 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroPath: A Neural Pathway Transformer for Joining the Dots of Human Connectomes
Sep 26, 2024
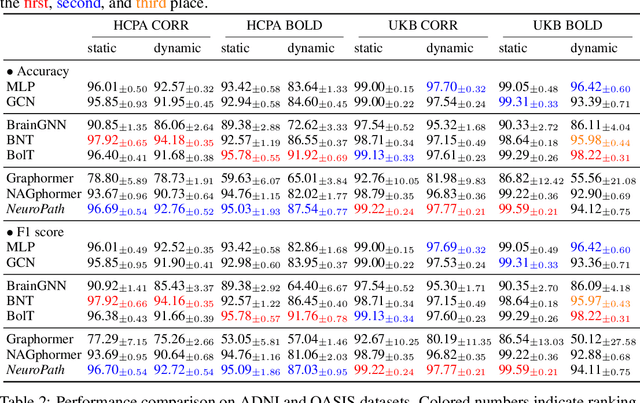

Although modern imaging technologies allow us to study connectivity between two distinct brain regions in-vivo, an in-depth understanding of how anatomical structure supports brain function and how spontaneous functional fluctuations emerge remarkable cognition is still elusive. Meanwhile, tremendous efforts have been made in the realm of machine learning to establish the nonlinear mapping between neuroimaging data and phenotypic traits. However, the absence of neuroscience insight in the current approaches poses significant challenges in understanding cognitive behavior from transient neural activities. To address this challenge, we put the spotlight on the coupling mechanism of structural connectivity (SC) and functional connectivity (FC) by formulating such network neuroscience question into an expressive graph representation learning problem for high-order topology. Specifically, we introduce the concept of topological detour to characterize how a ubiquitous instance of FC (direct link) is supported by neural pathways (detour) physically wired by SC, which forms a cyclic loop interacted by brain structure and function. In the clich\'e of machine learning, the multi-hop detour pathway underlying SC-FC coupling allows us to devise a novel multi-head self-attention mechanism within Transformer to capture multi-modal feature representation from paired graphs of SC and FC. Taken together, we propose a biological-inspired deep model, coined as NeuroPath, to find putative connectomic feature representations from the unprecedented amount of neuroimages, which can be plugged into various downstream applications such as task recognition and disease diagnosis. We have evaluated NeuroPath on large-scale public datasets including HCP and UK Biobank under supervised and zero-shot learning, where the state-of-the-art performance by our NeuroPath indicates great potential in network neuroscience.
Machine Learning on Dynamic Functional Connectivity: Promise, Pitfalls, and Interpretations
Sep 17, 2024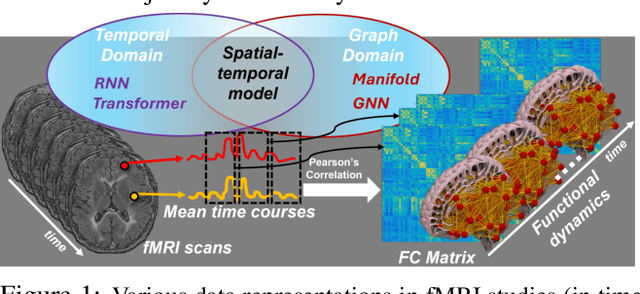
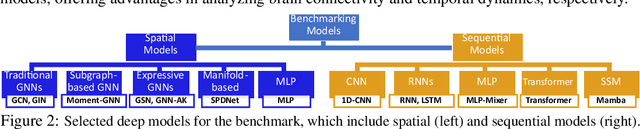
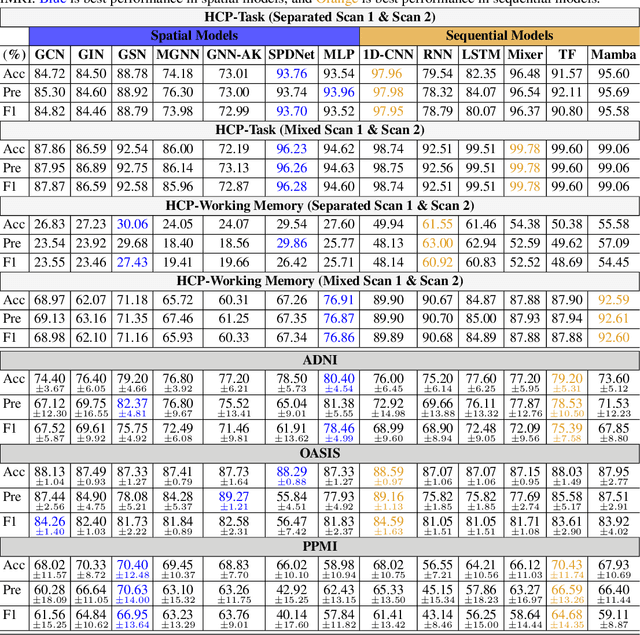
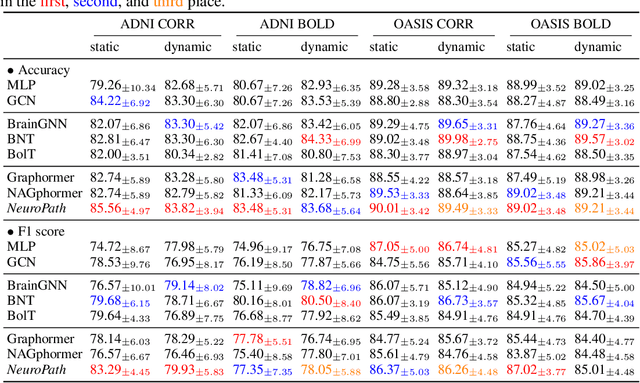
An unprecedented amount of existing functional Magnetic Resonance Imaging (fMRI) data provides a new opportunity to understand the relationship between functional fluctuation and human cognition/behavior using a data-driven approach. To that end, tremendous efforts have been made in machine learning to predict cognitive states from evolving volumetric images of blood-oxygen-level-dependent (BOLD) signals. Due to the complex nature of brain function, however, the evaluation on learning performance and discoveries are not often consistent across current state-of-the-arts (SOTA). By capitalizing on large-scale existing neuroimaging data (34,887 data samples from six public databases), we seek to establish a well-founded empirical guideline for designing deep models for functional neuroimages by linking the methodology underpinning with knowledge from the neuroscience domain. Specifically, we put the spotlight on (1) What is the current SOTA performance in cognitive task recognition and disease diagnosis using fMRI? (2) What are the limitations of current deep models? and (3) What is the general guideline for selecting the suitable machine learning backbone for new neuroimaging applications? We have conducted a comprehensive evaluation and statistical analysis, in various settings, to answer the above outstanding questions.
Message Detouring: A Simple Yet Effective Cycle Representation for Expressive Graph Learning
Feb 12, 2024



Graph learning is crucial in the fields of bioinformatics, social networks, and chemicals. Although high-order graphlets, such as cycles, are critical to achieving an informative graph representation for node classification, edge prediction, and graph recognition, modeling high-order topological characteristics poses significant computational challenges, restricting its widespread applications in machine learning. To address this limitation, we introduce the concept of \textit{message detouring} to hierarchically characterize cycle representation throughout the entire graph, which capitalizes on the contrast between the shortest and longest pathways within a range of local topologies associated with each graph node. The topological feature representations derived from our message detouring landscape demonstrate comparable expressive power to high-order \textit{Weisfeiler-Lehman} (WL) tests but much less computational demands. In addition to the integration with graph kernel and message passing neural networks, we present a novel message detouring neural network, which uses Transformer backbone to integrate cycle representations across nodes and edges. Aside from theoretical results, experimental results on expressiveness, graph classification, and node classification show message detouring can significantly outperform current counterpart approaches on various benchmark datasets.
Re-Think and Re-Design Graph Neural Networks in Spaces of Continuous Graph Diffusion Functionals
Jul 01, 2023



Graph neural networks (GNNs) are widely used in domains like social networks and biological systems. However, the locality assumption of GNNs, which limits information exchange to neighboring nodes, hampers their ability to capture long-range dependencies and global patterns in graphs. To address this, we propose a new inductive bias based on variational analysis, drawing inspiration from the Brachistochrone problem. Our framework establishes a mapping between discrete GNN models and continuous diffusion functionals. This enables the design of application-specific objective functions in the continuous domain and the construction of discrete deep models with mathematical guarantees. To tackle over-smoothing in GNNs, we analyze the existing layer-by-layer graph embedding models and identify that they are equivalent to l2-norm integral functionals of graph gradients, which cause over-smoothing. Similar to edge-preserving filters in image denoising, we introduce total variation (TV) to align the graph diffusion pattern with global community topologies. Additionally, we devise a selective mechanism to address the trade-off between model depth and over-smoothing, which can be easily integrated into existing GNNs. Furthermore, we propose a novel generative adversarial network (GAN) that predicts spreading flows in graphs through a neural transport equation. To mitigate vanishing flows, we customize the objective function to minimize transportation within each community while maximizing inter-community flows. Our GNN models achieve state-of-the-art (SOTA) performance on popular graph learning benchmarks such as Cora, Citeseer, and Pubmed.
Cervical Glandular Cell Detection from Whole Slide Image with Out-Of-Distribution Data
Jun 01, 2022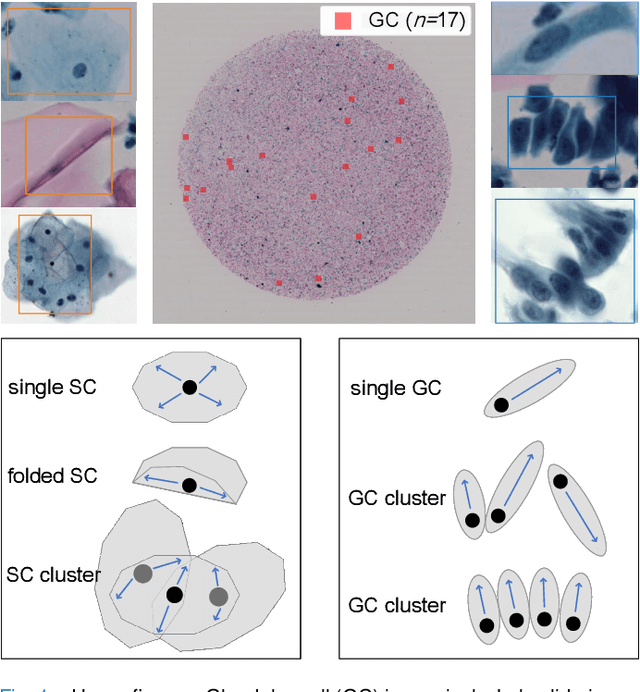
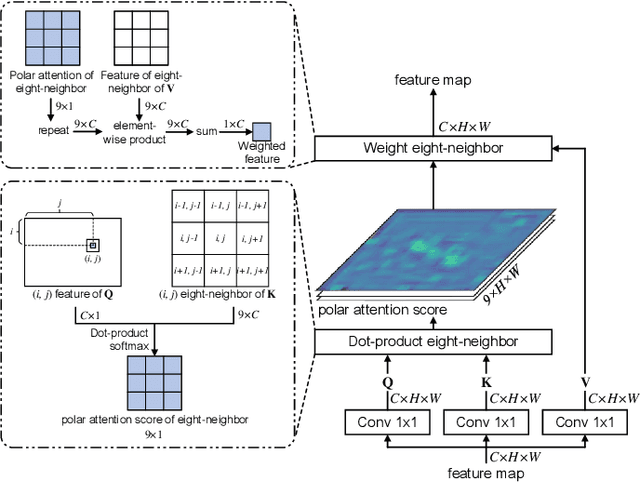
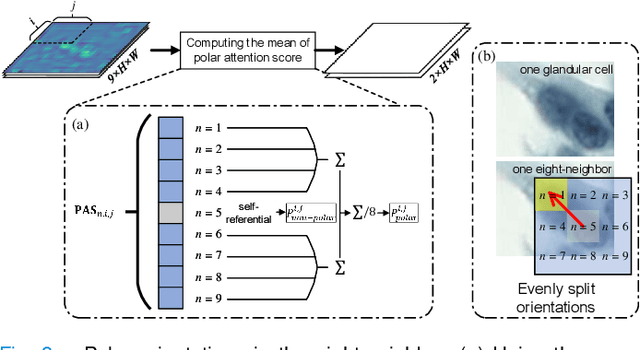
Cervical glandular cell (GC) detection is a key step in computer-aided diagnosis for cervical adenocarcinomas screening. It is challenging to accurately recognize GCs in cervical smears in which squamous cells are the major. Widely existing Out-Of-Distribution (OOD) data in the entire smear leads decreasing reliability of machine learning system for GC detection. Although, the State-Of-The-Art (SOTA) deep learning model can outperform pathologists in preselected regions of interest, the mass False Positive (FP) prediction with high probability is still unsolved when facing such gigapixel whole slide image. This paper proposed a novel PolarNet based on the morphological prior knowledge of GC trying to solve the FP problem via a self-attention mechanism in eight-neighbor. It estimates the polar orientation of nucleus of GC. As a plugin module, PolarNet can guide the deep feature and predicted confidence of general object detection models. In experiments, we discovered that general models based on four different frameworks can reject FP in small image set and increase the mean of average precision (mAP) by $\text{0.007}\sim\text{0.015}$ in average, where the highest exceeds the recent cervical cell detection model 0.037. By plugging PolarNet, the deployed C++ program improved by 8.8\% on accuracy of top-20 GC detection from external WSIs, while sacrificing 14.4 s of computational time. Code is available in https://github.com/Chrisa142857/PolarNet-GCdet
Audio-visual Attentive Fusion for Continuous Emotion Recognition
Jul 09, 2021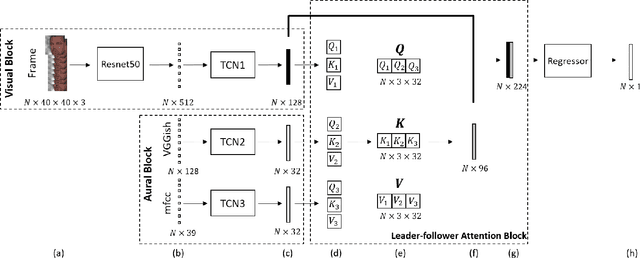
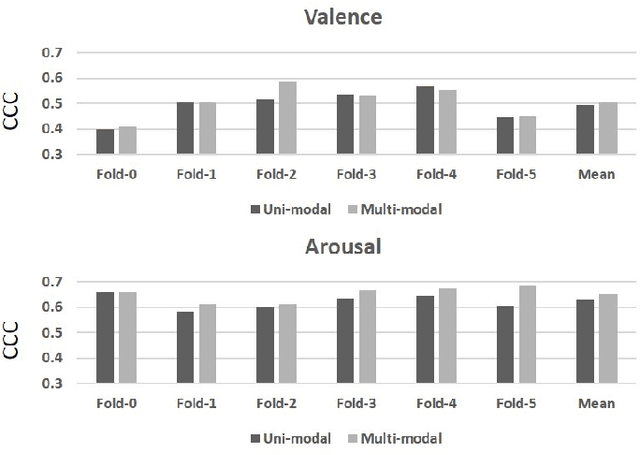
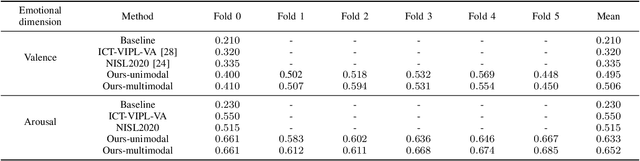
We propose an audio-visual spatial-temporal deep neural network with: (1) a visual block containing a pretrained 2D-CNN followed by a temporal convolutional network (TCN); (2) an aural block containing several parallel TCNs; and (3) a leader-follower attentive fusion block combining the audio-visual information. The TCN with large history coverage enables our model to exploit spatial-temporal information within a much larger window length (i.e., 300) than that from the baseline and state-of-the-art methods (i.e., 36 or 48). The fusion block emphasizes the visual modality while exploits the noisy aural modality using the inter-modality attention mechanism. To make full use of the data and alleviate over-fitting, cross-validation is carried out on the training and validation set. The concordance correlation coefficient (CCC) centering is used to merge the results from each fold. On the development set, the achieved CCC is 0.469 for valence and 0.649 for arousal, which significantly outperforms the baseline method with the corresponding CCC of 0.210 and 0.230 for valence and arousal, respectively. The code is available at https://github.com/sucv/ABAW2.
An Efficient Cervical Whole Slide Image Analysis Framework Based on Multi-scale Semantic and Spatial Deep Features
Jul 03, 2021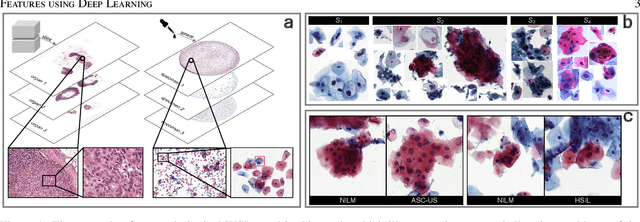
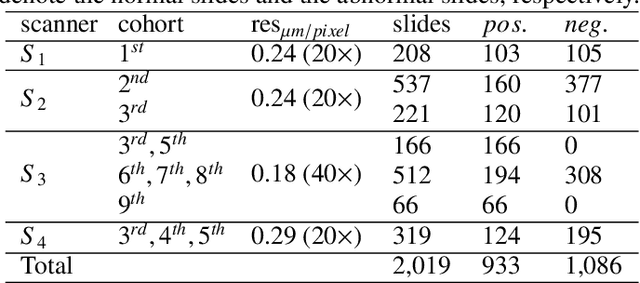
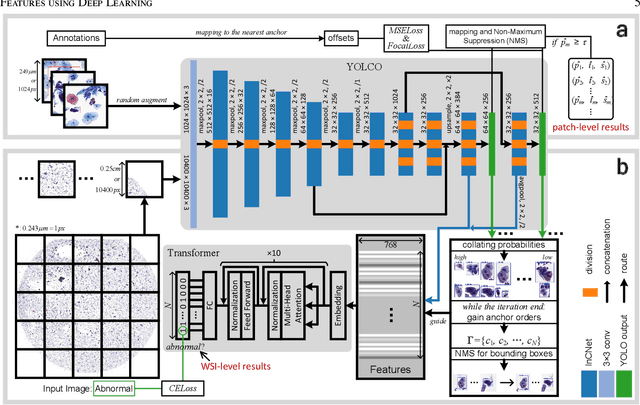
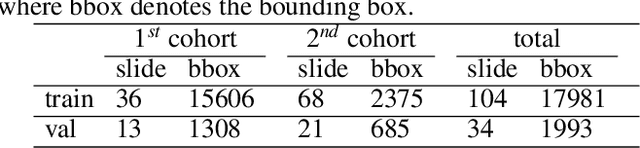
Digital gigapixel whole slide image (WSI) is widely used in clinical diagnosis, and automated WSI analysis is key for computer-aided diagnosis. Currently, analyzing the integrated descriptor of probabilities or feature maps from massive local patches encoded by ResNet classifier is the main manner for WSI-level prediction. Feature representations of the sparse and tiny lesion cells in cervical slides, however, are still challengeable for the under-promoted upstream encoders, while the unused spatial representations of cervical cells are the available features to supply the semantics analysis. As well as patches sampling with overlap and repetitive processing incur the inefficiency and the unpredictable side effect. This study designs a novel inline connection network (InCNet) by enriching the multi-scale connectivity to build the lightweight model named You Only Look Cytopathology Once (YOLCO) with the additional supervision of spatial information. The proposed model allows the input size enlarged to megapixel that can stitch the WSI without any overlap by the average repeats decreased from $10^3\sim10^4$ to $10^1\sim10^2$ for collecting features and predictions at two scales. Based on Transformer for classifying the integrated multi-scale multi-task features, the experimental results appear $0.872$ AUC score better and $2.51\times$ faster than the best conventional method in WSI classification on multicohort datasets of 2,019 slides from four scanning devices.