 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual Attentive Fusion for Continuous Emotion Recognition
Paper and Code
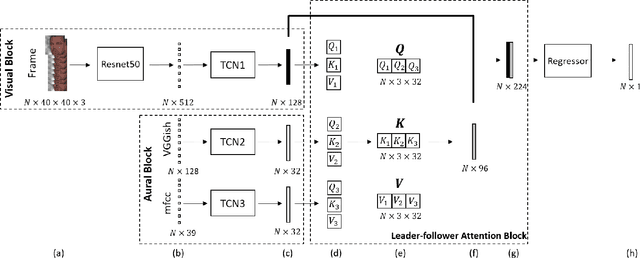
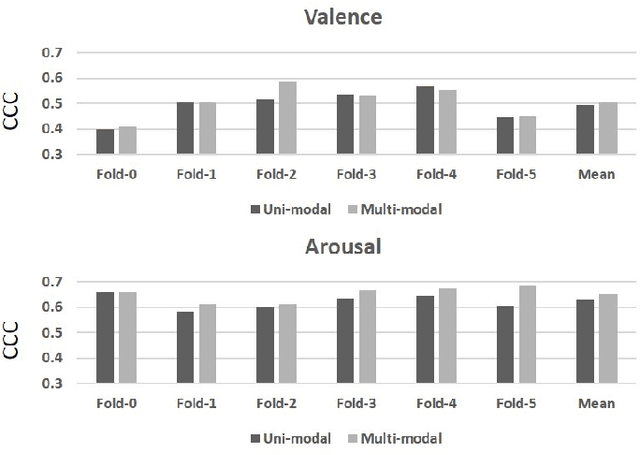
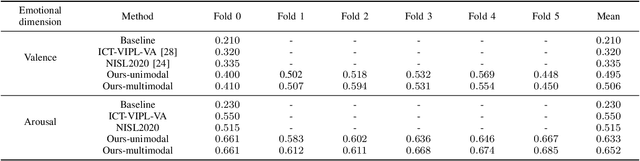
We propose an audio-visual spatial-temporal deep neural network with: (1) a visual block containing a pretrained 2D-CNN followed by a temporal convolutional network (TCN); (2) an aural block containing several parallel TCNs; and (3) a leader-follower attentive fusion block combining the audio-visual information. The TCN with large history coverage enables our model to exploit spatial-temporal information within a much larger window length (i.e., 300) than that from the baseline and state-of-the-art methods (i.e., 36 or 48). The fusion block emphasizes the visual modality while exploits the noisy aural modality using the inter-modality attention mechanism. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. On the development set, the achieved CCC is 0.469 for valence and 0.649 for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.210 and 0.230 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW2.