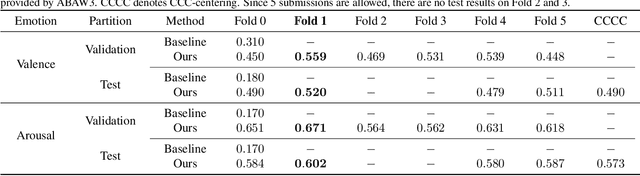
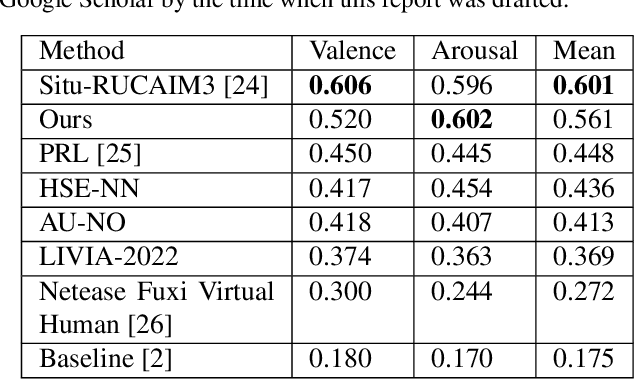
We propose a cross-modal co-attention model for continuous emotion recognition using visual-audio-linguistic information. The model consists of four blocks. The visual, audio, and linguistic blocks are used to learn the spatial-temporal features of the multi-modal input. A co-attention block is designed to fuse the learned features with the multi-head co-attention mechanism. The visual encoding from the visual block is concatenated with the attention feature to emphasize the visual information. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. The achieved CCC on the test set is $0.520$ for valence and $0.602$ for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.180 and 0.170 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW3.
Audio-visual Attentive Fusion for Continuous Emotion Recognition
Jul 09, 2021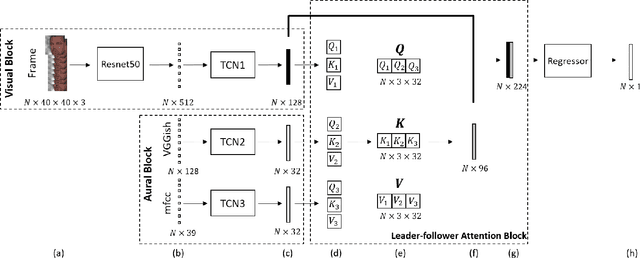
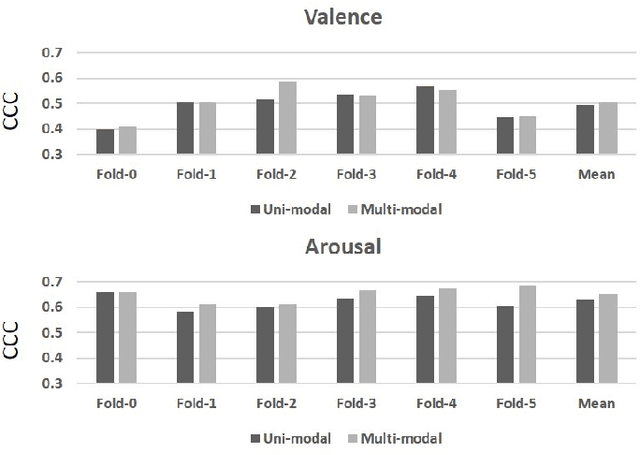
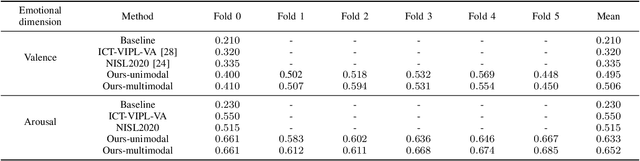
We propose an audio-visual spatial-temporal deep neural network with: (1) a visual block containing a pretrained 2D-CNN followed by a temporal convolutional network (TCN); (2) an aural block containing several parallel TCNs; and (3) a leader-follower attentive fusion block combining the audio-visual information. The TCN with large history coverage enables our model to exploit spatial-temporal information within a much larger window length (i.e., 300) than that from the baseline and state-of-the-art methods (i.e., 36 or 48). The fusion block emphasizes the visual modality while exploits the noisy aural modality using the inter-modality attention mechanism. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. On the development set, the achieved CCC is 0.469 for valence and 0.649 for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.210 and 0.230 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW2.