 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDFE-LV: A Large-Scale, Multi-Source, and Unconstrained Database for Spotting Dynamic Facial Expressions in Long Videos
Paper and Code
Sep 18, 2022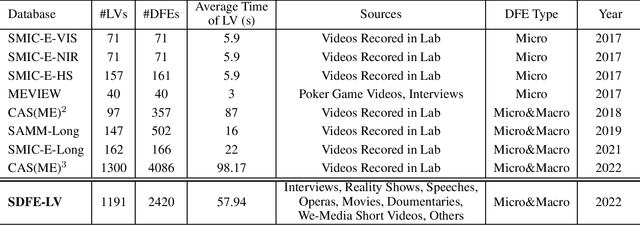
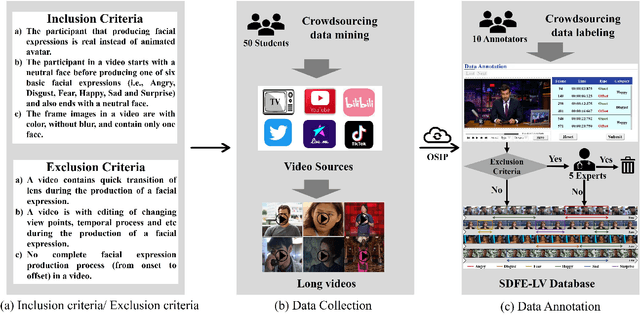
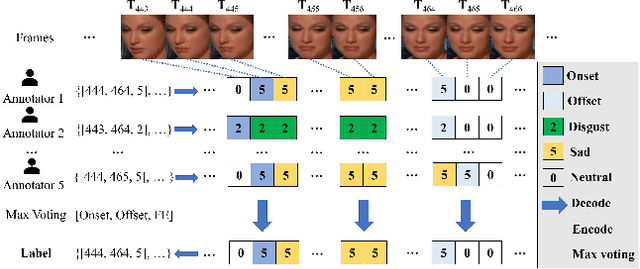

In this paper, we present a large-scale, multi-source, and unconstrained database called SDFE-LV for spotting the onset and offset frames of a complete dynamic facial expression from long videos, which is known as the topic of dynamic facial expression spotting (DFES) and a vital prior step for lots of facial expression analysis tasks. Specifically, SDFE-LV consists of 1,191 long videos, each of which contains one or more complete dynamic facial expressions. Moreover, each complete dynamic facial expression in its corresponding long video was independently labeled for five times by 10 well-trained annotators. To the best of our knowledge, SDFE-LV is the first unconstrained large-scale database for the DFES task whose long videos are collected from multiple real-world/closely real-world media sources, e.g., TV interviews, documentaries, movies, and we-media short videos. Therefore, DFES tasks on SDFE-LV database will encounter numerous difficulties in practice such as head posture changes, occlusions, and illumination. We also provided a comprehensive benchmark evaluation from different angles by using lots of recent state-of-the-art deep spotting methods and hence researchers interested in DFES can quickly and easily get started. Finally, with the deep discussions on the experimental evaluation results, we attempt to point out several meaningful directions to deal with DFES tasks and hope that DFES can be better advanced in the future. In addition, SDFE-LV will be freely released for academic use only as soon as possible.