 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASA-TCN: Multi-anchor Space-aware Temporal Convolutional Neural Networks for Continuous and Discrete EEG Emotion Recognition
Aug 30, 2023
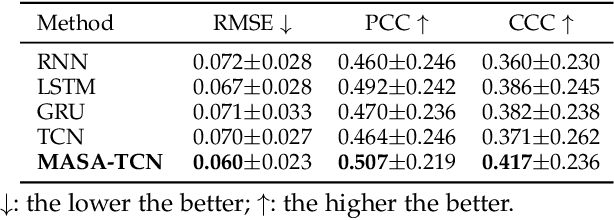

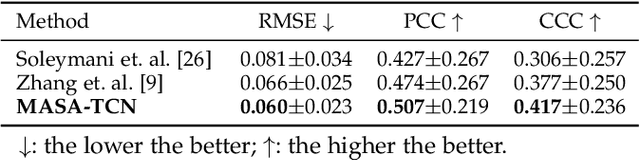
Emotion recognition using electroencephalogram (EEG) mainly has two scenarios: classification of the discrete labels and regression of the continuously tagged labels. Although many algorithms were proposed for classification tasks, there are only a few methods for regression tasks. For emotion regression, the label is continuous in time. A natural method is to learn the temporal dynamic patterns. In previous studies, long short-term memory (LSTM) and temporal convolutional neural networks (TCN) were utilized to learn the temporal contextual information from feature vectors of EEG. However, the spatial patterns of EEG were not effectively extracted. To enable the spatial learning ability of TCN towards better regression and classification performances, we propose a novel unified model, named MASA-TCN, for EEG emotion regression and classification tasks. The space-aware temporal layer enables TCN to additionally learn from spatial relations among EEG electrodes. Besides, a novel multi-anchor block with attentive fusion is proposed to learn dynamic temporal dependencies. Experiments on two publicly available datasets show MASA-TCN achieves higher results than the state-of-the-art methods for both EEG emotion regression and classification tasks. The code is available at https://github.com/yi-ding-cs/MASA-TCN.
SDFE-LV: A Large-Scale, Multi-Source, and Unconstrained Database for Spotting Dynamic Facial Expressions in Long Videos
Sep 18, 2022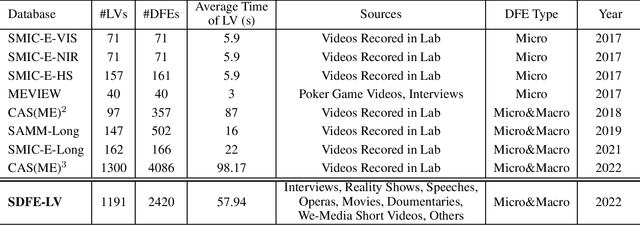
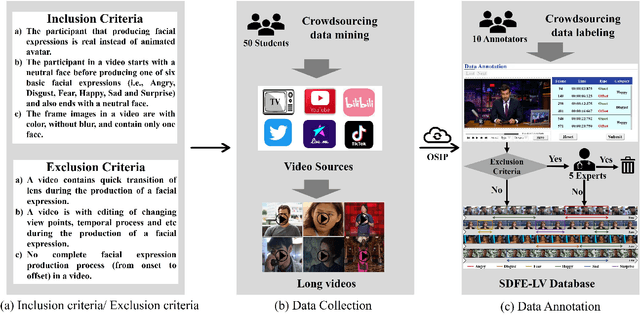
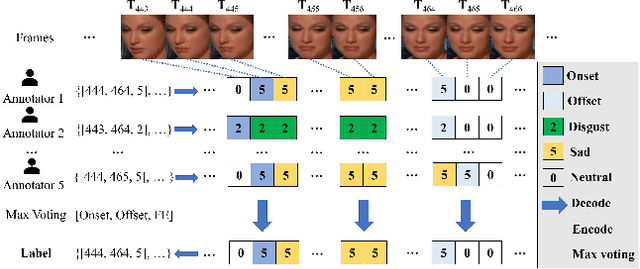

In this paper, we present a large-scale, multi-source, and unconstrained database called SDFE-LV for spotting the onset and offset frames of a complete dynamic facial expression from long videos, which is known as the topic of dynamic facial expression spotting (DFES) and a vital prior step for lots of facial expression analysis tasks. Specifically, SDFE-LV consists of 1,191 long videos, each of which contains one or more complete dynamic facial expressions. Moreover, each complete dynamic facial expression in its corresponding long video was independently labeled for five times by 10 well-trained annotators. To the best of our knowledge, SDFE-LV is the first unconstrained large-scale database for the DFES task whose long videos are collected from multiple real-world/closely real-world media sources, e.g., TV interviews, documentaries, movies, and we-media short videos. Therefore, DFES tasks on SDFE-LV database will encounter numerous difficulties in practice such as head posture changes, occlusions, and illumination. We also provided a comprehensive benchmark evaluation from different angles by using lots of recent state-of-the-art deep spotting methods and hence researchers interested in DFES can quickly and easily get started. Finally, with the deep discussions on the experimental evaluation results, we attempt to point out several meaningful directions to deal with DFES tasks and hope that DFES can be better advanced in the future. In addition, SDFE-LV will be freely released for academic use only as soon as possible.
DFEW: A Large-Scale Database for Recognizing Dynamic Facial Expressions in the Wild
Aug 13, 2020
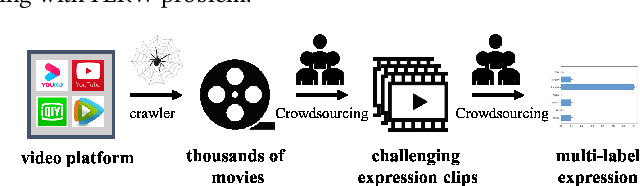

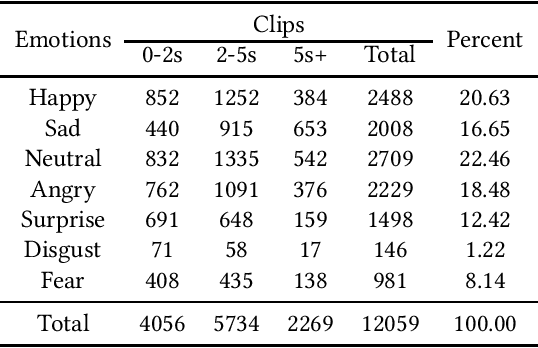
Recently, facial expression recognition (FER) in the wild has gained a lot of researchers' attention because it is a valuable topic to enable the FER techniques to move from the laboratory to the real applications. In this paper, we focus on this challenging but interesting topic and make contributions from three aspects. First, we present a new large-scale 'in-the-wild' dynamic facial expression database, DFEW (Dynamic Facial Expression in the Wild), consisting of over 16,000 video clips from thousands of movies. These video clips contain various challenging interferences in practical scenarios such as extreme illumination, occlusions, and capricious pose changes. Second, we propose a novel method called Expression-Clustered Spatiotemporal Feature Learning (EC-STFL) framework to deal with dynamic FER in the wild. Third, we conduct extensive benchmark experiments on DFEW using a lot of spatiotemporal deep feature learning methods as well as our proposed EC-STFL. Experimental results show that DFEW is a well-designed and challenging database, and the proposed EC-STFL can promisingly improve the performance of existing spatiotemporal deep neural networks in coping with the problem of dynamic FER in the wild. Our DFEW database is publicly available and can be freely downloaded from https://dfew-dataset.github.io/.
Cross-Database Micro-Expression Recognition: A Benchmark
Dec 19, 2018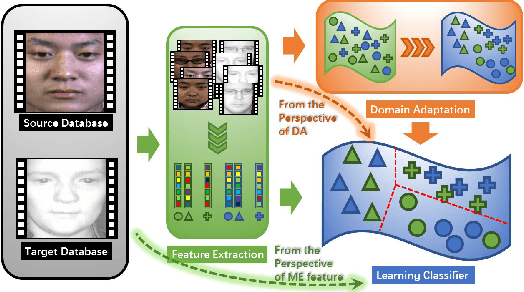
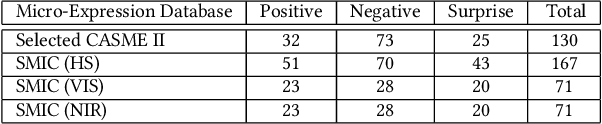
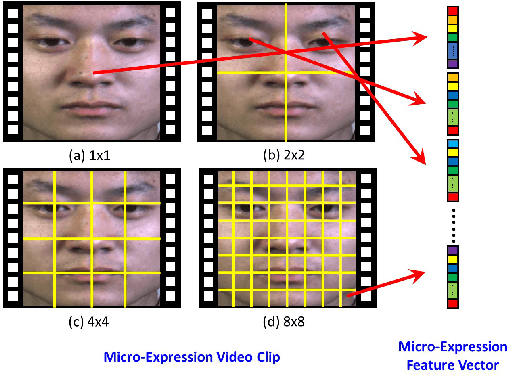
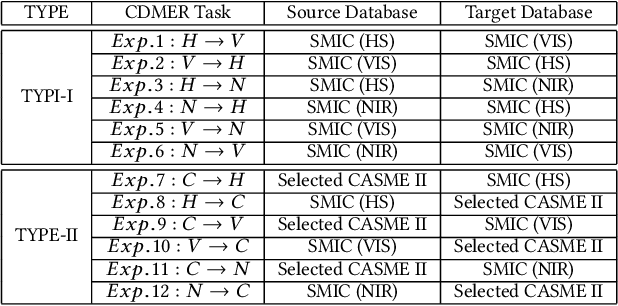
Cross-database micro-expression recognition (CDMER) is one of recently emerging and interesting problem in micro-expression analysis. CDMER is more challenging than the conventional micro-expression recognition (MER), because the training and testing samples in CDMER come from different micro-expression databases, resulting in the inconsistency of the feature distributions between the training and testing sets. In this paper, we contribute to this topic from three aspects. First, we establish a CDMER experimental evaluation protocol aiming to allow the researchers to conveniently work on this topic and provide a standard platform for evaluating their proposed methods. Second, we conduct benchmark experiments by using NINE state-of-the-art domain adaptation (DA) methods and SIX popular spatiotemporal descriptors for respectively investigating CDMER problem from two different perspectives. Third, we propose a novel DA method called region selective transfer regression (RSTR) to deal with the CDMER task. Our RSTR takes advantage of one important cue for recognizing micro-expressions, i.e., the different contributions of the facial local regions in MER. The overall superior performance of RSTR demonstrates that taking into consideration the important cues benefiting MER, e.g., the facial local region information, contributes to develop effective DA methods for dealing with CDMER problem.